溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Kafka對page cache與buffer cache的關系是什么,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
前言
關于Kafka的一個靈魂拷問:它為什么這么快?
或者說,為什么它能做到如此大的吞吐量和如此低的延遲?
有很多文章已經對這個問題給出了回答,但只重點研究其中的一個方向,即對page cache的使用。先簡單地認識一下Linux系統中的page cache(順便也認識一下buffer cache)。
執行free命令,注意到會有兩列名為buffers和cached,也有一行名為“-/+ buffers/cache”。
~ free -m
total used free shared buffers cached
Mem: 128956 96440 32515 0 5368 39900
-/+ buffers/cache: 51172 77784
Swap: 16002 0 16001其中,cached列表示當前的頁緩存(page cache)占用量,buffers列表示當前的塊緩存(buffer cache)占用量。用一句話來解釋:page cache用于緩存文件的頁數據,buffer cache用于緩存塊設備(如磁盤)的塊數據。頁是邏輯上的概念,因此page cache是與文件系統同級的;塊是物理上的概念,因此buffer cache是與塊設備驅動程序同級的。
page cache與buffer cache的共同目的都是加速數據I/O:寫數據時首先寫到緩存,將寫入的頁標記為dirty,然后向外部存儲flush,也就是緩存寫機制中的write-back(另一種是write-through,Linux未采用);讀數據時首先讀取緩存,如果未命中,再去外部存儲讀取,并且將讀取來的數據也加入緩存。操作系統總是積極地將所有空閑內存都用作page cache和buffer cache,當內存不夠用時也會用LRU等算法淘汰緩存頁。
在Linux 2.4版本的內核之前,page cache與buffer cache是完全分離的。但是,塊設備大多是磁盤,磁盤上的數據又大多通過文件系統來組織,這種設計導致很多數據被緩存了兩次,浪費內存。所以在2.4版本內核之后,兩塊緩存近似融合在了一起:如果一個文件的頁加載到了page cache,那么同時buffer cache只需要維護塊指向頁的指針就可以了。只有那些沒有文件表示的塊,或者繞過了文件系統直接操作(如dd命令)的塊,才會真正放到buffer cache里。因此,我們現在提起page cache,基本上都同時指page cache和buffer cache兩者,本文之后也不再區分,直接統稱為page cache。
下圖近似地示出32-bit Linux系統中可能的一種page cache結構,其中block size大小為1KB,page size大小為4KB。
page cache中的每個文件都是一棵基數樹(radix tree,本質上是多叉搜索樹),樹的每個節點都是一個頁。根據文件內的偏移量就可以快速定位到所在的頁。
接下來就可以把Kafka扯進來了。
Kafka為什么不自己管理緩存,而非要用page cache?原因有如下三點:
JVM中一切皆對象,數據的對象存儲會帶來所謂object overhead,浪費空間;
如果由JVM來管理緩存,會受到GC的影響,并且過大的堆也會拖累GC的效率,降低吞吐量;
一旦程序崩潰,自己管理的緩存數據會全部丟失。
Kafka三大件(broker、producer、consumer)與page cache的關系可以用下面的簡圖來表示。
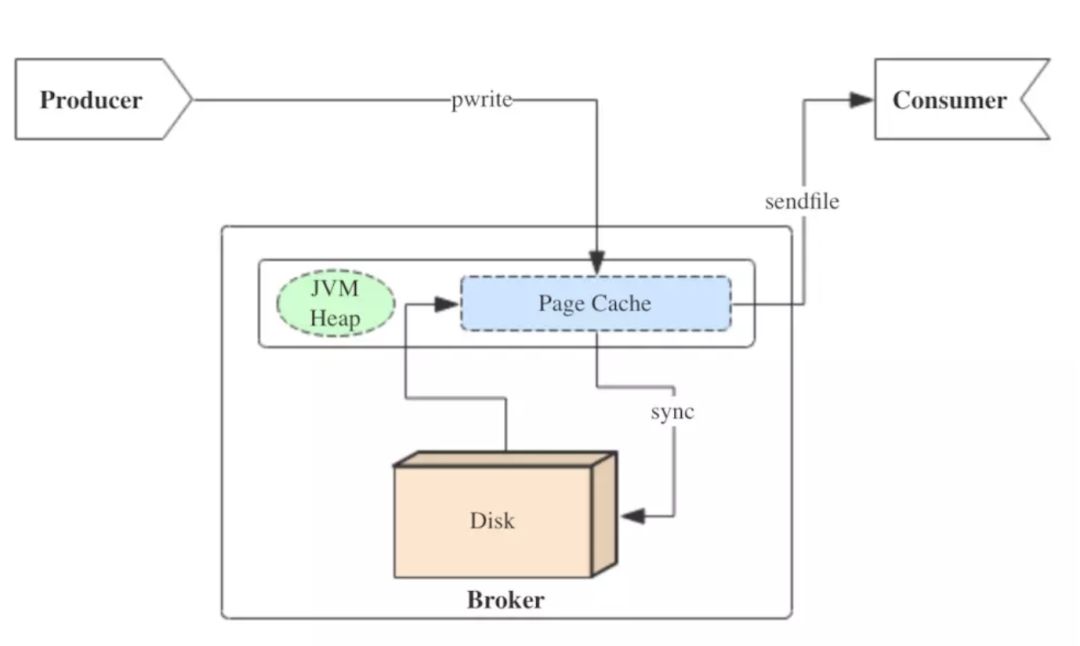
