溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何分析Flink源碼閱讀環境搭建并調試Flink-Clients模塊,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
讀文檔和讀源碼的目的是不一樣的,就拿 Apache Flink 這個項目來說,如果你想知道 Flink 的使用功能,設計思想,實現原理,看官方文檔就足夠了;如果你想了解的就是具體細節,比如說 StreamGraph 是怎么生成的或者是 Exactly Once 究竟如何實現的,那么就需要去閱讀源碼了。
關鍵是看你的目的是什么,如果你想了解思想,經驗等看文檔就夠了,因為文檔是人寫給人的;如果你想了解具體細節,那應該去看源碼,因為源碼是人寫給機器的,源碼里有到底做了什么這些事情。
那么我寫這篇的文章目的是什么?我的目的是,萬一你已經在生產上身經百戰了,對 Flink 的原理都把握住了,那么看源碼是對你來說最好的進階方式,所以我為你準備了這篇搭建環境的教程,為你節約寶貴的時間陪家人陪孩子不香嗎?
通常對于閱讀源碼這件事情來說是有方法論可循的。
相關語言和基礎技術知識。比如 Java,Maven,Git,設計模式等等。如果你只會 C++,哪天心血來潮去閱讀 Flink 源碼,那是不現實的;
開源項目的功能。需要知道這個項目是為了解決什么問題,完成什么功能,有哪些特性,如何啟動,有哪些配置項。先把這個項目跑起來,能運行簡單的 Demo;
相關的文檔。也就是龐大的工程中,有哪些模塊,每個模塊大概的功能是干嘛的;
這些前提知識準備好了之后,你就對這個項目有了一個感性的認識,再去閱讀它的代碼就輕松一些了。
在閱讀代碼過程中,不是說拿到源碼就直接從第一個模塊一行行的開始讀,這樣很容易迷失方向,陷入到代碼細節中無可自拔。
接口抽象定義。任何項目代碼都會有很多接口,接口的繼承關系和方法,描述了它處理的數據結構,業務實體以及和其他模塊的關系,理清楚這些關系是非常重要的。
模塊粘合層。代碼中很多的設計模式,都是為了解耦各個模塊的,好處就是靈活擴展,壞處就是讓本來平鋪直述的代碼割裂成一個個模塊,不那么方便閱讀。
業務流程。在代碼一開始,不要進入細節,一方面會打消你的積極性,一方面也看不過來。要站在一定的高度,搞清楚整個的業務流程是怎樣的,數據是怎么被傳遞的。最好可以畫流程圖或者時序圖,方便理解和記憶。
具體實現。在具體實現中,仍然需要弄清楚一些重要的點
(1)代碼邏輯。在代碼中,有業務邏輯,是真正的業務處理邏輯;還有控制邏輯,像流程流轉之類的;
(2)出錯處理。其實很多地方都是在處理出錯的邏輯,可以忽略掉這部分邏輯,排除干擾因素;
(3)數據處理。屬性轉換,JSON 解析,XML 解析,這些代碼都比較冗長和無聊,可以忽略;
(4)重要的算法。這是比較核心的地方,也是最有技術含量的地方;
(5)底層交互。有一些代碼是和底層操作系統或者是和 JVM 交互的,需要知道一些底層的東西;
運行時調試。這是最直接的方式,可以看到代碼究竟是如何跑起來的,數據是怎么樣的,是了解代碼最重要的方式。
總結成一句話:高屋建瓴,提綱挈領,把握方向
好了,有了這些內容心法,下面開始實戰吧!
我就不具體演示了,說一下大致流程,可以自行百度,相關的文章很多的。
下載對應平臺(Windows,Mac)的 Git 客戶端,并安裝
下載地址:https://git-scm.com/downloads
$ git config --global user.name "Your Name" $ git config --global user.email yourEmail@example.com
ssh-keygen -t rsa
登陸 Gitee,在頭像 - 設置 - 安全設置 - SSH 公鑰 添加一個公鑰
GitHub 很慢如何下載好幾十 M 的源碼文件呢?
你想下載任意 GitHub 項目,都可以在 Gitee 上導入這個 Github 項目:

導入之后,就可以下載了。當然 Apache Flink 活躍度前幾的項目,Gitee 肯定是會同步的了,直接搜索即可。
https://gitee.com/apache/flink?_from=gitee_search
然后打開 Git Bash,克隆這個項目
git@gitee.com:apache/flink.git
獲取所有的分支
git fetch --tags
切換到 1.12.0 分支
git checkout release-1.12.0
這樣最新發布的 1.12.0 版本源碼就在本地了。
在導入 IDEA 之前,我們要配置 Maven 的鏡像為阿里云的,這樣下載 Jar 包比較快速。
在 Maven 安裝目錄的 conf 目錄的 settings.xml 文件中,加入如下配置到 mirrors 標簽中
<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror>
打開 IDEA,直接打開即可,等待它下載好所有的依賴

