溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
絕大多數的應用系統中,一開始數據的存儲和計算基本都是由數據庫來完成的,同時服務于業務交易和報表查詢;不過在經過幾年信息化建設和數據積累后,常常都會遇到數據庫壓力變大,從而導致性能瓶頸的問題。
究其原因,往往發現針對歷史數據查詢的報表在其中占了很大比重。進一步分析會發現,這類報表通常都有如下特征:
1、數據變化小:供查詢的歷史數據幾乎不再發生變化;
2、數據量大:數據量隨時間不斷增加;
由于大多數數據庫的JDBC性能都很低下(JDBC取數過程要做數據對象轉換,比從文件中讀取數據會慢一個數量級),如果數據始終存放在數據庫中,當涉及數據量較大或并發較多的時候,報表的性能會急劇下降,進一步還會嚴重影響相關的業務操作,如市場營銷、數據整理再匯報等。
針對這一問題,常見的解決方案是在生產庫和應用之間再增加一個前置數據庫,利用ETL工具定時從生產庫中提取數據,清洗后再導入到前置數據庫中,所有的歷史報表查詢都基于前置數據庫,從而和生產庫分離,緩解生產庫壓力。
不過這種方案增加了很多不必要的成本、多余的組件和工作量,同時也加大了后期的管理和維護難度;更為重要的是,當數據量比較大時,報表查詢還是很慢,因為上面已經提到過的根本問題并沒有得到解決,大多數數據庫的IO性能遠低于文件系統,而報表性能又嚴重依賴于數據庫取數環節,也就是說,沒能從根子上解決問題。
要從根子上解決問題,我們可以假設如果文件擁有計算能力的話,將這些變化不大的歷史數據搬出數據庫,采用文件系統存儲,而不是前置數據庫,那么將可能獲得比數據庫高得多的IO性能,這樣不僅能夠解決大數據量報表查詢慢的難題,我們還將獲得如下這些好處:
1、管理方便;文件天然支持多級目錄,而且復制、轉移、拆分都比數據庫簡單、高效得多,這樣,用戶就可以按照業務模塊、時間順序等規則分類管理數據,在應用程序下線時,也可以按照目錄刪除該應用對應的數據。數據管理因此變得簡單清晰,工作量顯著降低。
2、成本低廉;既然是文件,那就可以簡單地存儲在廉價硬盤中,無需購買昂貴的數據庫專用軟硬件。
3、降低數據庫擴容壓力;數據庫吞吐負擔降低,就可以顯著推遲擴容臨界點的到來,數據庫可以繼續服役,也可以節省大量的擴容成本。
4、資源利用率高;用文件來存儲數據并非要拋棄數據庫,相反的,文件應當只存儲安全要求不高、但數據量巨大的外圍數據以及庫外文件,而數據庫仍然存儲核心數據。如此一來,文件存儲和數據庫存儲各司其職,資源利用率顯著提高。
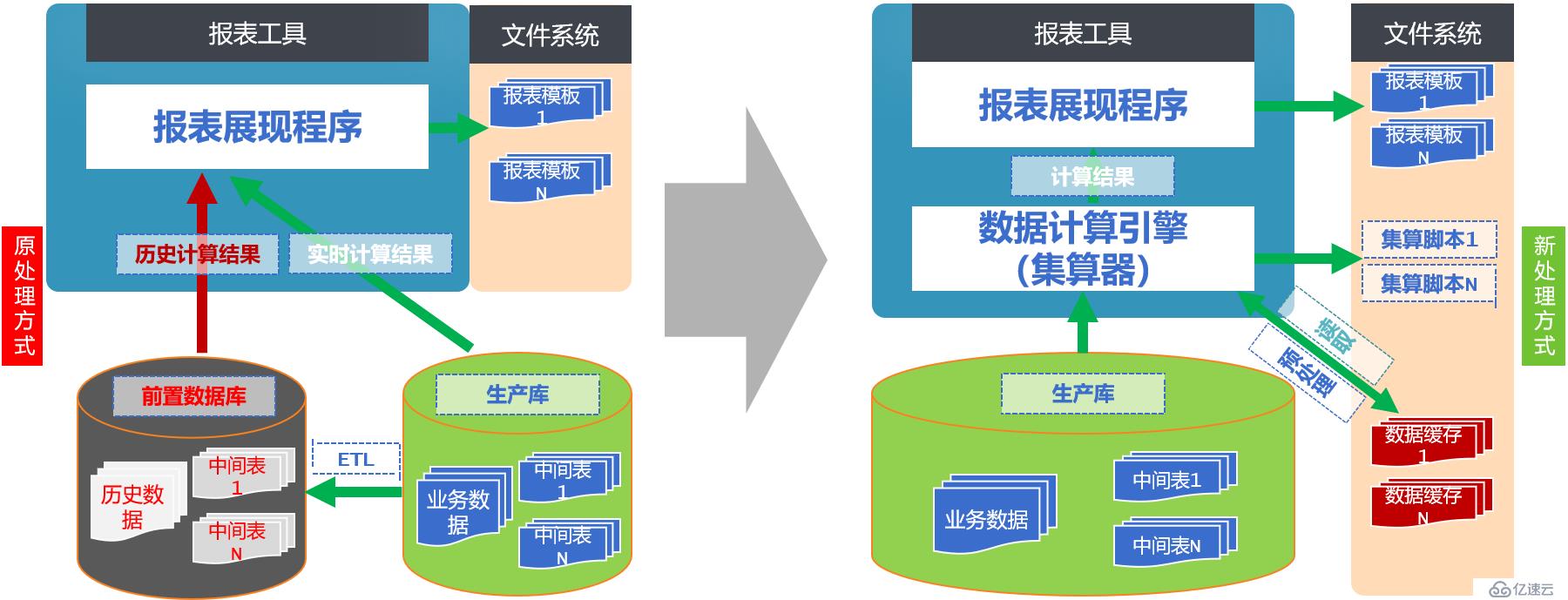
