溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Kafka的高性能吞吐的原理是什么”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Kafka的高性能吞吐的原理是什么”吧!
Kafka作為時下開源消息系統,被廣泛地應用在數據緩沖、異步通信、匯集日志、系統解耦等方面。相比較于RocketMQ等其他常見消息系統,Kafka在保障了大部分功能特性的同時,還提供了讀寫性能。
本文將針對Kafka性能方面進行簡單分析,首先簡單介紹一下Kafka的架構和涉及到的名詞:
Topic:用于劃分Message的邏輯概念,一個Topic可以分布在多個Broker上。
Partition:是Kafka中橫向擴展和一切并行化的基礎,每個Topic都至少被切分為1個Partition。
Offset:消息在Partition中的編號,編號順序不跨Partition。
Consumer:用于從Broker中取出/消費Message。
Producer:用于往Broker中發送/生產Message。
Replication:Kafka支持以Partition為單位對Message進行冗余備份,每個Partition都可以配置至少1個Replication(當僅1個Replication時即僅該Partition本身)。
Leader:每個Replication集合中的Partition都會選出一個唯一的Leader,所有的讀寫請求都由Leader處理。其他Replicas從Leader處把數據更新同步到本地,過程類似大家熟悉的MySQL中的Binlog同步。
Broker:Kafka中使用Broker來接受Producer和Consumer的請求,并把Message持久化到本地磁盤。每個Cluster當中會選舉出一個Broker來擔任Controller,負責處理Partition的Leader選舉,協調Partition遷移等工作。
ISR(In-Sync Replica):是Replicas的一個子集,表示目前Alive且與Leader能夠“Catch-up”的Replicas集合。由于讀寫都是首先落到Leader上,所以一般來說通過同步機制從Leader上拉取數據的Replica都會和Leader有一些延遲(包括了延遲時間和延遲條數兩個維度),任意一個超過閾值都會把該Replica踢出ISR。每個Partition都有它自己獨立的ISR。
以上幾乎是我們在使用Kafka的過程中可能遇到的所有名詞,同時也無一不是最核心的概念或組件,感覺到從設計本身來說,Kafka還是足夠簡潔的。這次本文圍繞Kafka優異的吞吐性能,逐個介紹一下其設計與實現當中所使用的各項“黑科技”。
Broker
不同于Redis和MemcacheQ等內存消息隊列,Kafka的設計是把所有的Message都要寫入速度低容量大的硬盤,以此來換取更強的存儲能力。實際上,Kafka使用硬盤并沒有帶來過多的性能損失,“規規矩矩”的抄了一條“近道”。
首先,說“規規矩矩”是因為Kafka在磁盤上只做Sequence I/O,由于消息系統讀寫的特殊性,這并不存在什么問題。關于磁盤I/O的性能,引用一組Kafka官方給出的測試數據(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通過只做Sequence I/O的限制,規避了磁盤訪問速度低下對性能可能造成的影響。
接下來我們再聊一聊Kafka是如何“抄近道的”。
