溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行RNN總結及sin與cos擬合應用,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一、RNN總結
一個簡單的RNN模型由輸入層,一個隱藏層,一個輸出層組成。
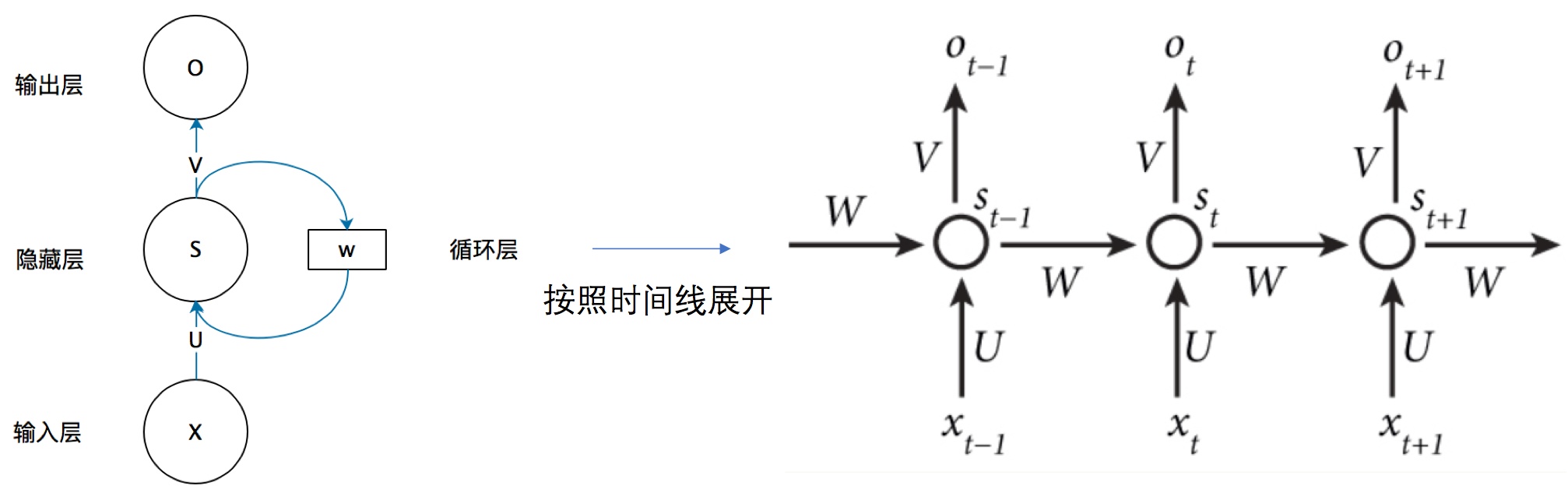
我們給出這個抽象圖對應的具體圖,能夠很清楚的看到,上一時刻的隱藏層是如何影響當前時刻的隱藏層的。

基于RNN還可以繼續擴展到雙向循環神經網絡,深度循環神經網絡。RNN公式如下: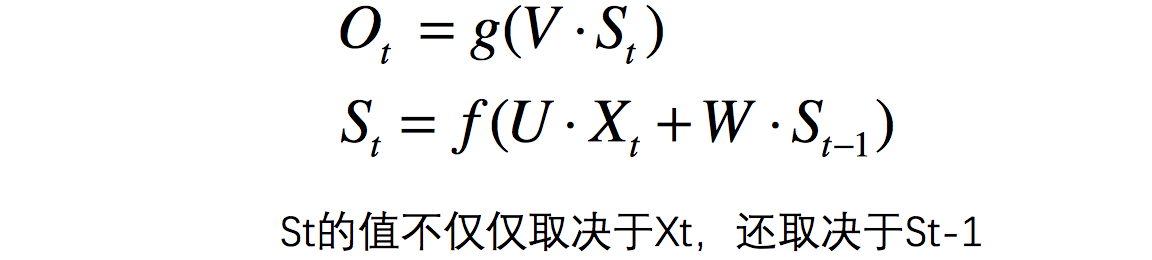
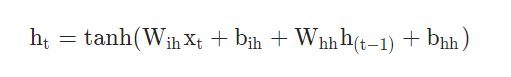
定義RNN類,代碼如下:
from torch import nn class RNN(nn.Module): def __init__(self): super(RNN, self).__init__() self.rnn = nn.RNN( input_size=INPUT_SIZE, # The number of expected features in the input `x` hidden_size=32, # The number of features in the hidden state `h` num_layers=1, # Number of recurrent layers batch_first=True # batch維度是否在前,If ``True``, tensors as `(batch, seq, feature)` ) self.out = nn.Linear(32, 1) # 線性變換 def forward(self, x, h_state): out, h_state = self.rnn(x, h_state) return out, h_state
Tips: 1. RNN的訓練算法是BPTT,它的基本原理核BP算法一致,包含同樣的三個步驟:1) 前向計算每個神經元的輸出值;2)反向計算每個神經元的誤差項?_j值,它是誤差函數E對神經元j的加權輸出net_j的偏導數;3)計算每個權重的梯度。
2. RNN的梯度消失核爆炸,根據公式的指數形式,β大于或小于1都將造成梯度消失核爆炸問題。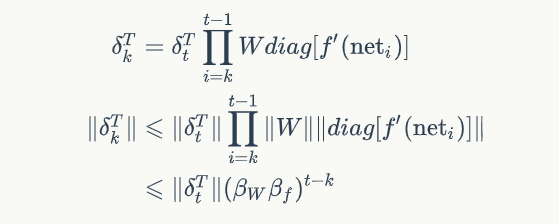
如何避免:1) 梯度爆炸:設置一個梯度閾值,當梯度超過這個閾值的時候可以直接截取 (Gradient Clipping(pytorch nn.utils.clip_grad_norm )) ;好的參數初始化方式,如He初始化; 非飽和的激活函數(如 ReLU) ; 批量規范化(Batch Normalization); LSTM 。2)梯度消失:改進網絡LSTM,加入了forget gate。
二、sin與cos擬合應用
函數sin擬合為cos,模型黑盒子類似sin(π/2+α)= cosα
import torch from torch import nn import numpy as np import matplotlib.pyplot as plt # 定義超參數 TIME_STEP = 10 INPUT_SIZE = 1 learning_rate = 0.001 class RNN(nn.Module): def __init__(self): super(RNN, self).__init__() self.rnn = nn.RNN( input_size=INPUT_SIZE, hidden_size=32, num_layers=1, batch_first=True ) self.out = nn.Linear(32, 1) def forward(self, x, h_state): # r_out.shape:seq_len,batch,hidden_size*num_direction(1,10,32) r_out, h_state = self.rnn(x, h_state) out = self.out(r_out).squeeze() return out, h_state rnn = RNN() criterion = nn.MSELoss() optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate) h_state = None plt.figure(1, figsize=(12, 5)) plt.ion() # 開啟動態交互 for step in range(100): start, end = step * np.pi, (step + 1) * np.pi steps = np.linspace(start, end, TIME_STEP, dtype=np.float32, endpoint=False) x_np = np.sin(steps) # x_np.shape: 10 y_np = np.cos(steps) # y_np.shape: 10 x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis]) # x.shape: 1,10,1 y = torch.from_numpy(y_np) # y.shape: 10 prediction, h_state = rnn(x, h_state) h_state = h_state.data loss = criterion(prediction, y) optimizer.zero_grad() loss.backward() optimizer.step() plt.plot(steps, y_np.flatten(), 'r-') plt.plot(steps, prediction.data.numpy().flatten(), 'b-') plt.draw() plt.pause(.05) plt.ioff() plt.show()
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