導入后,可以看到有很多模塊,但是各個模塊的功能見名知意,非常清晰,這里我就不挨個介紹了。直接開始 Debug Flink-Clients 模塊。
首先想強調一下,為什么要調試這個模塊。因為這個模塊是提交 Flink 作業的入口模塊,代碼流程相對比較清晰,調試完,就可以知道 Flink 作業是怎么提交的了。
回憶下,大數據的 Hello,World 程序是什么,是不是 WordCount,Flink 發行版自帶的例子中,就有 WordCount 程序。
下面的圖,我是下載了官網的 Flink-1.12 發行版,放到我的虛擬機上了。
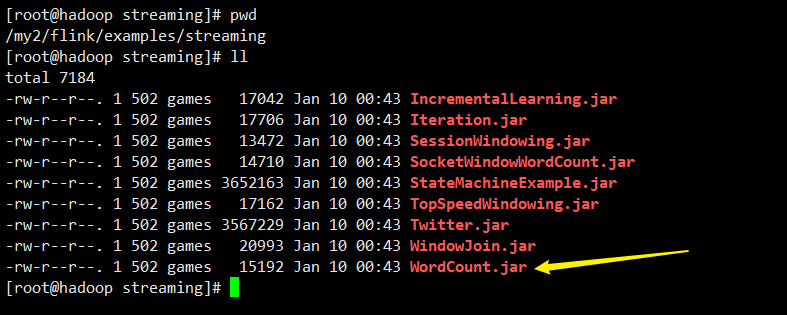
如何把它運行起來呢?
首先啟動一個本機的 Flink 集群,把壓縮包解壓出來之后,什么都不要做,直接啟動
cd /my2/flink/bin ./start-cluster.sh
提交 WordCount 程序到集群
./flink run ../examples/streaming/WordCount.jar
這樣就直接把 WordCount 程序提交到集群上了,是怎么做到的呢?可以看看 flink 這個命令里面是什么
vi flink
移動到最后,可以發現
# Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems
exec $JAVA_RUN $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"原來它就是一個 java -classpath 類名,啟動了一個 Java 虛擬機啊
這個類就是
org.apache.flink.client.cli.CliFrontend
這個類就是我們要運行的對象了
可以看到 CliFrontend 里面有一個 main 方法,二話不說,直接 debug,報錯了再說
果然,報錯如下:

說在環境變量中,沒有找到 FLINK_CONF_DIR 配置,也就是 flink 配置文件沒有找到,就是那個 flink-conf.yml 文件
這個文件其實是在發行目錄下:
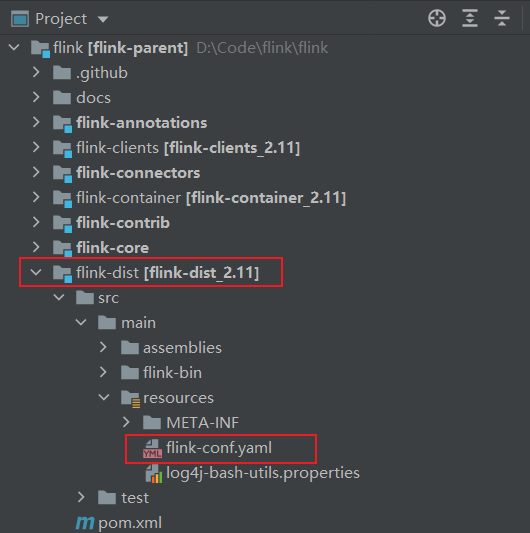
然后配置一個
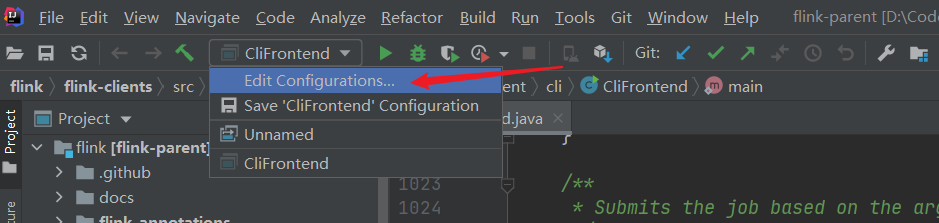
在這個地方加上這個配置