那么,如何才能有效地為文件賦予計算能力呢?下面將要介紹的潤乾集算器,就是這樣一款利器,通過集算器,可以實現復雜計算與報表展現的分離,其內置的集算引擎可以使文件擁有計算能力,輕松應對各種疑難雜癥。下圖顯示了常規情況和引入集算器后的報表系統結構對比,應該說,引入集算器后,整個體系架構變得更加清新與合理了:
接下來,我們通過一個典型的場景來說明集算器的作用和用法:
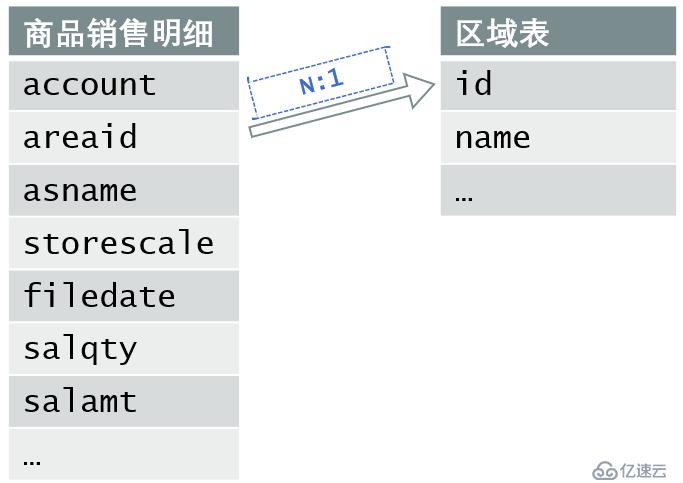
A表“商品銷售明細”的數據量上億,其中字段areaid與B表“區域表”的主鍵id關聯。A表稱為事實表,B表稱為維表。A表中與B表主鍵關聯的字段稱為A指向B的外鍵,B也稱為A的外鍵表。外鍵表是多對一的關系。如下圖示:
下面,我們就通過制作“各區域銷售員每日銷售額日增長率報表”,來看一下集算器是如何利用文件實現數據外置,從而提升報表查詢效率的。報表最終的展示效果如下圖:
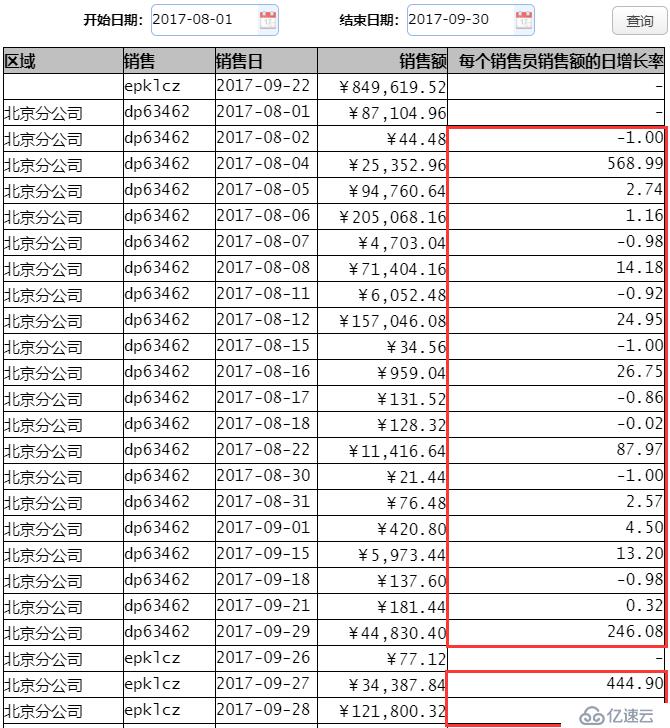
在這張報表中,根據選擇開始日期、結束日期進行查詢,報表先按照區域名稱、銷售員代碼、銷售日進行分組,統計每個銷售員每天的銷售額,以及每個銷售員每天銷售額的日增長率(算法為“(當日銷售額-上一日的銷售額)/上一日的銷售額”)。報表上部的查詢按鈕是報表工具提供的“參數模板”功能,具體做法參見教程,這里不再贅述。
在利用文件系統存儲數據的諸多優勢之前,我們首先應該先定義文件的目錄存儲結構:
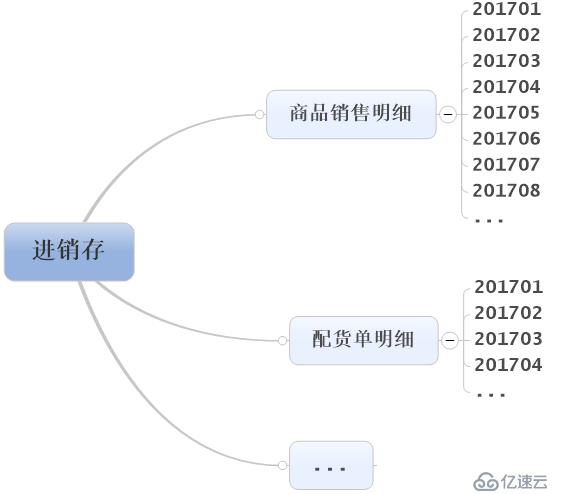
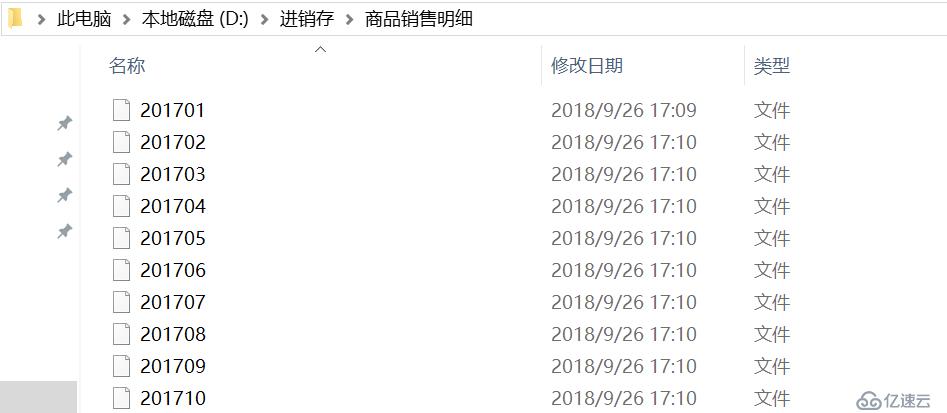
歷史數據的特征是交易成型后數據落地不再變化,而且數據量龐大,由此我們可以將每年的數據按照業務模塊、月份等規則進行劃分,即每個月份的數據存一份集文件(集文件利用集算器提供的壓縮格式,具有更好IO性能)。目錄結構就是:/業務模塊/數據明細表/年月文件名,如下圖所示:
同時,我們還需要設定每天凌晨時段定時執行數據同步腳本,把前一天的數據追加到當月集文件中;而在每月1號,腳本還會根據規則自動生成一個新的以年月命名的集文件。
先把2017年1到10月的歷史數據按不同月份搬出來(假定已有10個月的歷史數據),集算器的SPL腳本如下:
A | B | C | |
1 | =connect("demo") | ||
2 | =10.("SELECT * FROM sdrpts WHERE filedate>='2017-"/~/"-01'AND filedate<'2017-"/(~+1)/"-01'") | ||
3 | for A2 | =file("D:/進銷存/商品銷售明細/2017"+string(#A3,”00”)) | |