首先,Kafka重度依賴底層操作系統提供的PageCache功能。當上層有寫操作時,操作系統只是將數據寫入PageCache,同時標記Page屬性為Dirty。當讀操作發生時,先從PageCache中查找,如果發生缺頁才進行磁盤調度,最終返回需要的數據。實際上PageCache是把盡可能多的空閑內存都當做了磁盤緩存來使用。同時如果有其他進程申請內存,回收PageCache的代價又很小,所以現代的OS都支持PageCache。
使用PageCache功能同時可以避免在JVM內部緩存數據,JVM為我們提供了強大的GC能力,同時也引入了一些問題不適用與Kafka的設計。
如果在Heap內管理緩存,JVM的GC線程會頻繁掃描Heap空間,帶來不必要的開銷。如果Heap過大,執行一次Full GC對系統的可用性來說將是極大的挑戰。
所有在在JVM內的對象都不免帶有一個Object Overhead(千萬不可小視),內存的有效空間利用率會因此降低。
所有的In-Process Cache在OS中都有一份同樣的PageCache。所以通過將緩存只放在PageCache,可以至少讓可用緩存空間翻倍。
如果Kafka重啟,所有的In-Process Cache都會失效,而OS管理的PageCache依然可以繼續使用。
PageCache還只是第一步,Kafka為了進一步的優化性能還采用了Sendfile技術。在解釋Sendfile之前,首先介紹一下傳統的網絡I/O操作流程,大體上分為以下4步。
OS 從硬盤把數據讀到內核區的PageCache。
用戶進程把數據從內核區Copy到用戶區。
然后用戶進程再把數據寫入到Socket,數據流入內核區的Socket Buffer上。
OS 再把數據從Buffer中Copy到網卡的Buffer上,這樣完成一次發送。
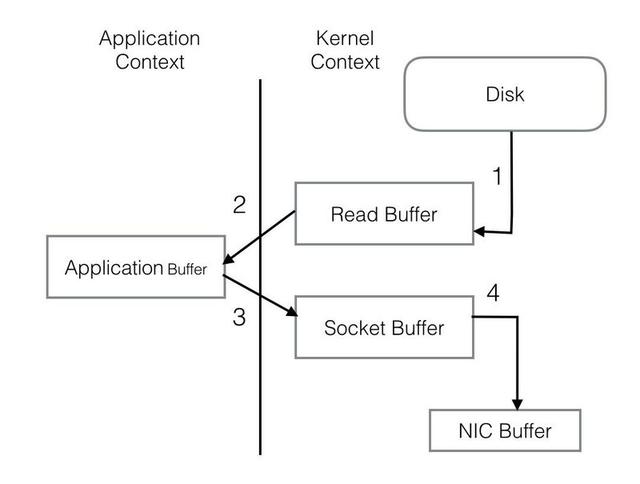
整個過程共經歷兩次Context Switch,四次System Call。同一份數據在內核Buffer與用戶Buffer之間重復拷貝,效率低下。其中2、3兩步沒有必要,完全可以直接在內核區完成數據拷貝。這也正是Sendfile所解決的問題,經過Sendfile優化后,整個I/O過程就變成了下面這個樣子。
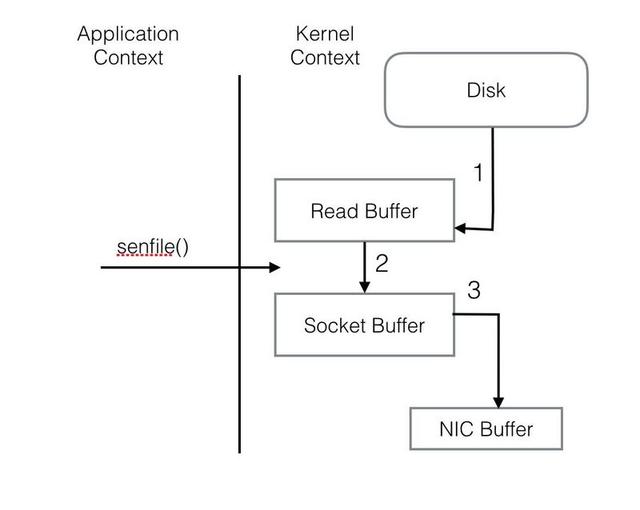
通過以上的介紹不難看出,Kafka的設計初衷是盡一切努力在內存中完成數據交換,無論是對外作為一整個消息系統,或是內部同底層操作系統的交互。如果Producer和Consumer之間生產和消費進度上配合得當,完全可以實現數據交換零I/O。這也就是我為什么說Kafka使用“硬盤”并沒有帶來過多性能損失的原因。下面是我在生產環境中采到的一些指標。
(20 Brokers, 75 Partitions per Broker, 110k msg/s)

此時的集群只有寫,沒有讀操作。10M/s左右的Send的流量是Partition之間進行Replicate而產生的。從recv和writ的速率比較可以看出,寫盤是使用Asynchronous+Batch的方式,底層OS可能還會進行磁盤寫順序優化。而在有Read Request進來的時候分為兩種情況,第一種是內存中完成數據交換。

Send流量從平均10M/s增加到了到平均60M/s,而磁盤Read只有不超過50KB/s。PageCache降低磁盤I/O效果非常明顯。
接下來是讀一些收到了一段時間,已經從內存中被換出刷寫到磁盤上的老數據。
