溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark 3.0如何提高SQL工作負載的性能,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
AQE最初是在Spark 2.4中引入的,但隨著Spark 3.0的發展,它變得更加強大。盡管Cloudera建議在我們交付Spark 3.1之前等待在生產中使用它,但您現在可以使用AQE開始在Spark 3.0中進行評估。
首先,讓我們看一下AQE解決的問題類型。
初始催化劑設計中的缺陷
下圖表示使用DataFrames執行簡單的按組分組查詢時發生的分布式處理的類型。
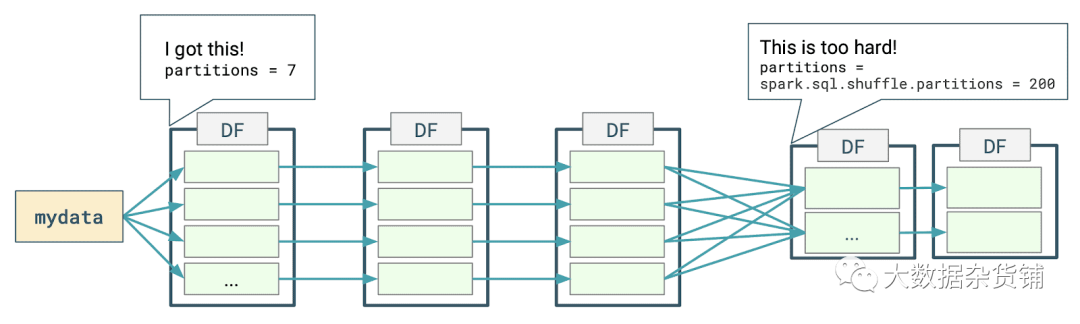
Spark為第一階段確定適當的分區數量,但對于第二階段,使用默認的幻數200。
不好的原因有三個:
200不可能是理想的分區數,而分區數是影響性能的關鍵因素之一;
如果將第二階段的輸出寫入磁盤,則可能會得到200個小文件。
優化及其缺失會產生連鎖反應:如果在第二階段之后繼續進行處理,您可能會錯過進行更多優化的潛在機會。
您可以做的是在執行類似于以下語句的查詢之前,手動為此shuffle設置此屬性的值:
spark.conf.set(“ spark.sql.shuffle.partitions”,“ 2”)
這也帶來了一些挑戰:
在每次查詢之前都要設置此屬性
這些值將隨著數據的發展而過時
此設置將應用于查詢中的所有Shuffle操作
在上一個示例的第一階段之前,數據的分布和數量是已知的,Spark可以得出合理的分區數量值。但是,對于第二階段,此信息尚不知道要獲得執行第一階段的實際處理所要付出的代價:因此,求助于幻數。
自適應查詢執行設計原理
AQE的主要思想是使執行計劃不是最終的,并允許在每個階段的邊界進行審核。因此,執行計劃被分解為由階段界定的新的“查詢階段”抽象。
催化劑現在停在每個階段的邊界,以根據中間數據上可用的信息嘗試并應用其他優化。
因此,可以將AQE定義為Spark Catalyst之上的一層,它將動態修改Spark計劃。
有什么缺點嗎?有一些,但它們很小:
