溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么通過增加模型的大小來加速Transformer的訓練和推理,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
你沒有看錯,確實是通過增大模型的大小,大家別忘了,在訓練的時候,有個隱含條件,那就是模型需要訓練到收斂。
在深度學習中,使用更多的計算(例如,增加模型大小、數據集大小或訓練步驟)通常會導致更高的準確性。考慮到最近像BERT這樣的無監督預訓練方法的成功,這一點尤其正確,它可以將訓練擴展到非常大的模型和數據集。不幸的是,大規模的訓練在計算上非常昂貴的,尤其是在沒有大型工業研究實驗室的硬件資源的情況下。因此,在實踐中,我們的目標通常是在不超出硬件預算和訓練時間的情況下獲得較高的準確性。
對于大多數訓練預算,非常大的模型似乎不切實際。相反,最大限度提高訓練效率的策略是使用隱藏節點數較小或層數量較少的模型,因為這些模型運行速度更快,使用的內存更少。
然而,在我們的最近的論文中,我們表明這種減少模型大小的常見做法實際上與最佳的計算效率訓練策略相反。相反,當在預算內訓練Transformer模型時,你希望大幅度增加模型大小,但是早點停止訓練。換句話說,我們重新思考了模型必須被訓練直到收斂的隱含假設,展示了在犧牲收斂性的同時,有機會增加模型的大小。
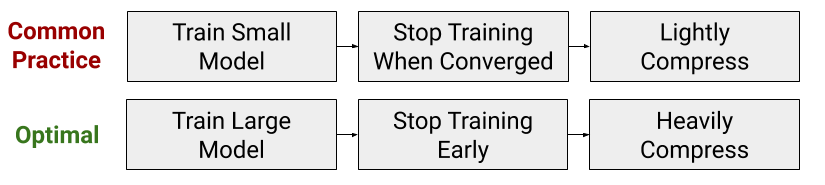
這種現象發生的原因是,與較小的模型相比,較大的模型在較少的梯度更新中可以收斂于較低的測試誤差。此外,這種收斂速度的提高超過了使用更大模型的額外計算成本。因此,在考慮訓練時間時,較大的模型可以更快地獲得更高的精度。
我們在下面的兩條訓練曲線中展示了這一趨勢。在左側,我們繪制了預訓練的驗證誤差RoBERTa,這是BERT的一個變體。RoBERTa模型越深,其混亂度就越低(我們的論文表明,對于更寬的模型也是如此)。這一趨勢也適用于機器翻譯。在右側,我們繪制了驗證BLEU分數(越高越好),當訓練一個英語到法語的Transformer機器翻譯模型。在相同的訓練時間下,深度和寬度模型比小模型獲得更高的BLEU分數。
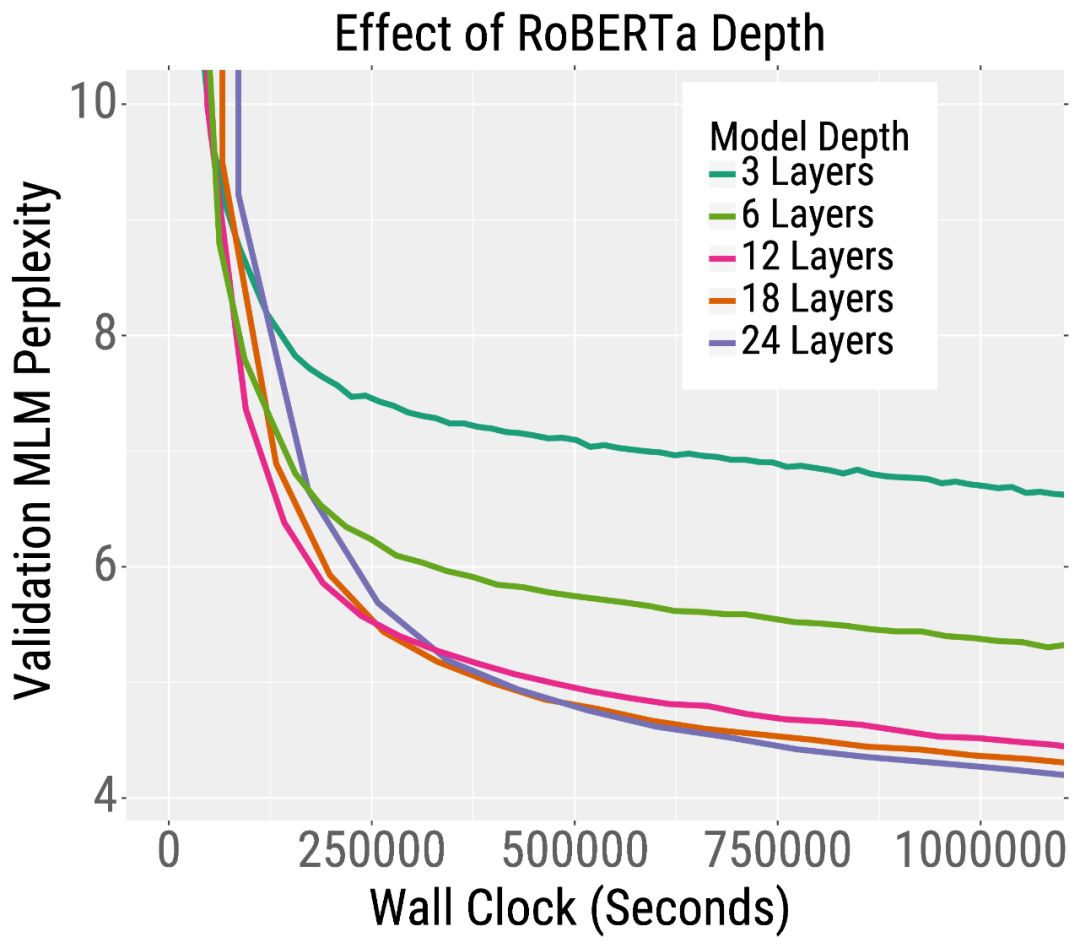
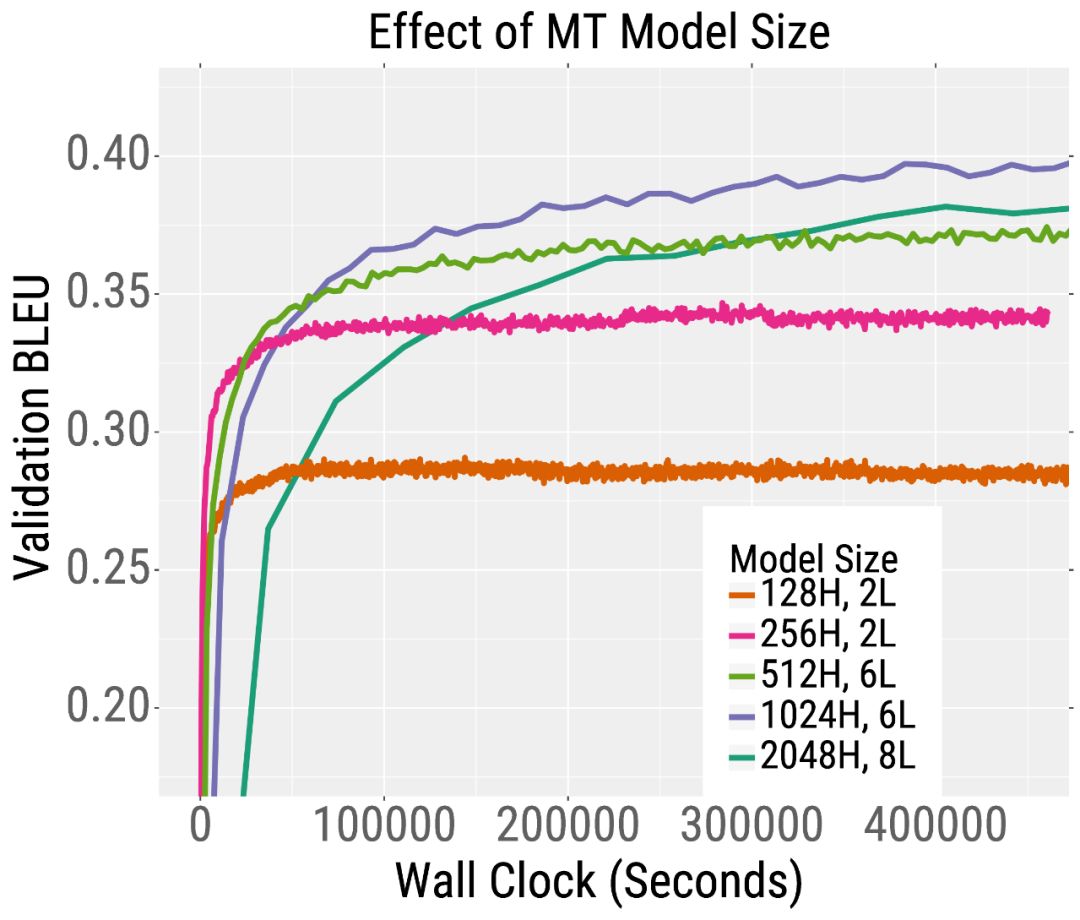