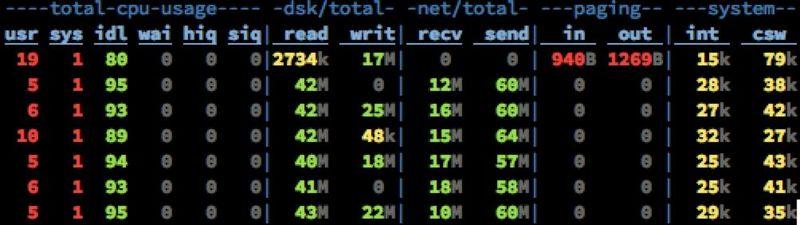
其他指標還是老樣子,而磁盤Read已經飚高到40+MB/s。此時全部的數據都已經是走硬盤了(對硬盤的順序讀取OS層會進行Prefill PageCache的優化)。依然沒有任何性能問題。
Tips
Kafka官方并不建議通過Broker端的log.flush.interval.messages和log.flush.interval.ms來強制寫盤,認為數據的可靠性應該通過Replica來保證,而強制Flush數據到磁盤會對整體性能產生影響。
可以通過調整/proc/sys/vm/dirty_background_ratio和/proc/sys/vm/dirty_ratio來調優性能。
臟頁率超過第一個指標會啟動pdflush開始Flush Dirty PageCache。
臟頁率超過第二個指標會阻塞所有的寫操作來進行Flush。
根據不同的業務需求可以適當的降低dirty_background_ratio和提高dirty_ratio。
Partition
Partition是Kafka可以很好的橫向擴展和提供高并發處理以及實現Replication的基礎。
擴展性方面。首先,Kafka允許Partition在集群內的Broker之間任意移動,以此來均衡可能存在的數據傾斜問題。其次,Partition支持自定義的分區算法,例如可以將同一個Key的所有消息都路由到同一個Partition上去。 同時Leader也可以在In-Sync的Replica中遷移。由于針對某一個Partition的所有讀寫請求都是只由Leader來處理,所以Kafka會盡量把Leader均勻的分散到集群的各個節點上,以免造成網絡流量過于集中。
并發方面。任意Partition在某一個時刻只能被一個Consumer Group內的一個Consumer消費(反過來一個Consumer則可以同時消費多個Partition),Kafka非常簡潔的Offset機制最小化了Broker和Consumer之間的交互,這使Kafka并不會像同類其他消息隊列一樣,隨著下游Consumer數目的增加而成比例的降低性能。此外,如果多個Consumer恰巧都是消費時間序上很相近的數據,可以達到很高的PageCache命中率,因而Kafka可以非常高效的支持高并發讀操作,實踐中基本可以達到單機網卡上限。
不過,Partition的數量并不是越多越好,Partition的數量越多,平均到每一個Broker上的數量也就越多。考慮到Broker宕機(Network Failure, Full GC)的情況下,需要由Controller來為所有宕機的Broker上的所有Partition重新選舉Leader,假設每個Partition的選舉消耗10ms,如果Broker上有500個Partition,那么在進行選舉的5s的時間里,對上述Partition的讀寫操作都會觸發LeaderNotAvailableException。
再進一步,如果掛掉的Broker是整個集群的Controller,那么首先要進行的是重新任命一個Broker作為Controller。新任命的Controller要從Zookeeper上獲取所有Partition的Meta信息,獲取每個信息大概3-5ms,那么如果有10000個Partition這個時間就會達到30s-50s。而且不要忘記這只是重新啟動一個Controller花費的時間,在這基礎上還要再加上前面說的選舉Leader的時間 -_-!!!!!!