4 | =A1.cursor(A3) | >B3.export@ab(B4) | |
5 | >A1.close() | ||
A1:連接數據庫
A2:生成由10個SQL組成的集合,每個SQL分別查詢當月(1到10)范圍內的數據。寫法上,“10.”表示從1循環到10,在括號內的字符串中用相應的1到10替換 ~符號。
A3:按照A2中的序列循環執行
B3:按路徑打開每月數據的集文件,路徑命名規則是4位年和2位月,利用string()函數進行格式化,其中#號代表循環序號
B4:根據每段sql創建數據庫游標
C4:將游標執行計算后的結果寫入到集文件中。其中export()函數使用了@ab的選項,@b代表寫成集文件格式,而由于在for循環里面,需要執行多次,所以用@a指明追加方式,把結果逐步保存到文件中,保證文件的完整性。循環生成完之后,文件的存儲目錄結構如下圖:
A5:關閉數據庫連接
編寫單次執行腳本,獲取昨天的歷史數據追加到當月集文件中,每天執行,當下月1號時,會自動生成新文件,腳本如下:
A | B | C | |
1 | =after(date(now()),-1) | =year(A1) | =month(A1) |
2 | =file("D:/進銷存/商品銷售明細/"+string(B1)+string(C1,”00”)) | ||
3 | =connect("demo") | =A3.cursor("SELECT * FROM sdrpts WHERE DATE_FORMAT(fildate,'%Y-%m-%d')=?",A1) | >A2.export@ab(B3) |
4 | >A3.close() | ||
A1:根據當前系統時間,獲取昨天的日期
B1-C1:分別獲取到年、月
A2:按路徑打開需要導出的集文件,路徑規則是以4位年2位月命名,利用string()函數進行格式化
A3:連接數據庫
B3:根據sql創建數據庫游標,獲取昨日數據,參數為昨天日期
C3:執行結果追加寫入到集文件中
A4:關閉數據庫
在上面的步驟中,已經可以同步昨天的歷史數據到集文件中;但總是有意外情況發生,假如歷史數據沒有同步成功怎么辦呢?我們是不是可以通過記錄日志信息的方式,追溯歷史原因?這樣能夠及時發現問題,及時采取補救措施;比如:很小概率下腳本可能會執行失敗,這時如果及時發現,就可以先手動執行腳本重新生成集文件,然后再排查原因,從而避免影響業務查詢。(由于集文件目前不支持回滾動作,一旦導出出錯,需要重新導出數據生成當月集文件。集算器高版本的組表支持回滾,以后會有專門的文章詳細介紹)。
第一步,可以先在數據庫中定義一張日志表,包含五個字段(事件名稱/狀態/異常信息/執行時間/執行時長),數據結構如下圖示:

