溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何用R語言和Python進行相關性分析,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
由于最近畢業論文纏身,一直都沒有太多時間和精力撰寫長篇的干貨,但是呢學習的的腳步不能停止,今天跟大家盤點一下R語言與Python中到的相關性分析部分的常用函數。
常用的衡量隨機變量相關性的方法主要有三種:
pearson相關系數;即皮爾遜相關系數,用于橫向兩個連續性隨機變量間的相關系數。
spearman相關系數;即斯皮爾曼相關系數,用于衡量分類定序變量間的相關程度。
kendall相關系數;即肯德爾相關系數,也是一種秩相關系數,不過它所計算的對象是分類變量。
R語言:
cor
cor.test
corrplot
cor(x,y=NULL,use="everything",method= c("pearson","kendall","spearman"))
在R語言中,通常使用cor函數進行相關系數分析,可以分別指定向量,也可以指定給cor函數一個數據框。
use函數指定處理缺失值的方式
method是可選的三種相關系數計算方法。
這里以diamonds數據集為例:
library("ggplot2")
str(diamonds)
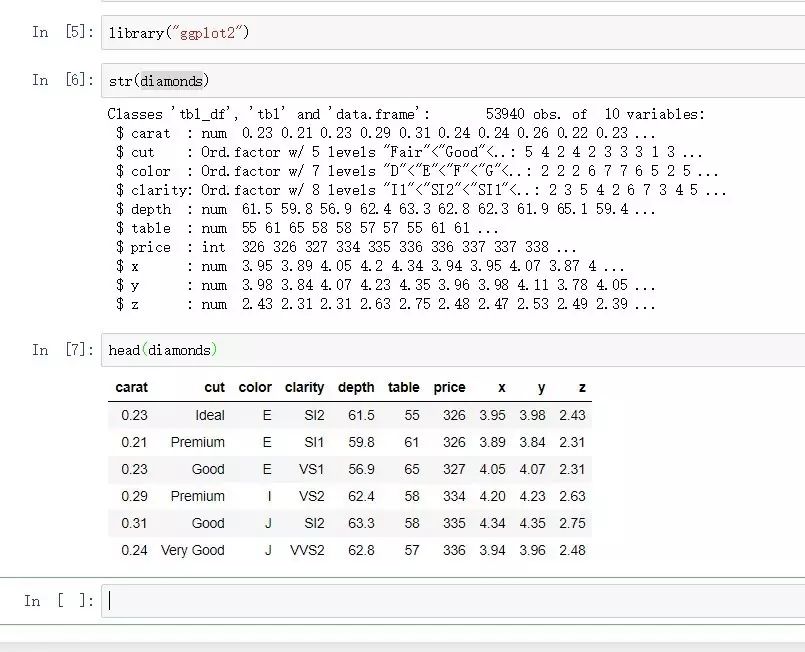
cor(diamonds[,c("carat","depth","price")])
cor(diamonds[,c("carat","depth","price")],method= "pearson")
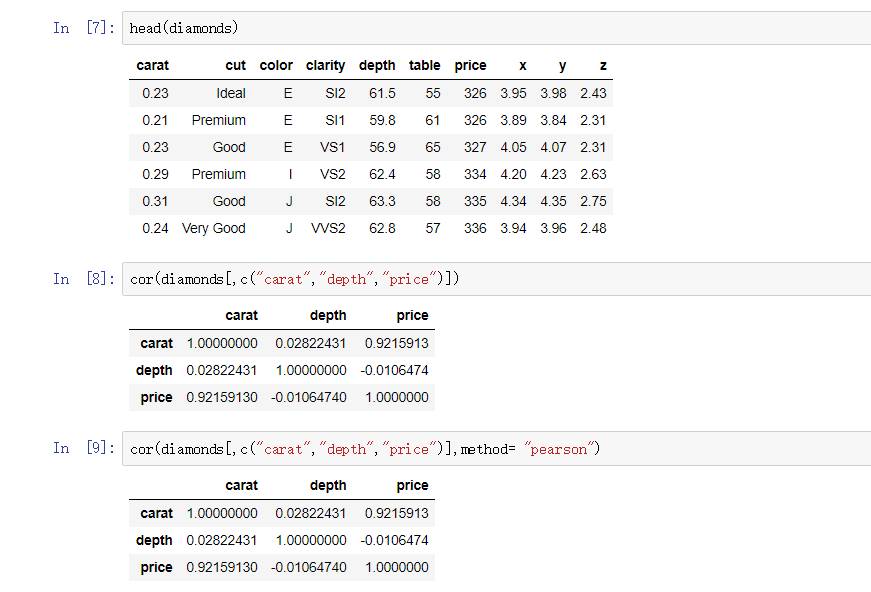
默認情況下使用的是pearson相關系數。
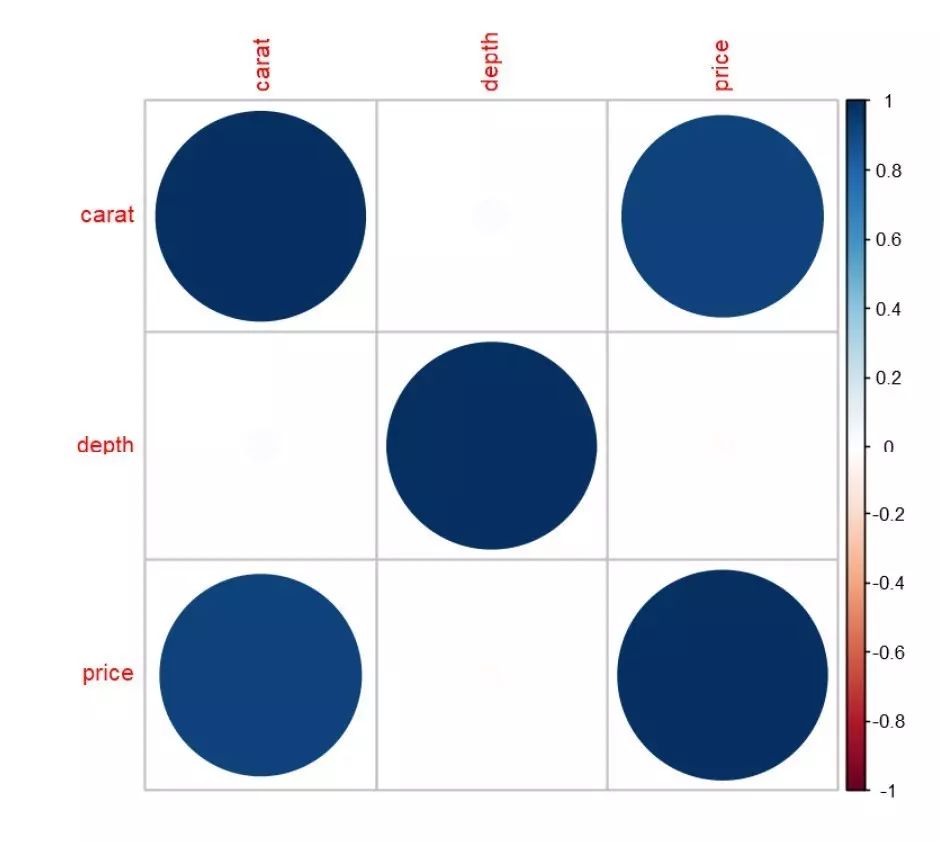
corrplot函數可以針對相關系數輸出的結果進行可視化:
library("corrplot")
library("dplyr")
cor(diamonds[,c("carat","depth","price")])%>%corrplot()
使用cor.test函數進行相關性的檢驗:
cor.test(x, y, #指定帶分析變量
alternative = c("two.sided", "less", "greater"),
#雙側檢驗,單側檢驗(默認雙側)
