溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark Adaptive Execution調研的示例分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
在Spark SQL中,我們可以通過spark.sql.shuffle.partition來設置shuffle后的partition數量,默認值是200。shuffle partition的數量等同于下一Stage的Reduce Task的數量。因為shuffle的原因,這些Task處理的數據量殘差不齊,大的可能很大,小的可能很小。而Stage的完成又取決于最慢的那個Task,其他的Task可能早早完成,在那等待。如果沒有開啟動態資源,這勢必會造成集群資源上的浪費。即使開啟了動態資源,頻繁的kill Executor和申請新的Executor一樣可能會帶來性能損耗。
雖然說我們可以認為設置shuffle partition數量,但是我們還是無法給出一個對所有任務來說都是最優的值,因為每個任務的數據和shuffle情況都不一樣。
如果這個值調整的太大可能會導致大量的Task,大量的Task就意味著Task調度開銷以及資源調度開銷(如果開啟了動態資源)。
另外,如果這個Stage最后要輸出,也會造成大量的小文件存在hdfs上。
大量的小文件就意味著集群的namenode需要承受更大的壓力
如果這個值調整的太小,就會導致每個Task處理的數據量變大,可能會導致OOM的問題。
就算不發生OOM,Task的處理性能我們也不能接受
因此,現階段Shuffle partition數量只能針對不同的任務不斷的去優化調整,才能得到一個針對這個任務的最優值。但這個在實際的開發中是很難做到的(除非性能太差,否則大多數的spark job開發人員并不會主動去做這種優化)。
所有,有沒有一種辦法,可以讓我們在執行過程中動態的設置shuffle partition數量,讓其達到一個近似最優值呢?
我們都知道,shuffle是一個很耗性能的操作。通過避免不必要的shuffle也能帶上一定的性能提升。最常見的做法就是在大小表做Join時,將小表提前加載進內存,之后直接使用內存的數據進行join,這樣就少了shuffle帶來的性能損耗了。這種做法就是MapJoin,在Spark中,也叫做BroadcastHashJoin。原理是將小表數據以broadcast變量加載到內存,然后廣播到各個Executor上,直接在map中做join。在Spark中,可以通過spark.sql.autoBroadcastJoinThreshold來設置啟動BroadcastHashJoin的閥值,默認是10MB。