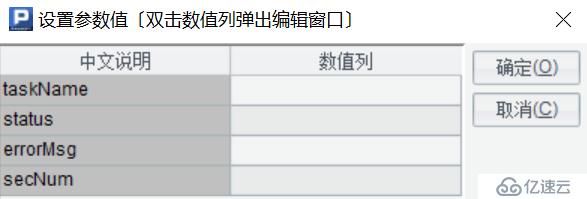
第二步,在集算器腳本中定義4個參數名,分別是事件名稱/狀態/異常信息/執行時長,參數定義如下圖所示:
第三步,當集算器腳本接收來自外界參數信息時,將參數值填寫到日志表中:
A | |
1 | =connect("demo") |
2 | =A1.execute("INSERT INTO sys_dfx_task_log (task_name,status,error_msg,excute_time,sec_num) VALUES (?,?,?,?,?)",taskName,status,errorMsg,now(),secNum) |
3 | >A1.close() |
A1:連接數據庫
A2:接收來自外界傳入的參數值后,向數據庫的日志表中執行SQL插入語句,包含五個字段(事件名稱/狀態/異常信息/執行時間/執行時長),其中now()函數代表獲取當期時間
A3:關閉數據庫
我們將判斷同步操作是否成功的規則設定為:當每天定時導出到集文件的數據條數與查詢出來需要同步數據的總條數相差小于5條的時候,我們認為同步動作是成功的,否則認定同步失敗,然后把關鍵信息寫入到日志表中。按此規則改造同步數據的集算器腳本如下:
A | B | C | |
1 | =after(date(now()),-1) | =year(A1) | =month(A1) |
2 | =file("D:/進銷存/商品銷售明細/ "+string(B1)+string(C1,”00”)) | =now() | =A2.cursor@b().skip() |
3 | =connect("demo") | =A3.cursor("SELECT * FROM sdrpts WHERE DATE_FORMAT(fildate,'%Y-%m-%d')=?",A1) | >A2.export@ab(B3) |
4 | =A3.query("SELECT COUNT(1) FROM sdrpts WHERE DATE_FORMAT(fildate,'%Y-%m-%d')=?",A1) | =A2.cursor@b().skip()-C2 | =interval@ms(B2,now()) |
5 | if A4.#1-B4<5 | >call("log.dfx","同步sdrpts"+string(A1)+"的數據完成,總記錄條數:"+string(A4.#1)+"總計導出:"+string(B4),"完成","",C4/1000) | |
6 | else | >call("log.dfx","同步sdrpts"+string(A1)+"的數據,導出的數據量跟數據庫中的相差超過5條","失敗","",0) | |