producer生產消息時,會使用pwrite()系統調用【對應到Java NIO中是FileChannel.write() API】按偏移量寫入數據,并且都會先寫入page cache里。consumer消費消息時,會使用sendfile()系統調用【對應FileChannel.transferTo() API】,零拷貝地將數據從page cache傳輸到broker的Socket buffer,再通過網絡傳輸。
圖中沒有畫出來的還有leader與follower之間的同步,這與consumer是同理的:只要follower處在ISR中,就也能夠通過零拷貝機制將數據從leader所在的broker page cache傳輸到follower所在的broker。
同時,page cache中的數據會隨著內核中flusher線程的調度以及對sync()/fsync()的調用寫回到磁盤,就算進程崩潰,也不用擔心數據丟失。另外,如果consumer要消費的消息不在page cache里,才會去磁盤讀取,并且會順便預讀出一些相鄰的塊放入page cache,以方便下一次讀取。
由此我們可以得出重要的結論:如果Kafka producer的生產速率與consumer的消費速率相差不大,那么就能幾乎只靠對broker page cache的讀寫完成整個生產-消費過程,磁盤訪問非常少。并且Kafka持久化消息到各個topic的partition文件時,是只追加的順序寫,充分利用了磁盤順序訪問快的特性,效率高。
注意事項與相關參數
對于單純運行Kafka的集群而言,首先要注意的就是為Kafka設置合適(不那么大)的JVM堆大小。從上面的分析可知,Kafka的性能與堆內存關系并不大,而對page cache需求巨大。根據經驗值,為Kafka分配5~8GB的堆內存就已經足足夠用了,將剩下的系統內存都作為page cache空間,可以最大化I/O效率。
另一個需要特別注意的問題是lagging consumer,即那些消費速率慢、明顯落后的consumer。它們要讀取的數據有較大概率不在broker page cache中,因此會增加很多不必要的讀盤操作。比這更壞的是,lagging consumer讀取的“冷”數據仍然會進入page cache,污染了多數正常consumer要讀取的“熱”數據,連帶著正常consumer的性能變差。在生產環境中,這個問題尤為重要。
前面已經說過,page cache中的數據會隨著內核中flusher線程的調度寫回磁盤。與它相關的有以下4個參數,必要時可以調整。
/proc/sys/vm/dirty_writeback_centisecs:flush檢查的周期。單位為0.01秒,默認值500,即5秒。每次檢查都會按照以下三個參數控制的邏輯來處理。
/proc/sys/vm/dirty_expire_centisecs:如果page cache中的頁被標記為dirty的時間超過了這個值,就會被直接刷到磁盤。單位為0.01秒。默認值3000,即半分鐘。
/proc/sys/vm/dirty_background_ratio:如果dirty page的總大小占空閑內存量的比例超過了該值,就會在后臺調度flusher線程異步寫磁盤,不會阻塞當前的write()操作。默認值為10%。
/proc/sys/vm/dirty_ratio:如果dirty page的總大小占總內存量的比例超過了該值,就會阻塞所有進程的write()操作,并且強制每個進程將自己的文件寫入磁盤。默認值為20%。
由此可見,調整空間比較靈活的是參數2、3,而盡量不要達到參數4的閾值,代價太大了。
以上就是Kafka對page cache與buffer cache的關系是什么,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