有趣的是,對于訓練前的RoBERTa來說,增加模型的寬度和/或深度都會導致更快的訓練。對于機器翻譯,更寬的模型比更深的模型表現得更好。因此,我們建議在深入之前嘗試增加寬度。
我們還建議增加模型大小,而不是batch size大小。具體地說,我們確認一旦batch size接近臨界范圍,增加batch size大小只會在訓練時間上提供微小的改進。因此,在資源受限的情況下,我們建議在這個關鍵區域內使用batch size大小,然后使用更大的模型。
盡管更大的模型具有更高的“訓練效率”,但它們也增加了“推理”的計算和內存需求。這是有問題的,因為推理的總成本遠遠大于大多數實際應用的訓練成本。然而,對于RoBERTa來說,我們證明了這種取舍可以與模型壓縮相協調。特別是,與小型模型相比,大型模型對模型壓縮技術更健壯。因此,人們可以通過訓練非常大的模型,然后對它們進行大量的壓縮,從而達到兩全其美的效果。
我們使用量化和剪枝的壓縮方法。量化以低精度格式存儲模型權重,修剪將某些神經網絡的權值設置為零。這兩種方法都可以減少推理延遲和存儲模型權值的內存需求。
我們首先在相同的時間內預訓練不同尺寸的RoBERTa模型。然后,我們在下游文本分類任務(MNLI)中對這些模型進行微調,并使用修剪或量化。我們發現,對于給定的測試時間預算,最好的模型是那些經過大量訓練然后經過大量壓縮的模型。
