溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何解析Stacking和Blending方式,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
一.Stacking思想簡介
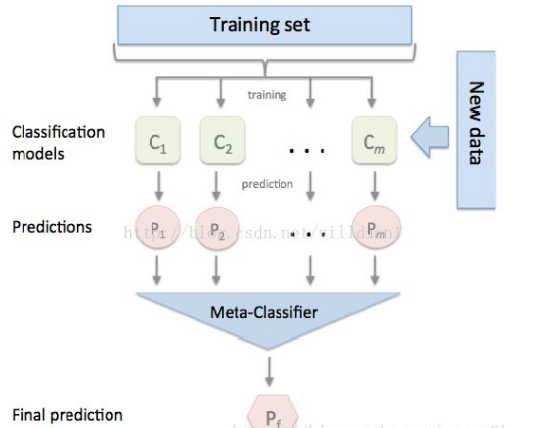
1.Stacking的思想是一種有層次的融合模型,比如我們將用不同特征訓練出來的三個GBDT模型進行融合時,我們會將三個GBDT作為基層模型,在其上在訓練一個次學習器(通常為線性模型LR),用于組織利用基學習器的答案,也就是將基層模型的答案作為輸入,讓次學習器學習組織給基層模型的答案分配權重。
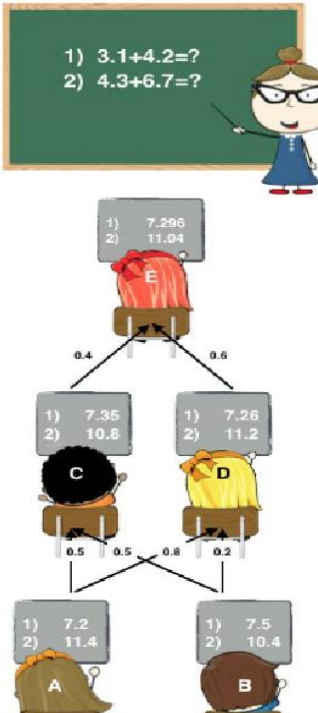
2.下圖是個簡單的例子,A、B是學習器,C、D、E是進行答案再組織的次學習器,次學習器會組織利用底層模型提供的答案。
二.Stacking過程解讀
Stacking的主要思想是訓練模型來學習使用底層學習器的預測結果,下圖是一個5折stacking中基模型在所有數據集上生成預測結果的過程,次學習器會基于模型的預測結果進行再訓練,單個基模型生成預測結果的過程是:
*首先將所有數據集生成測試集和訓練集(假如訓練集為10000,測試集為2500行),那么上層會進行5折交叉檢驗,使用訓練集中的8000條作為喂養集,剩余2000行作為驗證集(橙色)
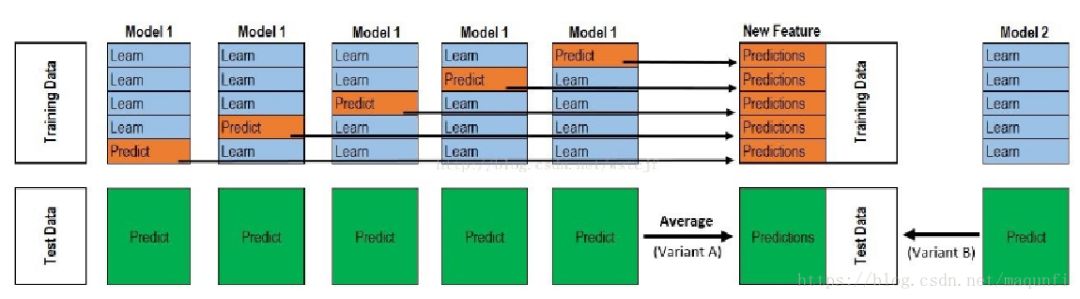
*每次驗證相當于使用了藍色的8000條數據訓練出一個模型,使用模型對驗證集進行驗證得到2000條數據,并對測試集進行預測,得到2500條數據,這樣經過5次交叉檢驗,可以得到中間的橙色的5*2000條驗證集的結果(相當于每條數據的預測結果),5*2500條測試集的預測結果。
*接下來會將驗證集的5*2000條預測結果拼接成10000行長的矩陣,標記為A1,而對于5*2500行的測試集的預測結果進行加權平均,得到一個2500一列的矩陣,標記為B1。
*上面得到一個基模型在數據集上的預測結果A1、B1,這樣當我們對3個基模型進行集成的話,相于得到了A1、A2、A3、B1、B2、B3六個矩陣。
*之后我們會將A1、A2、A3并列在一起成10000行3列的矩陣作為training data,B1、B2、B3合并在一起成2500行3列的矩陣作為testing data,讓下層學習器基于這樣的數據進行再訓練。
*再訓練是基于每個基礎模型的預測結果作為特征(三個特征),次學習器會學習訓練如果往這樣的基學習的預測結果上賦予權重w,來使得最后的預測最為準確。
以上就是Stacking的思想,進行Stacking集成同樣需要基學習器盡量保持獨立,效果相近。
三.Stacking特點
使用stacking,組合1000多個模型,有時甚至要計算幾十個小時。但是,這些怪物般的集成方法同樣有著它的用處:
(1)它可以幫你打敗當前學術界性能最好的算法
(2)我們有可能將集成的知識遷移到到簡單的分類器上
(3)自動化的大型集成策略可以通過添加正則項有效的對抗過擬合,而且并不需要太多的調參和特征選擇。所以從原則上講,stacking非常適合于那些“懶人”
(4)這是目前提升機器學習效果最好的方法,或者說是最效率的方法human ensemble learning 。
四.Stacking和Blending對比
1.Blending方式和Stacking方式很類似,相比Stacking更簡單點,兩者區別是:
*blending是直接準備好一部分10%留出集只在留出集上繼續預測,用不相交的數據訓練不同的 Base Model,將它們的輸出取(加權)平均。實現簡單,但對訓練數據利用少了。
2.blending 的優點是:比stacking簡單,不會造成數據穿越(所謂數據創越,就比如訓練部分數據時候用了全局的統計特征,導致模型效果過分的好),generalizers和stackers使用不同的數據,可以隨時添加其他模型到blender中。
3.缺點在于:blending只使用了一部分數據集作為留出集進行驗證,而stacking使用多折交叉驗證,比使用單一留出集更加穩健
4.兩個方法都挺好,看偏好了,可以一部分做Blending、一部分做Stacking。
以上就是如何解析Stacking和Blending方式,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





