溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了怎么實現kafka性能技術分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1.通過磁盤順序讀寫,效率高,appendLog,對比raid-5 7200rpm的磁盤
sequence io 600M/s
random io 100kb/s
kafka寫操作時,依賴底層文件系統的pagecache功能,pagecache會將盡量多的將空閑內存,當做磁盤緩存,寫操作先寫到pageCache,并將該page標記為dirty;發生讀操作時,會先從pageCache中查找,當發生缺頁時,才會去磁盤調整;當有其他應用申請內存時,回收pageCache的代價是很低的
,使用pageCache的緩存功能,會減少我們隊JVM的內存依賴,JVM為我們提供了GC功能,依賴JVM內存在kafka高吞吐,大數據的場景下有很多問題。如果heap管理緩存,那么JVM的gc會頻繁掃描heap空間,帶來的開銷很大,如果heap過大,full gc帶來的成本也很高;所有的In-Process Cache在OS中都有一份同樣的PageCache。所以通過只在PageCache中做緩存至少可以提高一倍的緩存空間。如果Kafka重啟,所有的In-Process Cache都會失效,而OS管理的PageCache依然可以繼續使用。
2.sendFile
傳統網絡IO模型
① 操作系統將數據從磁盤拷貝到內核區的pagecache
② 用戶程序將內核區的pagecache拷貝到用戶區緩存
③ 用戶程序將用戶區的緩存拷貝到socket緩存中
④ 操作系統將socket緩存中的數據拷貝到網卡的buffer上,發送
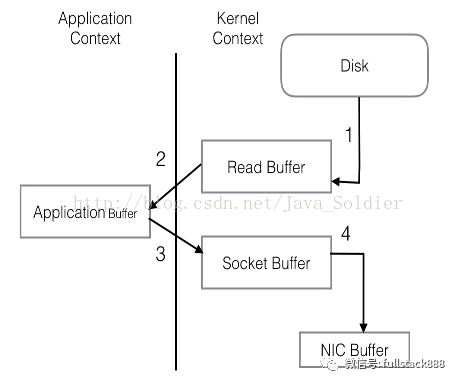
問題:四次system call 兩次context切換,同一份數據在緩存中拷貝多次,效率很低,拷貝動作完全可以在內核中進行,將2 3 步去掉,sendfile就是完成這一功能
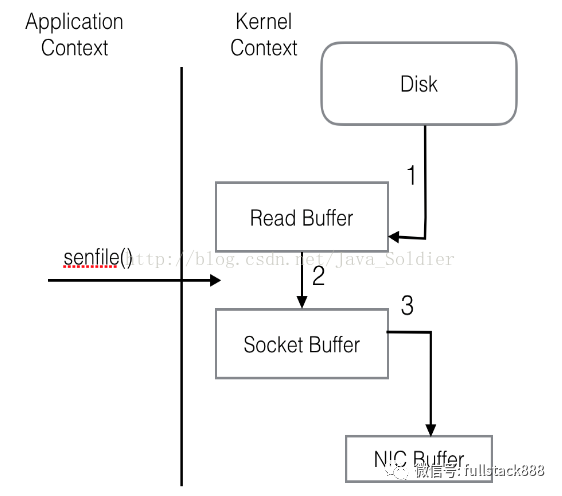
kafka設計初衷是數據的拷貝完全通過pageCache來進行,盡量減少磁盤讀寫,如果kafka生產消費配合的好,那么數據完全走內存,這對集群的吞吐量提升是很大的
當集群只有寫操作時,此時的集群只有寫,沒有讀操作。10M/s左右的Send的流量是Partition之間進行Replicate而產生的。從recv和writ的速率比較可以看出,寫盤是使用Asynchronous+Batch的方式,底層OS可能還會進行磁盤寫順序優化。而在有Read Request進來的時候分為兩種情況,第一種是內存中完成數據交換。
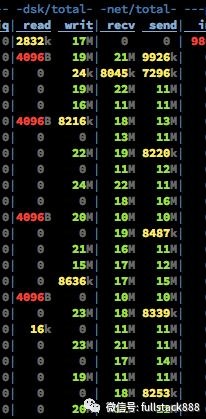
② 已經從pageCache刷出的數據,這時候的數據可以看出大部分走的是磁盤io
TIPS
