溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了怎樣解析SparkStreaming和Kafka集成的兩種方式,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Spark Streaming是基于微批處理的流式計算引擎,通常是利用Spark Core或者Spark Core與Spark Sql一起來處理數據。在企業實時處理架構中,通常將Spark Streaming和Kafka集成作為整個大數據處理架構的核心環節之一。
針對不同的Spark、Kafka版本,集成處理數據的方式分為兩種:Receiver based Approach和Direct Approach,不同集成版本處理方式的支持,可參考下圖:
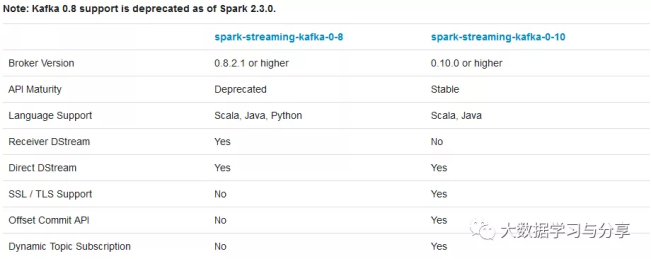
基于receiver的方式是使用kafka消費者高階API實現的。
對于所有的receiver,它通過kafka接收的數據會被存儲于spark的executors上,底層是寫入BlockManager中,默認200ms生成一個block(通過配置參數spark.streaming.blockInterval決定)。然后由spark streaming提交的job構建BlockRdd,最終以spark core任務的形式運行。
關于receiver方式,有以下幾點需要注意:
receiver作為一個常駐線程調度到executor上運行,占用一個cpu
receiver個數由KafkaUtils.createStream調用次數決定,一次一個receiver
kafka中的topic分區并不能關聯產生在spark streaming中的rdd分區
增加在KafkaUtils.createStream()中的指定的topic分區數,僅僅增加了單個receiver消費的topic的線程數,它不會增加處理數據中的并行的spark的數量【topicMap[topic,num_threads]map的value對應的數值是每個topic對應的消費線程數】
receiver默認200ms生成一個block,建議根據數據量大小調整block生成周期。
receiver接收的數據會放入到BlockManager,每個executor都會有一個BlockManager實例,由于數據本地性,那些存在receiver的executor會被調度執行更多的task,就會導致某些executor比較空閑
建議通過參數spark.locality.wait調整數據本地性。該參數設置的不合理,比如設置為10而任務2s就處理結束,就會導致越來越多的任務調度到數據存在的executor上執行,導致任務執行緩慢甚至失敗(要和數據傾斜區分開)
多個kafka輸入的DStreams可以使用不同的groups、topics創建,使用多個receivers接收處理數據
兩種receiver可靠的receiver:
可靠的receiver在接收到數據并通過復制機制存儲在spark中時準確的向可靠的數據源發送ack確認不可靠的receiver:
不可靠的receiver不會向數據源發送數據已接收確認。 這適用于用于不支持ack的數據源當然,我們也可以自定義receiver。
receiver處理數據可靠性默認情況下,receiver是可能丟失數據的。
可以通過設置spark.streaming.receiver.writeAheadLog.enable為true開啟預寫日志機制,將數據先寫入一個可靠地分布式文件系統如hdfs,確保數據不丟失,但會失去一定性能
限制消費者消費的最大速率涉及三個參數:
spark.streaming.backpressure.enabled:默認是false,設置為true,就開啟了背壓機制;
spark.streaming.backpressure.initialRate:默認沒設置初始消費速率,第一次啟動時每個receiver接收數據的最大值;
spark.streaming.receiver.maxRate:默認值沒設置,每個receiver接收數據的最大速率(每秒記錄數)。每個流每秒最多將消費此數量的記錄,將此配置設置為0或負數將不會對最大速率進行限制
在產生job時,會將當前job有效范圍內的所有block組成一個BlockRDD,一個block對應一個分區
kafka082版本消費者高階API中,有分組的概念,建議使消費者組內的線程數(消費者個數)和kafka分區數保持一致。如果多于分區數,會有部分消費者處于空閑狀態
direct approach是spark streaming不使用receiver集成kafka的方式,一般在企業生產環境中使用較多。相較于receiver,有以下特點:
1.不使用receiver
不需要創建多個kafka streams并聚合它們
減少不必要的CPU占用
減少了receiver接收數據寫入BlockManager,然后運行時再通過blockId、網絡傳輸、磁盤讀取等來獲取數據的整個過程,提升了效率
無需wal,進一步減少磁盤IO操作
2.direct方式生的rdd是KafkaRDD,它的分區數與kafka分區數保持一致一樣多的rdd分區來消費,更方便我們對并行度進行控制
注意:在shuffle或者repartition操作后生成的rdd,這種對應關系會失效
3.可以手動維護offset,實現exactly once語義
4.數據本地性問題。在KafkaRDD在compute函數中,使用SimpleConsumer根據指定的topic、分區、offset去讀取kafka數據。
但在010版本后,又存在假如kafka和spark處于同一集群存在數據本地性的問題
5.限制消費者消費的最大速率
spark.streaming.kafka.maxRatePerPartition:從每個kafka分區讀取數據的最大速率(每秒記錄數)。這是針對每個分區進行限速,需要事先知道kafka分區數,來評估系統的吞吐量。
上述內容就是怎樣解析SparkStreaming和Kafka集成的兩種方式,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