執行在Spark的每個階段邊界處停止,以查看其計劃,但這被性能提升所抵消。
Spark UI更加難以閱讀,因為Spark為給定的應用程序創建了更多的作業,而這些作業不會占用您設置的Job組和描述。

Shuffle分區的自適應數目
自Spark 2.4起,AQE的此功能已可用。
要啟用它,您需要將spark.sql.adaptive.enabled設置為true ,該參數默認值為false 。啟用AQE后,隨機調整分區的數量將自動調整,不再是默認的200或手動設置的值。
這是啟用AQE之前和之后第一個TPC-DS查詢的執行結果:

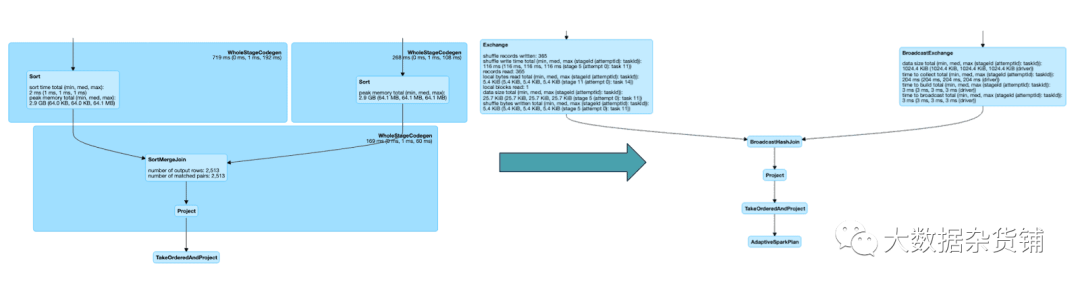
動態將排序合并聯接轉換為廣播聯接
當任何聯接端的運行時統計信息小于廣播哈希聯接閾值時,AQE會將排序合并聯接轉換為廣播哈希聯接。
這是啟用AQE之前和之后第二個TPC-DS查詢執行的最后階段:
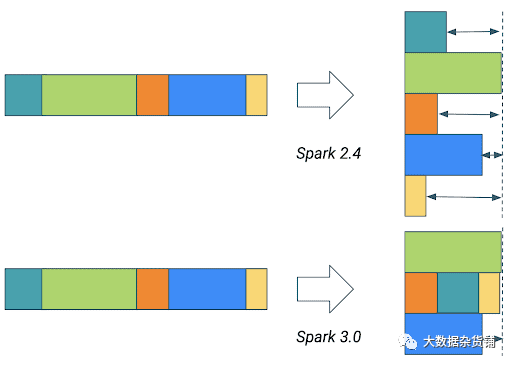
動態合并shuffle分區
如果隨機播放分區的數量大于按鍵分組的數量,則由于鍵的不平衡分配,會浪費很多CPU周期
當兩個
spark.sql.adaptive.enabledspark.sql.adaptive.coalescePartitions.enabled
設置為true ,Spark將根據以下內容合并連續的shuffle分區
設置為spark.sql.adaptive.advisoryPartitionSizeInBytes指定的目標大小,以避免執行過多的小任務。
動態優化傾斜的連接
傾斜是分布式處理的絆腳石。它實際上可能會使您的處理暫停數小時:
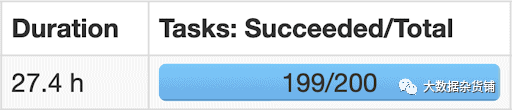
如果不進行優化,則執行連接所需的時間將由最大的分區來定義。

因此,傾斜聯接優化將使用spark.sql.adaptive.advisoryPartitionSizeInBytes指定的值將分區A0劃分為子分區,并將它們中的每一個聯接到表B的對應分區B0。
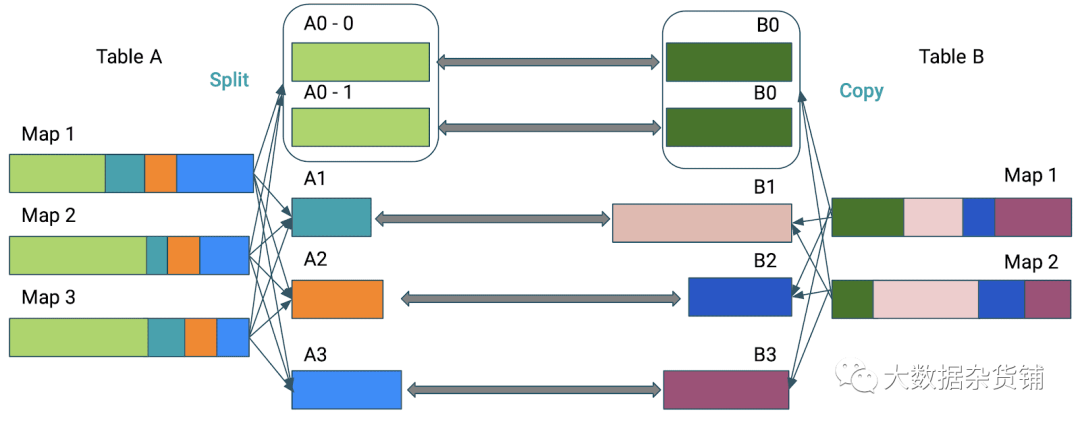
因此,您需要向AQE提供您的傾斜定義。