① kafka官方不建議使用log.flush.interval.messages和log.flush.interval.ms來強制刷盤,因為高可靠應該通過replica副本來保證,強制刷盤對系統性能影響很大(生產是100000 和60000)
② 可以通過調整/proc/sys/vm/dirty_background_ratio和/proc/sys/vm/dirty_ratio來調優性能。
a. 臟頁率超過第一個指標會啟動pdflush開始Flush Dirty PageCache。
b. 臟頁率超過第二個指標會阻塞所有的寫操作來進行Flush。
c. 根據不同的業務需求可以適當的降低dirty_background_ratio和提高dirty_ratio。
(生產是10 和 20)
2 partition
Partition是Kafka可以很好的橫向擴展和提供高并發處理以及實現Replication的基礎。
擴展性方面。首先,Kafka允許Partition在集群內的Broker之間任意移動,以此來均衡可能存在的數據傾斜問題。其次,Partition支持自定義的分區算法,例如可以將同一個Key的所有消息都路由到同一個Partition上去。 同時Leader也可以在In-Sync的Replica中遷移。由于針對某一個Partition的所有讀寫請求都是只由Leader來處理,所以Kafka會盡量把Leader均勻的分散到集群的各個節點上,以免造成網絡流量過于集中。
并發方面。任意Partition在某一個時刻只能被一個Consumer Group內的一個Consumer消費(反過來一個Consumer則可以同時消費多個Partition),Kafka非常簡潔的Offset機制最小化了Broker和Consumer之間的交互,這使Kafka并不會像同類其他消息隊列一樣,隨著下游Consumer數目的增加而成比例的降低性能。此外,如果多個Consumer恰巧都是消費時間序上很相近的數據,可以達到很高的PageCache命中率,因而Kafka可以非常高效的支持高并發讀操作,實踐中基本可以達到單機網卡上限。
不過,Partition的數量并不是越多越好,Partition的數量越多,平均到每一個Broker上的數量也就越多。考慮到Broker宕機(Network Failure, Full GC)的情況下,需要由Controller來為所有宕機的Broker上的所有Partition重新選舉Leader,假設每個Partition的選舉消耗10ms,如果Broker上有500個Partition,那么在進行選舉的5s的時間里,對上述Partition的讀寫操作都會觸發LeaderNotAvailableException。
再進一步,如果掛掉的Broker是整個集群的Controller,那么首先要進行的是重新任命一個Broker作為Controller。新任命的Controller要從Zookeeper上獲取所有Partition的Meta信息,獲取每個信息大概3-5ms,那么如果有10000個Partition這個時間就會達到30s-50s。而且不要忘記這只是重新啟動一個Controller花費的時間,在這基礎上還要再加上前面說的選舉Leader的時間 -_-!!!!!!
