溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么結合Spark講一下Flink的runtime,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
Flink運行時主要角色有兩個:JobManager和TaskManager,無論是standalone集群,on yarn都是要啟動這兩個角色。有點類似于MRv1的架構了,JobManager主要是負責接受客戶端的job,調度job,協調checkpoint等。TaskManager執行具體的Task。TaskManager為了對資源進行隔離和增加允許的task數,引入了slot的概念,這個slot對資源的隔離僅僅是對內存進行隔離,策略是均分,比如taskmanager的管理內存是3GB,假如有三個slot,那么每個slot就僅僅有1GB內存可用。
根據經驗,taskslot數最佳默認值就是CPU核心數。使用超線程,每個task slot需要2個或更多硬件線程上下文。
Client這個角色主要是為job提交做些準備工作,比如構建jobgraph提交到jobmanager,提交完了可以立即退出,當然也可以用client來監控進度。
Jobmanager和TaskManager之間通信類似于Spark 的早期版本,采用的是actor系統。
根據以上描述,繪制出運行架構圖就是下圖:
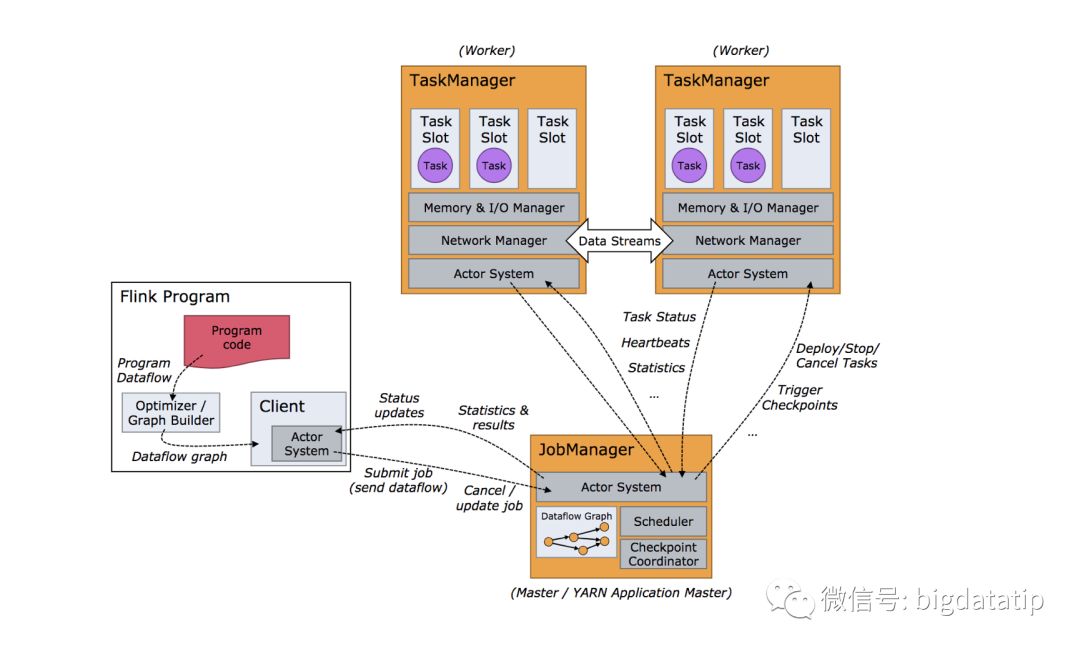
Task到底是什么玩意?
講到這可以先回顧一下Spark了,主要三個概念:
1. Shuffle
Spark 任務job中shuffle個數決定著stage個數。
2. 分區
Spark 算子中RDD的分區數決定者stage任務的并行度。
3. 分區傳遞
復雜的入union,join等暫不提。簡單的調用鏈如下:
rdd.map-->filter-->reducebykey-->map。
例子中假設rdd有6個分區,map到fliter的分區數傳遞是不變,filter到redcuebykey分區就變了,reducebykey的分區有個默認計算公式,星球里講過了,假設我們在使用reducebykey的時候傳入了一個分區數12。
分區數,map是6,filter也是6,reducebykey后面的map就是12。

override def getPartitions: Array[Partition] =firstParent[T].partitions
map這類轉換完全繼承了父RDD的分區器和分區數,默認無法人為設置并行度,只有在shuffle的時候,我們才可以傳入并行度。
上述講解主要是想帶著大家搞明白,以下幾個概念:
Flink的并行度由什么決定的?
Flink的task是什么?
1. Flink的并行度由什么決定的?
這個很簡單,Flink每個算子都可以設置并行度,然后就是也可以設置全局并行度。
Api的設置
.map(new RollingAdditionMapper()).setParallelism(10)
全局配置在flink-conf.yaml文件中,parallelism.default,默認是1:

2. Flink的task是什么?
按理說應該是每個算子的一個并行度實例就是一個subtask-在這里為了區分暫時叫做substask。那么,帶來很多問題,由于flink的taskmanager運行task的時候是每個task采用一個單獨的線程,這就會帶來很多線程切換開銷,進而影響吞吐量。
為了減輕這種情況,flink進行了優化,也即對subtask進行鏈式操作,鏈式操作結束之后得到的task,再作為一個調度執行單元,放到一個線程里執行。
如下圖的,source/map 兩個算子進行了鏈式;keyby/window/apply有進行了鏈式,sink單獨的一個。
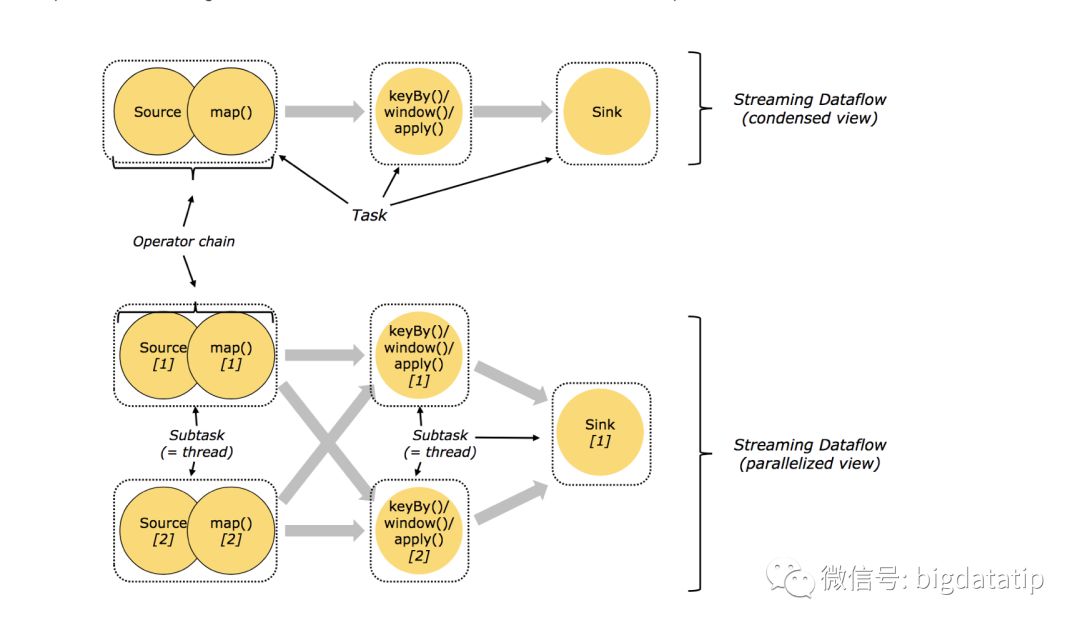 注釋:圖中假設是source/map的并行度都是2,keyby/window/apply的并行度也都是2,sink的是1,總共task有五個,最終需要五個線程。
注釋:圖中假設是source/map的并行度都是2,keyby/window/apply的并行度也都是2,sink的是1,總共task有五個,最終需要五個線程。
按照到這一步的理解,畫的執行圖應該是這樣的:

有些朋友該說了,據我觀察實際上并不是這樣的呀。。。
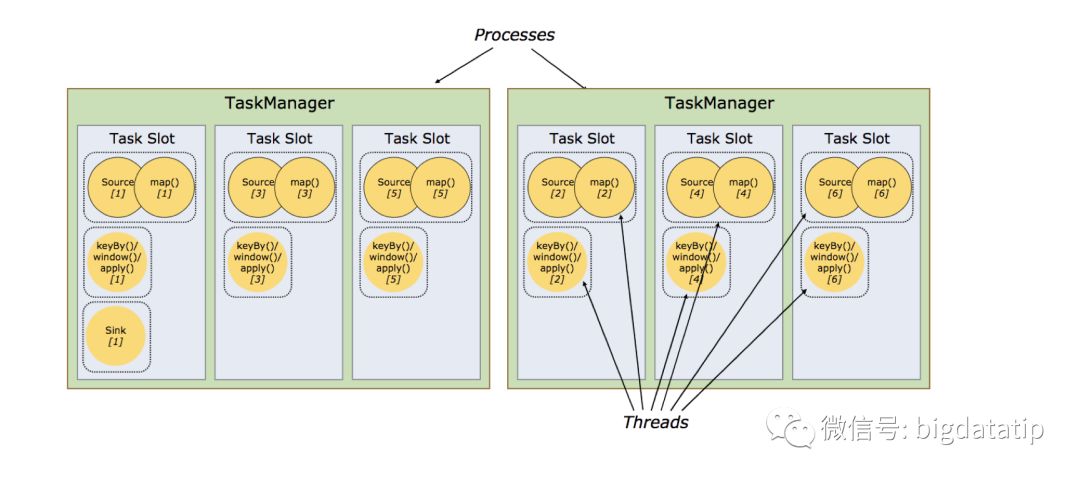 這個是實際上是flink又一次優化。
這個是實際上是flink又一次優化。
默認情況下,flink允許如果任務是不同的task的時候,允許任務共享slot,當然,前提是必須在同一個job內部。
結果就是,每個slot可以執行job的一整個pipeline,如上圖。這樣做的好處主要有以下幾點:
1.Flink 集群所需的taskslots數與job中最高的并行度一致。也就是說我們不需要再去計算一個程序總共會起多少個task了。
2.更容易獲得更充分的資源利用。如果沒有slot共享,那么非密集型操作source/flatmap就會占用同密集型操作 keyAggregation/sink 一樣多的資源。如果有slot共享,將基線的2個并行度增加到6個,能充分利用slot資源,同時保證每個TaskManager能平均分配到重的subtasks,比如keyby/window/apply操作就會均分到申請的所有slot里,這樣slot的負載就均衡了。
鏈式的原則,也即是什么情況下才會對task進行鏈式操作呢?簡單梗概一下:
上下游的并行度一致
下游節點的入度為1 (也就是說下游節點沒有來自其他節點的輸入)
上下游節點都在同一個 slot group 中(下面會解釋 slot group)
下游節點的 chain 策略為 ALWAYS(可以與上下游鏈接,map、flatmap、filter等默認是ALWAYS)
上游節點的 chain 策略為 ALWAYS 或 HEAD(只能與下游鏈接,不能與上游鏈接,Source默認是HEAD)
兩個節點間數據分區方式是 forward(參考理解數據流的分區)
用戶沒有禁用 chain
關于怎么結合Spark講一下Flink的runtime問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