這涉及兩個屬性:
spark.sql.adaptive.skewJoin.skewedPartitionFactor是相對的:如果分區的大小大于此因子乘以中位數分區大小且也大于,則認為該分區是傾斜的
spark.sql.adaptive.skewedPartitionThresholdInBytes ,這是絕對的:這是閾值,低于該閾值將被忽略。
動態分區修剪
動態分區修剪(DPP)的想法是最有效的優化技術之一:僅讀取所需的數據。DPP不是AQE的一部分,實際上,必須禁用AQE才能進行DPP。從好的方面來說,這允許將DPP反向移植到Spark 2.4 for CDP。
該優化在邏輯計劃和物理計劃上均實現。
在邏輯級別上,識別維度過濾器,并通過連接傳播到掃描的另一側。
然后,在物理級別上,過濾器在維度側執行一次,結果被廣播到主表,在該表中也應用了過濾器。
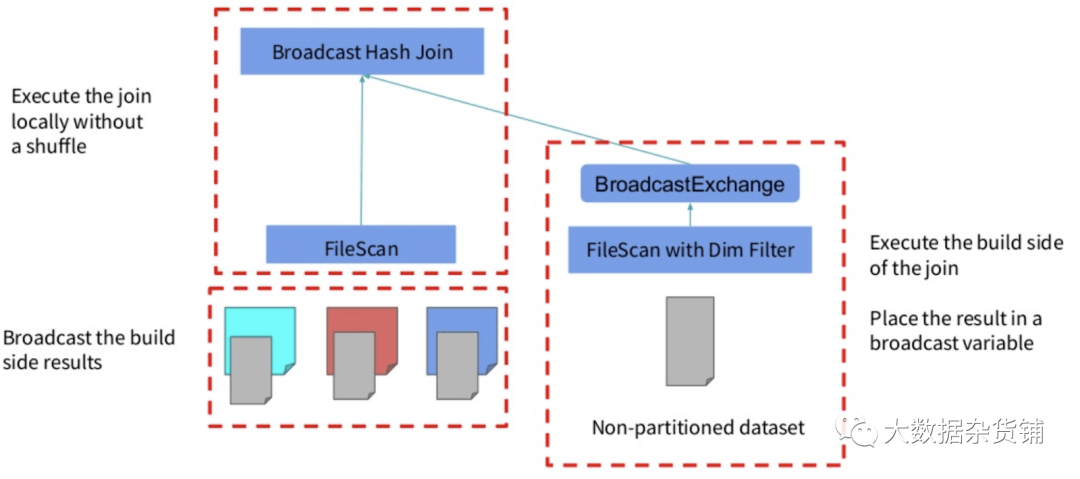
如果禁用spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly,則DPP實際上可以與其他類型的聯接一起使用(例如,SortMergeJoin)。
在那種情況下,Spark會估計DPP過濾器是否真正提高了查詢性能。
DPP可以極大地提高高度選擇性查詢的性能,例如,如果您的查詢從5年的數據中的一個月中篩選出來。
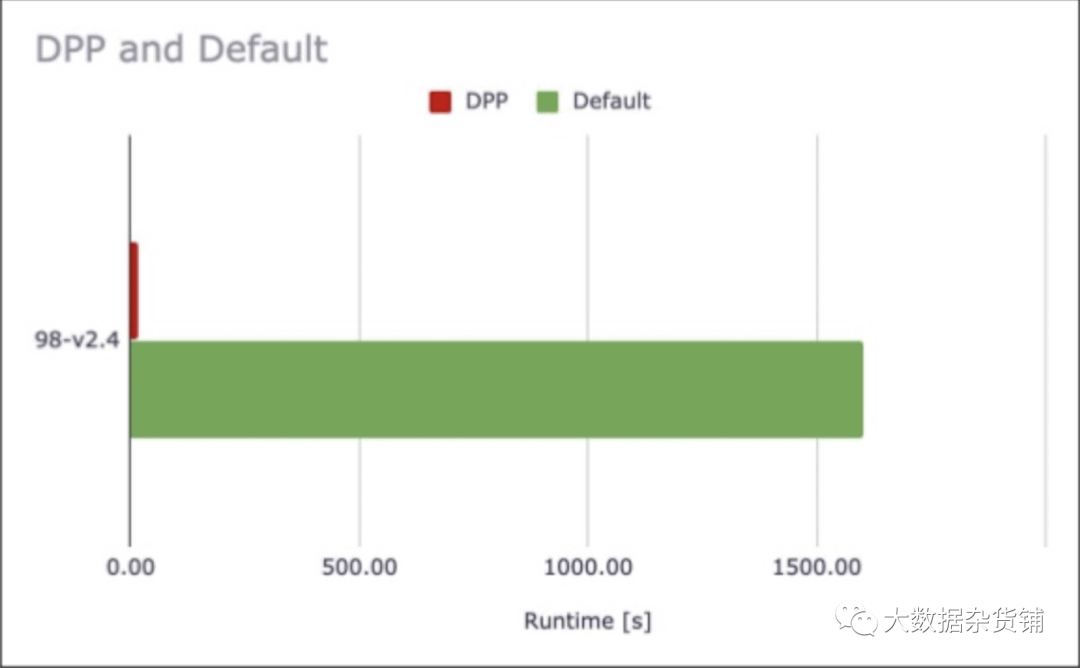
并非所有查詢的性能都有如此顯著的提高,但是在99個TPC-DS查詢中,有72個受到DPP的積極影響。
Spark距其最初的核心范例還有很長的路要走:在靜態數據集上懶惰地執行優化的靜態計劃。
靜態數據集部分受到流技術的挑戰:Spark團隊首先創建了一個基于RDD的笨拙設計,然后提出了一個涉及DataFrames的更好的解決方案。
靜態計劃部分受到SQL和Adaptive Query Execution框架的挑戰,從某種意義上說,結構化流對于初始流庫是什么:它應該一直是一個優雅的解決方案。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