method = c("pearson", "kendall", "spearman"),
#相關性算法(默認pearson法)
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
cor.test(diamonds$carat,diamonds$depth)
cor.test(~carat+depth,diamonds)
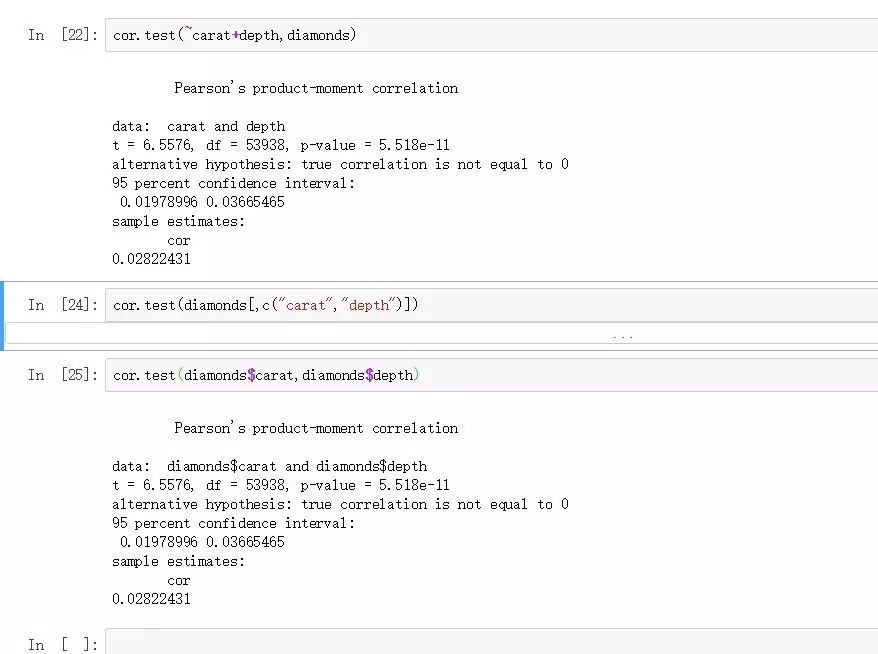
以上兩種寫法都是支持的。
從結果可以看到,兩者幾乎不相關,pearson相關系數僅有0.02左右。
Pyhton:
import pandas as pd
import numpy as np
diamonds=pd.read_csv('D:/R/File/diamonds.csv',sep = ',',encoding = 'utf-8')
diamonds.info()
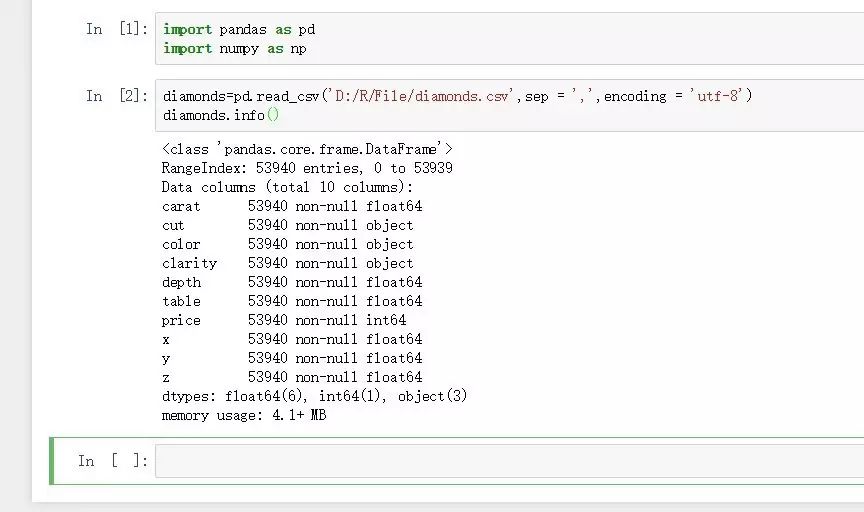
pandas中帶有相關系數函數pandas.corr

mydata=diamonds[["carat","depth","table","price"]]
mydata.info()