SparkSQL在執行過中,在經過邏輯優化時,會估算是否要開啟BroadcastHashJoin。但是這種優化對于復雜的SQL效果并不明顯,因為復雜SQL會產生大量的Stage,spark優化程序很難準確的估算各個Stage的數據量來判斷是否要開啟BroadcastHashJoin。下面是網上的一張圖:
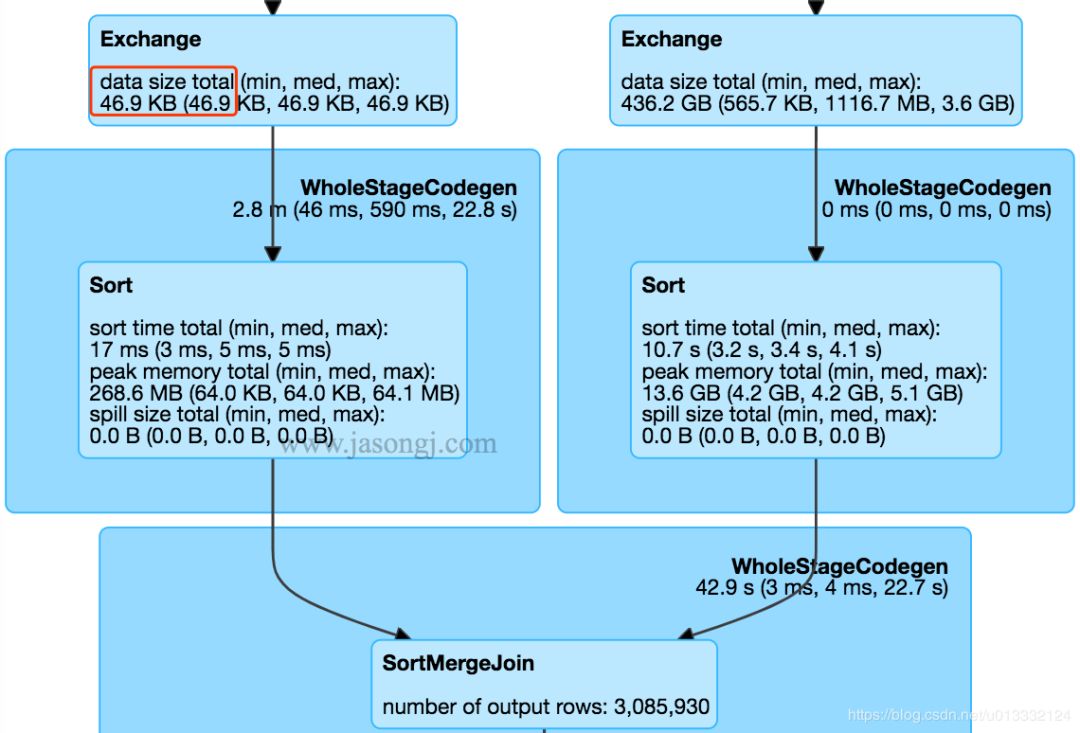
圖中左邊的Stage的數據量只有46.9KB,完全可以優化成BroadcastHashJoin。然而Spark使用的還是常規的SortMergeJoin(也就是Shuffle)。
這個問題主要還是在邏輯優化時無法準確的估算數據量導致的,那么我們是否可以在執行過程中根據數據量動態的去調整執行計劃來解決這個問題呢?
不管是mapreduce還是spark,都可能存在數據傾斜問題。數據傾斜是某一些partition的數據量遠大于其他的partition,數據量大的那個partition處理速度就會拖慢整個任務的處理速度(很可能所有的task都處理完了,只剩下一個task還在處理)。對于數據傾斜問題,我們也有多種解決辦法。比如:
如果partition數據從外界獲取,就保證外界輸入的數據是可以Split的,并保證各個Split后的塊是均衡的。
比如保證Kafka的各個partition數據均衡,讀取一個目錄時,保證下面的文件大小是均衡的等等
如果是shuffle partition,可以通過調整shuffle partition數量來避免某個shuffle partition數據量特別大
如果存在一個Key的數據量非常大,調整shuffle partition數量也沒辦法很好的規避數據傾斜問題。
就可以對Key加一些前綴或者后綴來分散數據
從shuffle的角度出發,如果兩個join的表中有一個表是小表,可以優化成BroadcastHashJoin來消除shuffle從而消除shuffle引起的數據傾斜問題
但是上面這些解決方案都是針對單一任務進行調優,沒有一個解決方案可以有效的解決所有的數據傾斜問題。
對于這種問題,我們是不是可以在執行過程中,通過判斷shuffle write后各個partition的數據量,動態的調整后面的執行計劃。比如對于存在數據傾斜的分區,我們是否可以開啟多個task處理,之后再將處理的結果做union?