7 | >A3.close() | ||
前面已經解釋過的格子的代碼這里不再贅述。
B2:獲取當前系統時間,用于后面計算導出操作的執行時長
C2:統計寫入前集文件的記錄數
A4:執行sql查詢需要同步的昨天的數據總條數
B4:當數據追加寫入到集文件后,再統計一遍記錄數,同時減去寫入前的數量,得到實際寫入成功的記錄條數
C4:計算整個同步過程的執行時長,其中interval()函數通過選項@ms指定返回毫秒數
A5:判斷數據庫中需要同步數據的總條數與導出到集文件的數據總條數,兩者之差小于5條時,認為任務是執行成功的,在日志表中寫入成功記錄,否則認定任務執行失敗,在日志表中寫入失敗記錄。
B5-B6:根據執行成功或失敗的判斷,log.dfx網格文件,在日志表中寫入相應的記錄。
A7:關閉數據庫
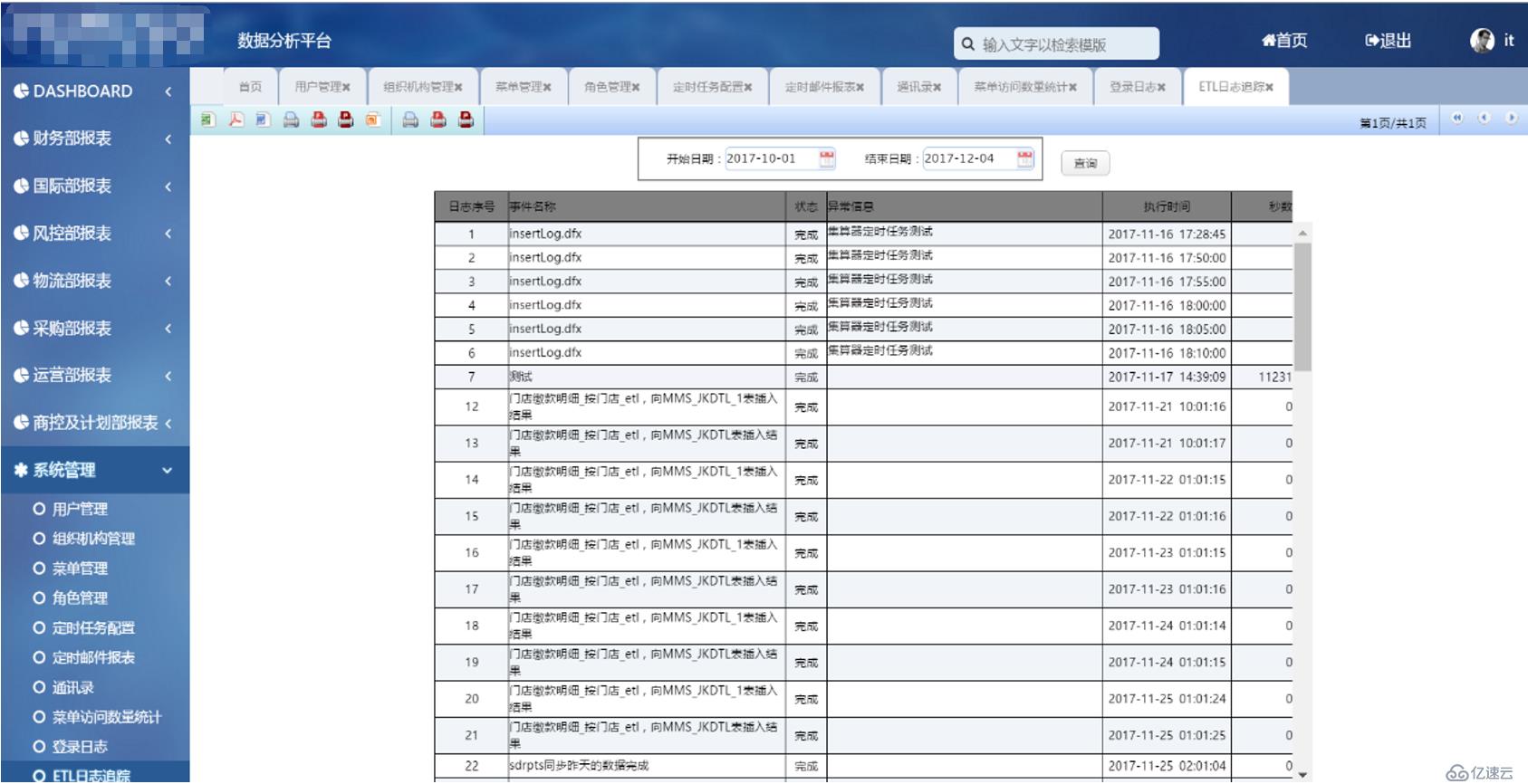
為了方便管理,我們還可以通過報表工具,做一張關于日志信息的查詢報表,這樣就能通過web端及時發現問題、解決問題,效果如下:
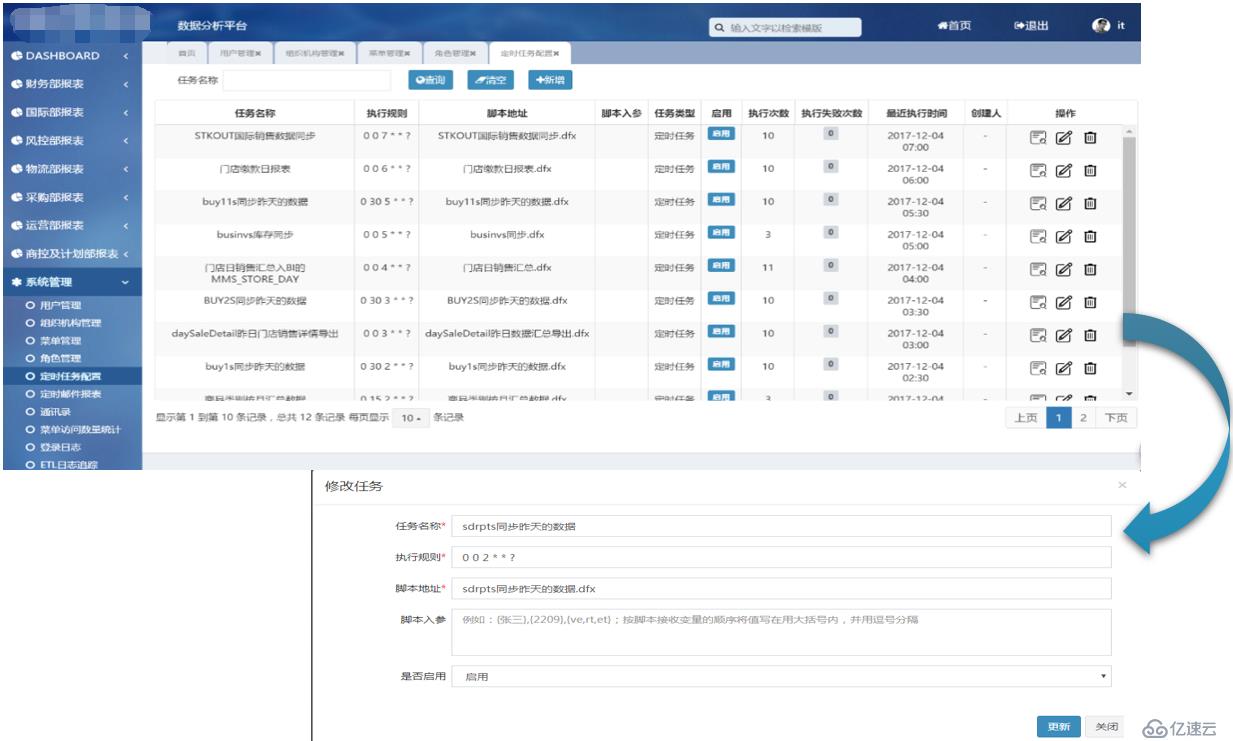
Quartz 是 OpenSymphony開源組織在Job scheduling領域的一個開源組件,利用Quartz可以簡便地創建定時執行任務,而集算器原本就是獨立的計算引擎,兩者結合起來,再提供一些可視化的配置和管理頁面,就能比較容易的實現輕量級ETL的功能。如下圖所示:
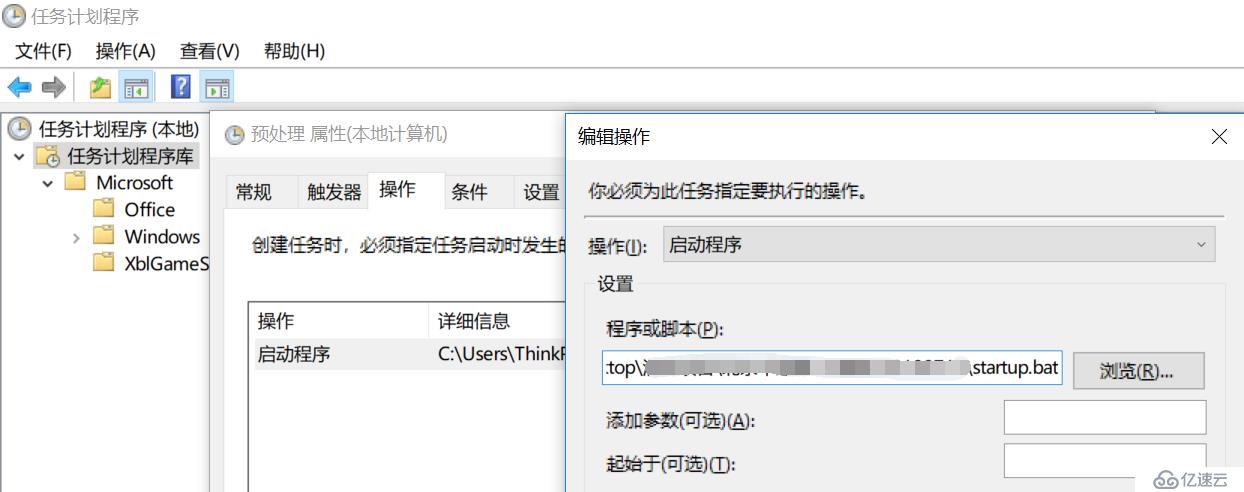
windows操作系統下,可以利用自帶的任務計劃程序實現定時任務,比如可以先新建一個bat文件,寫入需要執行的命令:
@echo off
"D:/esProc/bin/esprocx.exe" C:/20180713/synclastday.dfx
再配置一個計劃任務定時執行即可,如下圖所示:
而在Linux操作系統下,可以借助crontab實現定時任務,命令如下: /raqsoft/esProc/bin/esprocx.sh /esproc/synclastday.dfx
前面是一個比較完整 ETL 數據準備過程,下面我們將在這些準備工作的基礎上,完成“各區域銷售員每日銷售額日增長率報表”的制作,通過集算器利用文件實現數據外置,從而提升報表查詢效率。
我們先通過傳入開始日期、結束日期,只查詢一個月內的數據,也就是訪問某個月的集文件即可。(值得一提的是:集算器不僅能夠降低復雜業務運算的實現難度,同時,對于單文件的運算還提供了“簡單SQL”方式,讓懂SQL的用戶對文件的操作更容易上手。簡單SQL的特性不是本文的重點,有興趣的讀者可以參考相關文檔,這里不再贅述。)