例如,考慮最深度模型的修剪結果(左圖中的橙色曲線)。不需要修剪模型,它達到了很高的精度,但是使用了大約2億個參數(因此需要大量的內存和計算)。但是,可以對這個模型進行大量的修剪(沿著曲線向左移動的點),而不會嚴重影響準確性。這與較小的模型形成了鮮明的對比,如粉紅色顯示的6層模型,其精度在修剪后嚴重下降。量化也有類似的趨勢(下圖)。總的來說,對于大多數測試預算(在x軸上選擇一個點)來說,最好的模型是非常大但是高度壓縮的模型。
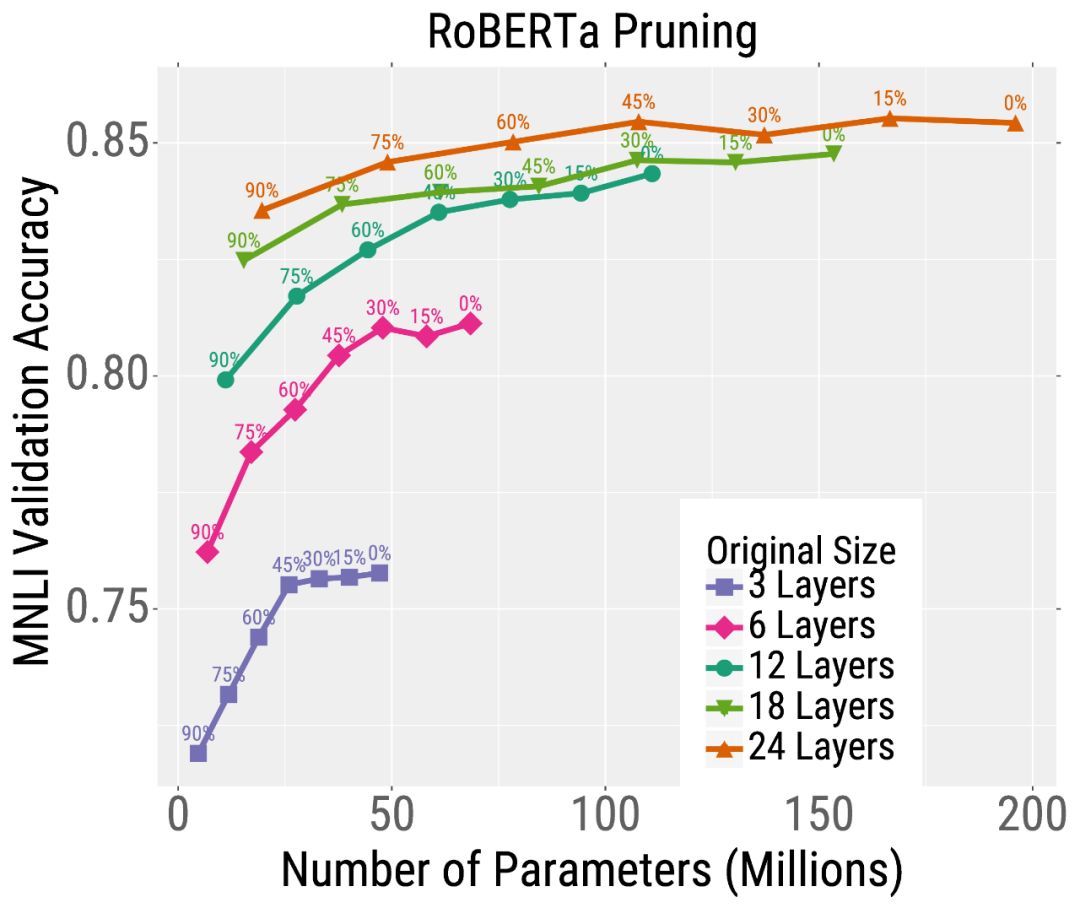
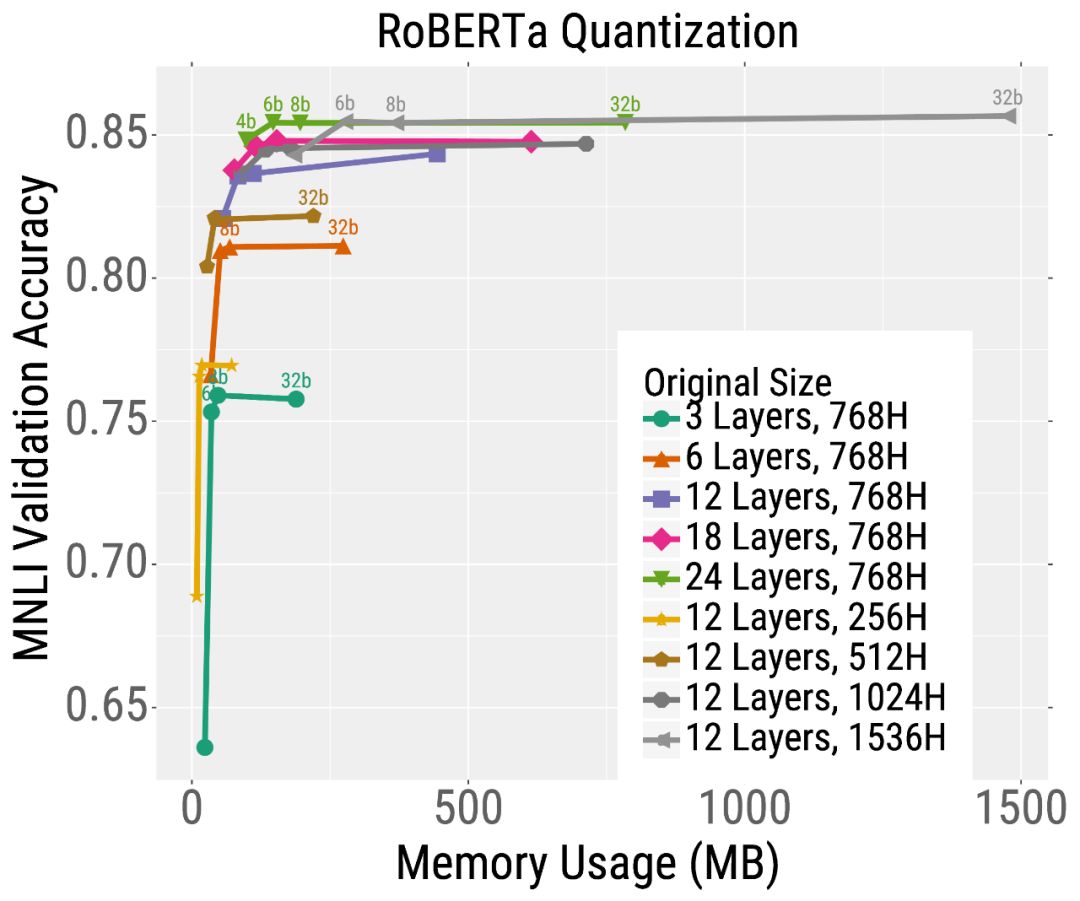
我們已經證明了增加Transformer模型的大小可以提高訓練和推理的效率,即,應該先“大模型訓練”,然后再“壓縮”。這一發現引出了許多其他有趣的問題,比如為什么大的模型收斂得更快,壓縮得更好。
以上就是怎么通過增加模型的大小來加速Transformer的訓練和推理,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