Shuffle的過程是先通過Shuffle Write將各個分區的數據寫到磁盤,之后另外一個Stage通過Shuffle Read來讀取這些數據。那么我們其實可以在開啟下一個Stage前先計算好Shuffle Write產生的各個分區的數據量是多少,之后對于那些比較小的分區,將它們當成一個分區來處理。
一般情況下,一個分區是由一個task來處理的。經過優化,我們可以安排一個task處理多個分區,這樣,我們就可以保證各個分區相對均衡,不會存在大量數據量很小的partitin了。
比如Shuffle Write外我們檢測到有5個partition,數據量大小分別是64M、1M、2M、20M、4M。如果沒有進行優化,會開啟5個task來處理,要等64M的那個partiiton處理完后整個Stage才算完成。經過優化后,我們可以1M、2M、20M、4M這些分區都交給一個task來處理。這樣,總共就只有兩個task,但是整個stage的處理速度并不會比之前的慢,還少了3個task所需要的資源損耗。
目前只會合并連在一起的那些partition,主要是為了保證順序讀,提高磁盤IO性能
可以通過配置spark.sql.adaptive.shuffle.targetPostShuffleInputSize來設置合并的閥值,默認為64M
只會合并小的分區,太大的分區并不會進行拆分
spark.sql.adaptive.enabled=true:啟動Adaptive Execution。
通過spark.sql.adaptive.shuffle.targetPostShuffleInputSize可以設置shuffle后每個partition的目標數據量。一個Task加起來處理的所有分區的數據量不會超過個閥值。
還是在Shuffle Write之后,我們可以觀察兩個Stage輸出的數據量。如果有一個Stage數據量明顯比較小,可以轉換成BroadcastHashJoin,那么我們就可以動態的去調整執行計劃。
雖然shuffle write的數據已經輸出到磁盤上,這時候我們如果開啟了動態調整執行計劃,shuffle read改成BroadcastHashJoin。假設表A(1M)和表B(4G)做join時,并已經進行了Shuffle Write,轉換成BroadcastHashJoin的過程如下:
將表A的數據加載成broadcast
假設上游表B有5個partition,那么此時下游Stage也創建對應5個reduce task,每個reduce task都讀取對應上游partition的shuffle write生成的文件,然后在讀取過程中從內存讀取表A的數據進行join
因為下游的Reduce Task可以直接發到表B Shuffle Write文件所在的Executor上,此時讀取數據是直接讀取磁盤文件了,避開了網絡IO的開銷,性能會比原先的shuffle read快很多。
spark.sql.adaptive.enabled和spark.sql.adaptive.join.enabled 都設置為 true。spark.sql.adaptiveBroadcastJoinThreshold 設置了 SortMergeJoin 轉 BroadcastJoin 的閾值。如果不設置該參數,該閾值與 spark.sql.autoBroadcastJoinThreshold 的值相等
還是在Shuffle Write之后解決問題。一樣是獲取到shuffle Write后各個partition的數據量,根據一定算法算出哪些partition數據超標,出現傾斜。
對于那些存在大量小數據的partiiton,我們可以通過合并來解決問題(一個task處理多個partition的數據)。那對于這種數據量特別大的partition,我們完全可以反其道而行,用多個task來處理這個partition。
開啟自動處理數據傾斜后,在執行過程中,spark會自動找出那些出現傾斜的partiiton,然后用多個task來處理這個partition,之后再將這些task的處理結果進行union。
比如表A和表B做join,表A在shuffle write完,partition 0有4G的數據,其他partition都只有1,200M。這時候我們可以開啟多個task,每個task讀取幾個上游mapper生成的partition 0的數據,然后和表B的partition 0做join,最后這個幾個task再進行union。這樣雖然表B的partition 0要被多次讀取,但是并行處理帶來的收益還是要高過這些消耗的。
spark.sql.adaptive.skewedJoin.enabled 設置為 true
spark.sql.adaptive.skewedPartitionMaxSplits 控制處理一個傾斜 Partition 的 Task 個數上限,默認值為 5
spark.sql.adaptive.skewedPartitionRowCountThreshold ,partition的條數如果少于這個值,數據量再大也不會被當成是傾斜的partition。
默認是1000W
spark.sql.adaptive.skewedPartitionSizeThreshold,被認定為是傾斜partiiton的大小下限。
默認是64M
spark.sql.adaptive.skewedPartitionFactor,傾斜因子。
如果一個 Partition 的大小大于 spark.sql.adaptive.skewedPartitionSizeThreshold 的同時大于各 Partition 大小中位數與該因子的乘積,或者行數大于 spark.sql.adaptive.skewedPartitionRowCountThreshold 的同時大于各 Partition 行數中位數與該因子的乘積,則它會被視為傾斜的 Partition
關于Spark Adaptive Execution調研的示例分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