此外,在Broker端,對Producer和Consumer都使用了Buffer機制。其中Buffer的大小是統一配置的,數量則與Partition個數相同。如果Partition個數過多,會導致Producer和Consumer的Buffer內存占用過大。
Tips
Partition的數量盡量提前預分配,雖然可以在后期動態增加Partition,但是會冒著可能破壞Message Key和Partition之間對應關系的風險。
Replica的數量不要過多,如果條件允許盡量把Replica集合內的Partition分別調整到不同的Rack。
盡一切努力保證每次停Broker時都可以Clean Shutdown,否則問題就不僅僅是恢復服務所需時間長,還可能出現數據損壞或其他很詭異的問題。
Producer
Kafka的研發團隊表示在0.8版本里用Java重寫了整個Producer,據說性能有了很大提升。我還沒有親自對比試用過,這里就不做數據對比了。本文結尾的擴展閱讀里提到了一套我認為比較好的對照組,有興趣的同學可以嘗試一下。
其實在Producer端的優化大部分消息系統采取的方式都比較單一,無非也就化零為整、同步變異步這么幾種。
Kafka系統默認支持MessageSet,把多條Message自動地打成一個Group后發送出去,均攤后拉低了每次通信的RTT。而且在組織MessageSet的同時,還可以把數據重新排序,從爆發流式的隨機寫入優化成較為平穩的線性寫入。
此外,還要著重介紹的一點是,Producer支持End-to-End的壓縮。數據在本地壓縮后放到網絡上傳輸,在Broker一般不解壓(除非指定要Deep-Iteration),直至消息被Consume之后在客戶端解壓。
當然用戶也可以選擇自己在應用層上做壓縮和解壓的工作(畢竟Kafka目前支持的壓縮算法有限,只有GZIP和Snappy),不過這樣做反而會意外的降低效率!!!! Kafka的End-to-End壓縮與MessageSet配合在一起工作效果最佳,上面的做法直接割裂了兩者間聯系。至于道理其實很簡單,壓縮算法中一條基本的原理“重復的數據量越多,壓縮比越高”。無關于消息體的內容,無關于消息體的數量,大多數情況下輸入數據量大一些會取得更好的壓縮比。
不過Kafka采用MessageSet也導致在可用性上一定程度的妥協。每次發送數據時,Producer都是send()之后就認為已經發送出去了,但其實大多數情況下消息還在內存的MessageSet當中,尚未發送到網絡,這時候如果Producer掛掉,那就會出現丟數據的情況。
為了解決這個問題,Kafka在0.8版本的設計借鑒了網絡當中的ack機制。如果對性能要求較高,又能在一定程度上允許Message的丟失,那就可以設置request.required.acks=0 來關閉ack,以全速發送。如果需要對發送的消息進行確認,就需要設置request.required.acks為1或-1,那么1和-1又有什么區別呢?這里又要提到前面聊的有關Replica數量問題。如果配置為1,表示消息只需要被Leader接收并確認即可,其他的Replica可以進行異步拉取無需立即進行確認,在保證可靠性的同時又不會把效率拉得很低。如果設置為-1,表示消息要Commit到該Partition的ISR集合中的所有Replica后,才可以返回ack,消息的發送會更安全,而整個過程的延遲會隨著Replica的數量正比增長,這里就需要根據不同的需求做相應的優化。
Tips
Producer的線程不要配置過多,尤其是在Mirror或者Migration中使用的時候,會加劇目標集群Partition消息亂序的情況(如果你的應用場景對消息順序很敏感的話)。
0.8版本的request.required.acks默認是0(同0.7)。
Consumer
Consumer端的設計大體上還算是比較常規的。
通過Consumer Group,可以支持生產者消費者和隊列訪問兩種模式。
Consumer API分為High level和Low level兩種。前一種重度依賴Zookeeper,所以性能差一些且不自由,但是超省心。第二種不依賴Zookeeper服務,無論從自由度和性能上都有更好的表現,但是所有的異常(Leader遷移、Offset越界、Broker宕機等)和Offset的維護都需要自行處理。
大家可以關注下不日發布的0.9 Release。開發人員又用Java重寫了一套Consumer。把兩套API合并在一起,同時去掉了對Zookeeper的依賴。據說性能有大幅度提升哦~~
感謝各位的閱讀,以上就是“Kafka的高性能吞吐的原理是什么”的內容了,經過本文的學習后,相信大家對Kafka的高性能吞吐的原理是什么這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