FLINK_CONF_DIR=D:\Code\flink\flink\flink-dist\src\main\resources
再運行一遍,報錯如下
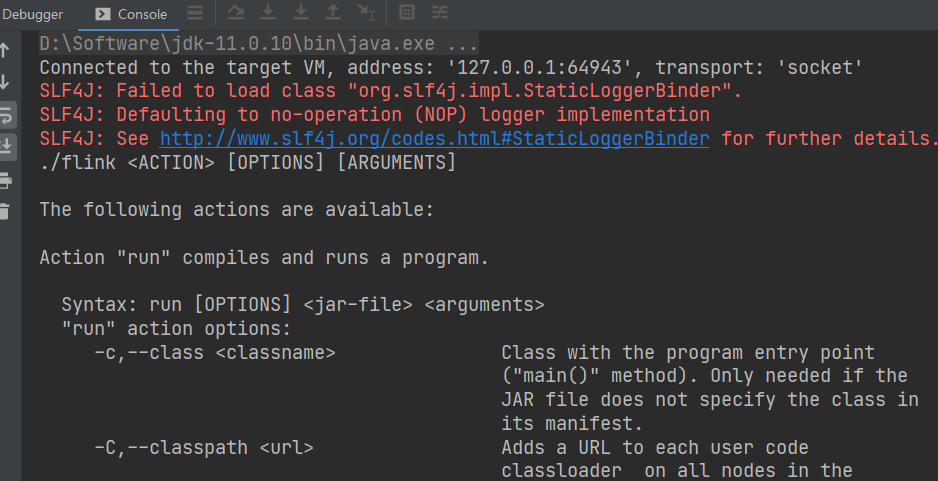
原來是因為,我們之前在運行命令的時候,后面還有一坨參數,現在什么參數都沒有往 main 方法傳,當然報錯了。
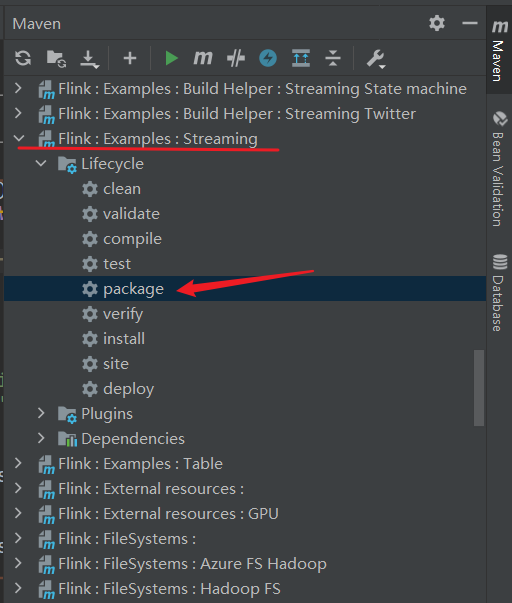
這里我們還需要一個 WordCount.jar 包,源碼都有了,直接從源碼打包一個出來,就是這么的任性了。
直接把 Flink : Examples : Streaming 模塊打個包
打完包之后,在 target 目錄下,就會有一個 WordCount.jar 包了

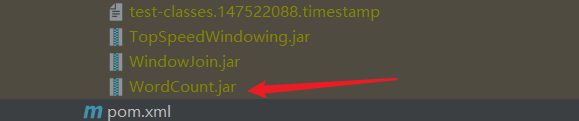
填到這個地方
run D:\Code\flink\flink\flink-examples\flink-examples-streaming\target\WordCount.jar

然后再 Debug 看一下,發現它在這卡了很久,直到超時(WARNING 先不用管)
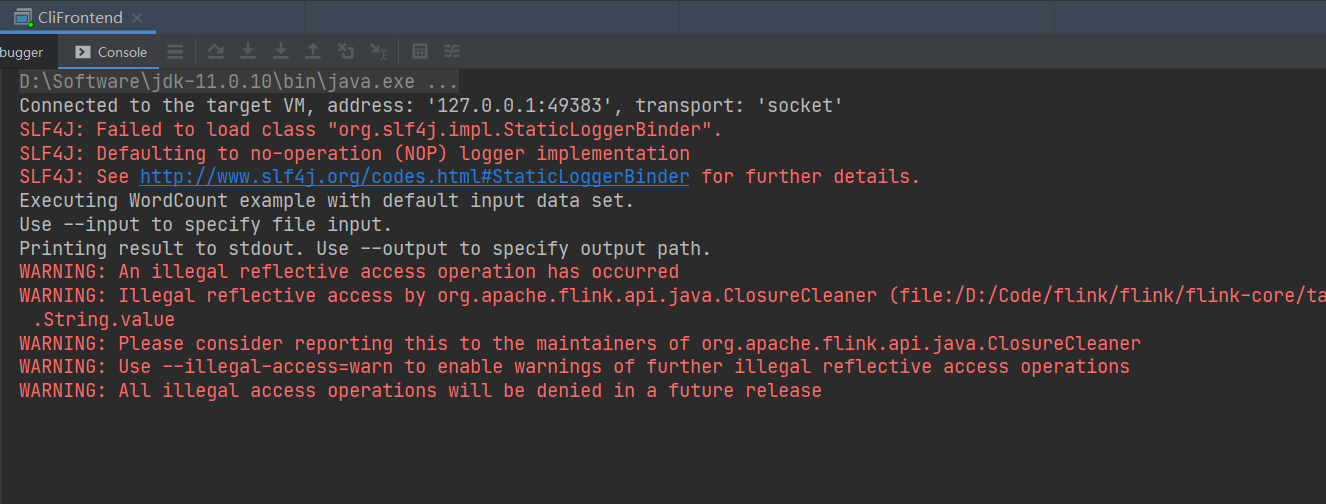
這個是正常的,因為它在最后生成 JobGraph 之后,是要通過 JobClient 客戶端,提交到集群上的(還記得我們那個配置文件嗎?里面可是配了集群的 JobManager 地址和端口的),而我們在 Windows 本地并沒有啟動集群。
關于如何分析Flink源碼閱讀環境搭建并調試Flink-Clients模塊就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