此外,在Broker端,對Producer和Consumer都使用了Buffer機制。其中Buffer的大小是統一配置的,數量則與Partition個數相同。如果Partition個數過多,會導致Producer和Consumer的Buffer內存占用過大。
tips
1. Partition的數量盡量提前預分配,雖然可以在后期動態增加Partition,但是會冒著可能破壞Message Key和Partition之間對應關系的風險。
2. Replica的數量不要過多,如果條件允許盡量把Replica集合內的Partition分別調整到不同的Rack。
3. 盡一切努力保證每次停Broker時都可以Clean Shutdown,否則問題就不僅僅是恢復服務所需時間長,還可能出現數據損壞或其他很詭異的問題。
3
Producer
Kafka的研發團隊表示在0.8版本里用Java重寫了整個Producer,據說性能有了很大提升。我還沒有親自對比試用過,這里就不做數據對比了。本文結尾的擴展閱讀里提到了一套我認為比較好的對照組,有興趣的同學可以嘗試一下。
其實在Producer端的優化大部分消息系統采取的方式都比較單一,無非也就化零為整、同步變異步這么幾種。
Kafka系統默認支持MessageSet,把多條Message自動地打成一個Group后發送出去,均攤后拉低了每次通信的RTT。而且在組織MessageSet的同時,還可以把數據重新排序,從爆發流式的隨機寫入優化成較為平穩的線性寫入。
此外,還要著重介紹的一點是,Producer支持End-to-End的壓縮。數據在本地壓縮后放到網絡上傳輸,在Broker一般不解壓(除非指定要Deep-Iteration),直至消息被Consume之后在客戶端解壓。
當然用戶也可以選擇自己在應用層上做壓縮和解壓的工作(畢竟Kafka目前支持的壓縮算法有限,只有GZIP和Snappy),不過這樣做反而會意外的降低效率!!!! Kafka的End-to-End壓縮與MessageSet配合在一起工作效果最佳,上面的做法直接割裂了兩者間聯系。至于道理其實很簡單,壓縮算法中一條基本的原理“重復的數據量越多,壓縮比越高”。無關于消息體的內容,無關于消息體的數量,大多數情況下輸入數據量大一些會取得更好的壓縮比。
不過Kafka采用MessageSet也導致在可用性上一定程度的妥協。每次發送數據時,Producer都是send()之后就認為已經發送出去了,但其實大多數情況下消息還在內存的MessageSet當中,尚未發送到網絡,這時候如果Producer掛掉,那就會出現丟數據的情況。
為了解決這個問題,Kafka在0.8版本的設計借鑒了網絡當中的ack機制。如果對性能要求較高,又能在一定程度上允許Message的丟失,那就可以設置request.required.acks=0 來關閉ack,以全速發送。如果需要對發送的消息進行確認,就需要設置request.required.acks為1或-1,那么1和-1又有什么區別呢?這里又要提到前面聊的有關Replica數量問題。如果配置為1,表示消息只需要被Leader接收并確認即可,其他的Replica可以進行異步拉取無需立即進行確認,在保證可靠性的同時又不會把效率拉得很低。如果設置為-1,表示消息要Commit到該Partition的ISR集合中的所有Replica后,才可以返回ack,消息的發送會更安全,而整個過程的延遲會隨著Replica的數量正比增長,這里就需要根據不同的需求做相應的優化。
tips
1. Producer的線程不要配置過多,尤其是在Mirror或者Migration中使用的時候,會加劇目標集群Partition消息亂序的情況(如果你的應用場景對消息順序很敏感的話)。
2. 0.8版本的request.required.acks默認是0(同0.7)。
4
Consumer
Consumer端的設計大體上還算是比較常規的。
? 通過Consumer Group,可以支持生產者消費者和隊列訪問兩種模式。
? Consumer API分為High level和Low level兩種。前一種重度依賴Zookeeper,所以性能差一些且不自由,但是超省心。第二種不依賴Zookeeper服務,無論從自由度和性能上都有更好的表現,但是所有的異常(Leader遷移、Offset越界、Broker宕機等)和Offset的維護都需要自行處理。
? 大家可以關注下不日發布的0.9 Release。這幫貨又用Java重寫了一套Consumer。把兩套API合并在一起,同時去掉了對Zookeeper的依賴。據說性能有大幅度提升哦~~
tips
強烈推薦使用Low level API,雖然繁瑣一些,但是目前只有這個API可以對Error數據進行自定義處理,尤其是處理Broker異常或由于Unclean Shutdown導致的Corrupted Data時,否則無法Skip只能等著“壞消息”在Broker上被Rotate掉,在此期間該Replica將會一直處于不可用狀態。
上述內容就是怎么實現kafka性能技術分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