第一步,分組匯總;根據起止日期過濾后,按照區域ID、銷售、日期分組,并匯總銷售金額(銷售數量*單價),同時區域ID,需要顯示成區域名稱。編寫集算器腳本如下:
A | |
1 | =connect("demo") |
2 | =A1.query@x("SELECT id,city FROM area") |
3 | =file("D:/進銷存/商品銷售明細/ "+string(year(Bfiledate))+string(month(Bfiledate),”00”)).cursor@b() |
4 | =A3.select(filedate>=Bfiledate && filedate<Efiledate) |
5 | >A4.switch(areaid,A2:id) |
6 | =A4.groups(areaid,account,date(filedate):filedate;sum(salqty*salamt):subtotal) |
7 | =A6.new(areaid.city:areaname,account,filedate,subtotal) |
8 | return A7 |
A1:連接數據庫
A2:通過SQL查詢外鍵表area,共兩個字段id,city,其中函數query()使用了@x選項,代表查詢結束時自動關閉數據庫連接,執行結果如下圖:

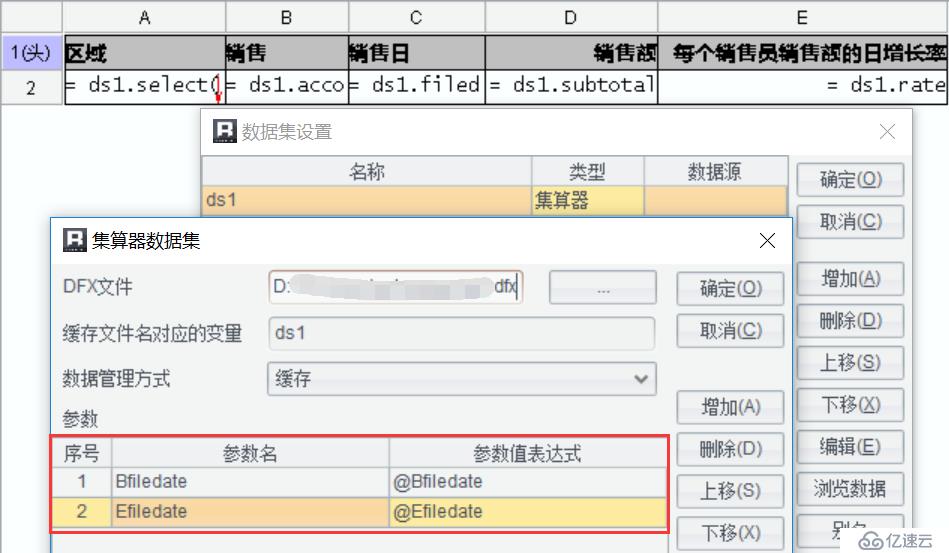
A3:打開集文件對象,根據文件創建游標返回,其中cursor()函數使用@b選項代表從集文件中讀取。我們事先在腳本設置中定義了2個參數,開始日期、結束日期,如下圖:
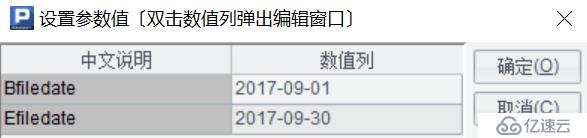
這里根據傳入的開始日期參數Bfiledate,就能夠準確的找到指定的集文件對象,比如:當Bfiledate的參數值為2017-09-01時,分別獲取年、月,拼在一起就是集文件的名稱,全路徑為:D:/進銷存/商品銷售明細/201709
A4:通過起止日期過濾出符合條件的記錄
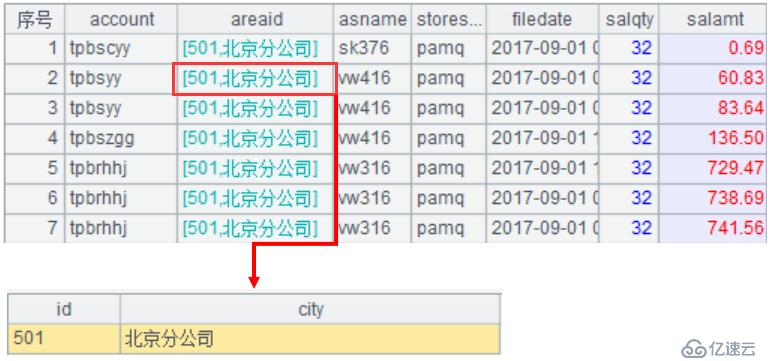
A5:通過switch()函數在A4表的areaid字段上建立指向A2表中id字段的指針引用記錄,實現關聯,如下圖:
A6:按區域ID、銷售、日期分組,并匯總銷售金額(銷售數量*單價)
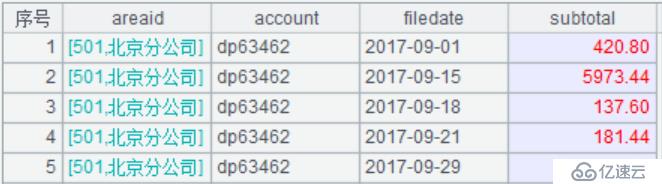
A7:計算字段值,生成新序表;其中利用A5建立的關聯關系通過“外鍵字段.維表字段”的方式進行引用,用 “areaid.city”生成新的字段areaname,(將維表記錄看做外鍵的的屬性,這便是外鍵屬性化的由來),返回關聯后的結果集如下圖:
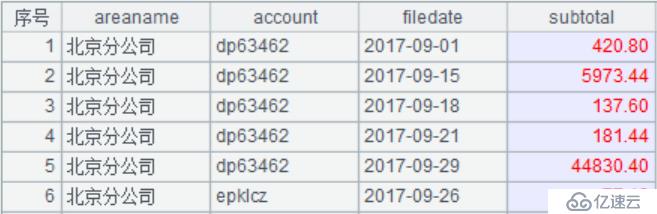
第二步,計算銷售日增長率;在第一步的基礎上,計算出每個區域下每個銷售員每天銷售額的日增長率; 修改后的腳本如下:
A | |
1 | =connect("demo") |
2 | =A1.query@x("SELECT id,city FROM area") |
3 | =file("D:/進銷存/商品銷售明細/ "+string(year(Bfiledate))+string(month(Bfiledate),”00”)).cursor@b() |
4 | =A3.select(filedate>=Bfiledate && filedate<Efiledate) |
5 | >A4.switch(areaid,A2:id) |
6 | =A4.groups(areaid,account,date(filedate):filedate;sum(salqty*salamt):subtotal,sum(0):rate) |
7 | =A6.run(if(areaid==areaid[-1]&&account==account[-1],rate=(subtotal-subtotal[-1])/subtotal[-1])) |
8 | =A7.new(areaid.city:areaname,account,filedate,subtotal,rate) |
9 | return A8 |
前面已經解釋過的格子代碼這里不再贅述。
A6:按區域ID、銷售、日期分組,并匯總銷售金額(銷售數量*單價),同時構造一個空的列叫rate,結果如下圖:
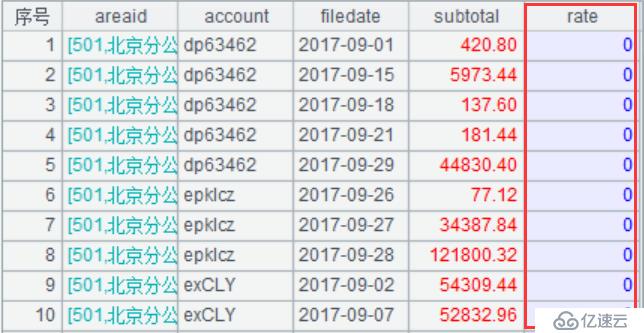
A7:在A6分組后的基礎上,針對每一行記錄,判斷相鄰行的areaid、account是否相等,相等的情況下,計算銷售員每天的銷售額的日增長率,算法為“(當日銷售額-上一日的銷售額)/上一日的銷售額”。可以看到,集算器用subtotal[-1]來表示上一日的銷售額,可以輕松進行相對位置的計算。
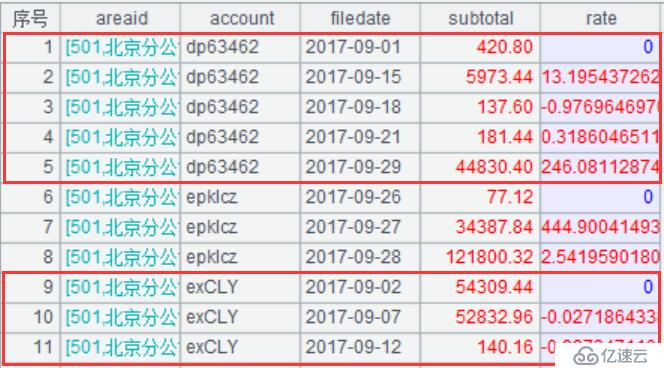
A8:返回關聯后結果集如下圖:
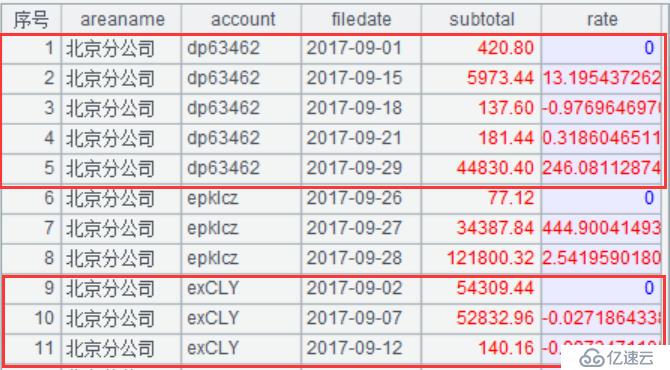
A9:返回結果集給報表工具
上一步已經實現了計算每個銷售員銷售額的日增長率,不過只能在一個集文件中查詢,也就是只能查詢一個月的數據。那如何跨多個集文件,從而實現跨月、跨年,適用于大數據量的報表查詢呢?
