溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何正確的使用Annovar,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
annovar的下載及安裝
Annovar是用perl語言寫的,可以在任何安裝了perl的系統上運行,且不需要進行安裝,直接下載解壓就可以使用。但它的下載需要注冊,且需要使用教育機構或者科研單位后綴的郵箱。當然,如果你沒有注冊郵箱也沒有關系,后臺回復annovar即可得到軟件安裝包。Annovar主要有三種不同形式的注釋方式:
1、Gene-based annotation:根據SNP或者CNV的位置來判斷是否會引起蛋白質編碼的變化,是否發生了氨基酸的改變。
2、 Region-based annotation: 來鑒定特定基因組區域的突變。
3、Filter-based annotation:用來鑒定特定數據庫中的突變。下載完annovar并且解壓之后,主要包括以下文件:
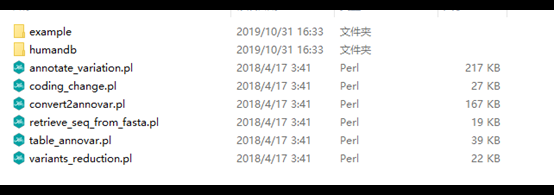
example:存放的是示例文件
humandb:部分注釋數據庫的文件,annovar的軟件中自帶了一部分,根據自己的研究需要也可以自己下載
annotate_variation.pl:主程序,用來進行數據庫的下載,以及不同形式的注釋
coding_change.pl:用來推斷蛋白質的序列是否發生變化
convert2annovar.pl:將其他多種形式轉化為annovar可識別的形式(如將vcf文件轉化為annovar可識別形式)
retrieve_seq_from_fasta.pl:自行建立其它物種的轉錄本
table_annovar.pl:可以一次完成三種不同形式的注釋
variants_reduction.pl:用來定制過濾注釋流程
— 輸入文件 —
Annovar的輸入文件是一個簡單的文本格式文件,其中前五列應分別是染色體號、突變位點在染色體上的起始位置、突變位點的結束位置、該突變位點在參考序列上的堿基以及該位點的突變堿基,其他列的內容可以有也可以沒有。
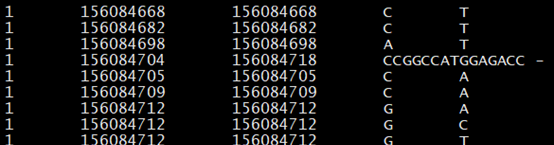
如果輸入文件是vcf文件,可以采用annovar的convert2annovar.pl程序將vcf文件轉化為annovar可識別的文件形式,具體的命令如下:
perl convert2annovar.pl -format vcf4 G-001.vcf -outfile G.avinput
輸出文件的格式為:
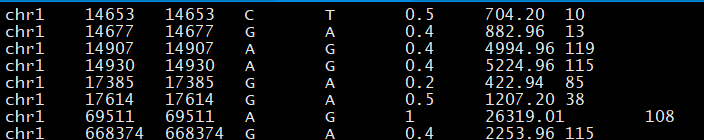
— 數據庫下載 —
Annovar的注釋主要依賴于數據庫,因此在進行分析之前,應將所需的數據庫下載到humandb文件夾中,下載的命令如下:
perl annotate_variation.pl -buildver hg19 -downdb -webfrom annovar avsnp147 humandb/
-buildver:對應參考基因組的版本
-downdb –webfrom annovar:從annovar庫中下載對應的數據庫,如果不知道要下載什么數據庫,可以在annovar庫中查看對應的數據庫以及對應的功能,網址為:(http://annovar.openbioinformatics.org/en/latest/user-guide/download/)
avsnp147:下載的數據庫的名稱
humandb:下載到humandb文件夾中
— 結果注釋—
整理好輸入文件格式以及下載好數據庫后,就可以進行注釋了,下面以table_annovar.pl為例介紹下annovar的注釋功能,具體命令如下:
perl table_annovar.pl GCK.avinput annovar/humandb/ -buildver hg19 -out GCK -remove –protocol refGene,1000g2015aug_eas,1000g2015aug_eur,1000g2015aug_sas,1000g2015aug_amr -operation g,f,f,f ,f -nastring .
table_annovar.pl:輸入文件
-buildver:參考序列版本
-out:輸出文件
-remove:刪掉程d序運行過程中產生的中間文件
–protocol:數據庫的名稱
-operation:對應順序的數據庫的類型,如千人基因組,dbsnp數據庫等(g代表gene-based、r代表region-based、f代表filter-based),與前面數據庫一一對應
-nastring .:缺省值用.表示
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