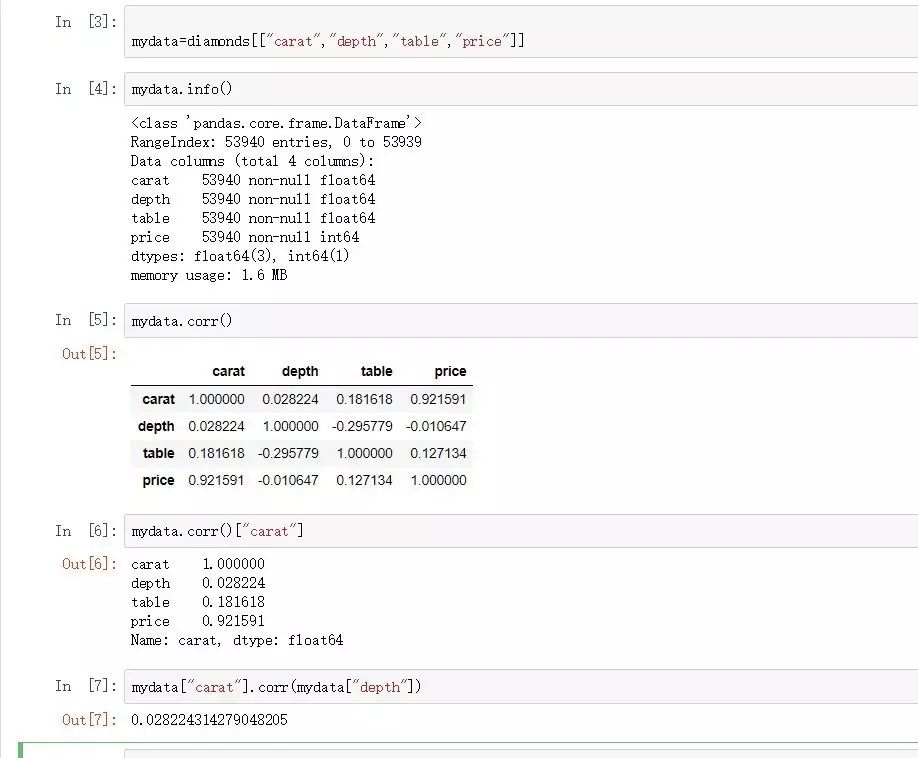
mydata.corr()
#可以直接給出數據框的相關系數矩陣
mydata.corr()["carat"]
#給出caret變量與其他變量之間的相關系數
mydata["carat"].corr(mydata["depth"])
#計算"carat"與"depth"之間的相關系數
與R語言中一樣,pandas中內置的相關系數算法也是針對針對數值型變量的pearson法。
mydata.corr(method='pearson')
mydata.corr(method='pearson')["carat"]
mydata["carat"].corr(method='pearson',mydata["depth"])
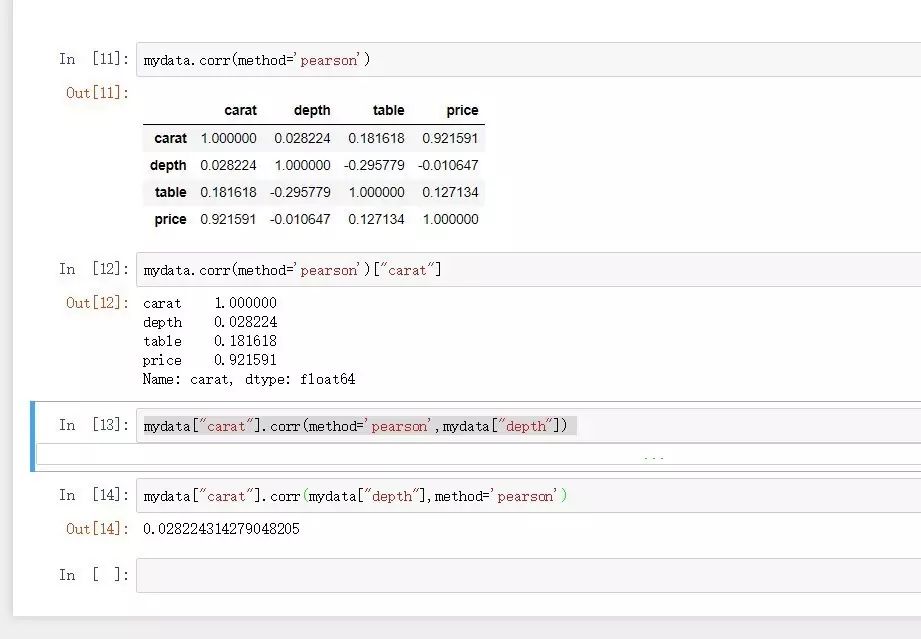
method也可以指定spearman法和kendall法計算相關系數。
本文小結:
R語言:
cor
cor.test
corplot
Python:
pandas.corr
以上就是如何用R語言和Python進行相關性分析,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