首先,我們需要寫一個工具腳本,主要功能是能夠根據傳入的開始日期、結束日期,過濾出需要查詢跨月度范圍的多個集文件路徑,同時判斷路徑下的集文件對象是否存在。腳本如下:
A | |
1 | =periods@m(startDate,endDate,1) |
2 | =A1.(path+string(year(~))+string(month(~),”00”)) |
3 | =A2.id() |
4 | =A3.select(file(~).exists()) |
5 | return A4 |
腳本接收3個參數,起止日期,集文件的存儲路徑,如下圖:
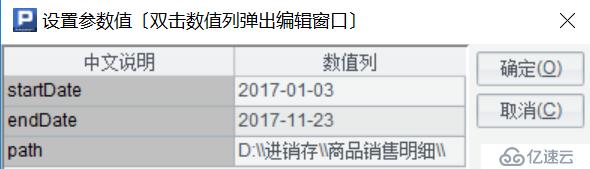
A1:根據起止日期,按月間隔獲取日期,其中periods()函數的選項@m代表按月間隔計算,比如,開始日期:2017-01-03,結束日期:2017-11-23,執行結果如下圖:
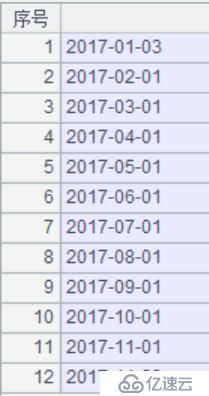
A2:循環A1,通過集文件的存儲路徑與該日期段內的年月進行拼接。月份要始終保持兩位,利用string()函數進行格式化,結果如下圖:
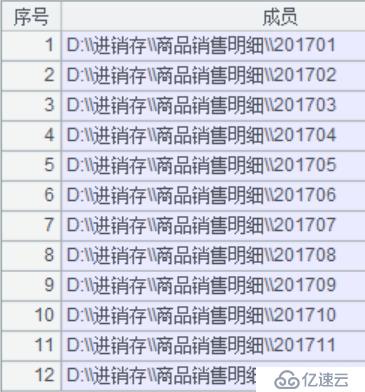
A3:去重,執行結果如下圖:
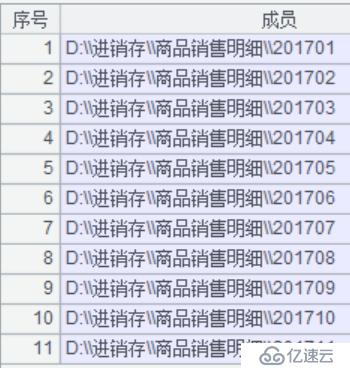
A4:判斷路徑下的文件是否真實存在,由A5返回實際存在的文件路徑,結果如下圖:
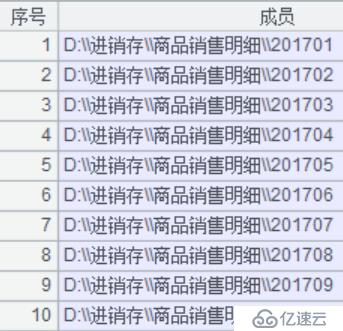
然后,我們需要對上面數據查詢的腳本做一些改造,值得注意的是這里將采用多路游標的概念,將多個游標合并成一個游標使用,改造后的腳本如下:
A | B | C | D | |
1 | =connect("demo") | =[] | ||
2 | =A1.query@x("SELECT id,city FROM area") | |||
3 | =call("D:/進銷存/商品銷售明細/判斷讀取文件的范圍.dfx",Bfiledate,Efiledate,"D:/進銷存/商品銷售明細/") | |||
4 | for A3 | =file(A4) | =B4.cursor@b() | >B1=B1|C4 |
5 | =B1.mcursor() | |||
6 | =A5.select(filedate>=Bfiledate && filedate<Efiledate) | |||
7 | >A6.switch(areaid,A2:id) | |||
8 | =A6.groups(areaid,account,date(filedate):filedate;sum(salqty*salamt):subtotal,sum(0):rate) | |||
9 | =A8.run(if(areaid==areaid[-1] && account==account[-1],rate=(subtotal-subtotal[-1])/subtotal[-1])) | |||
10 | =A9.new(areaid.city:areaname,account,filedate,subtotal,rate) | |||
11 | return A10 | |||
前面已經解釋過的格子代碼這里不再贅述。
A3:調用”判斷讀取文件的范圍.dfx”,傳入腳本參數開始日期、結束日期的值,獲得起止日期內的所有集文件的集合
A4-C4:循環A3,分別打開每個集文件對象,根據文件創建游標,其中cursor()函數使用@b選項代表從集文件中讀取。
D4:將多個游標對象保存到B1預留的序列中
A5:利用集算器提供的多路游標概念,把數據結構相同的多個游標合并成一個游標使用。使用時,多路游標采用并行計算來處理各個游標的數據,可以通過設置cs.mcursor(n) 函數中的n來決定并行數,當n空缺時,將按默認自動設置并行數。
A11:最后返回結果集給報表工具使用,而結果集的計算過程A6到A10與前面一個集文件時完全一樣。
利用集算器完成了數據查詢工作后,可以在報表中直接將集算器設置為數據源,和使用數據庫一樣簡單地完成報表呈現,具體做法包括:
1、在報表中定義參數(Bfiledate、Efiledate),
2、設置集算器數據集,并傳遞報表參數,
3、設計報表表樣
如下圖所示。隨后,輸入參數計算,即可得到希望的報表了。
如果再結合文章<<秒級展現的百萬級大清單報表怎么做>>,那么基本上就可以輕松應對項目中遇到的各類大數據集報表、大清單列表了。
1、簡易版、輕量級ETL
集算器是獨立的計算引擎,搭配上定時執行程序,很容易就能實現簡單、輕量級的ETL功能。
2、高性價比、高性能
無需構建數倉,很好的解決關系型數據庫中數據量大而導致的報表慢的難題。
3、不影響原有系統構架、實現簡單、易維護
使用潤乾集算器的集文件存儲大表數據,獨立于原有系統構架,將原有數據水平切割,顯著提高查詢效率,不影響業務操作。
4、降低應用耦合度
集算器腳本、集文件、報表模板等可以隨應用一起管理和維護,完全和數據庫解耦合,數據管理因此變得簡單清晰。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





