溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中怎么通過BeautifulSoup提取數據,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
步驟:
1、使用pycharm新建項目,新建的時候記得勾選“Inherit global site-packages”否則可能找不到requests類庫
2、編寫代碼,我們看到網頁上的數據量是101行,如下所示:

代碼如下:
項目結構(不重要):
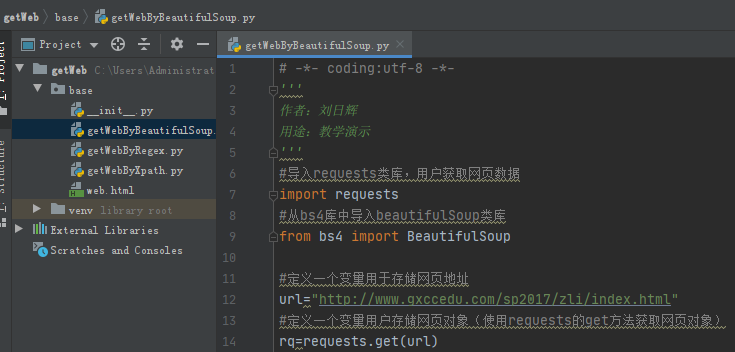
程序代碼:
Beautiful Soup可以將HTML文檔轉換為Tag樹形結構,如果BeautifulSoup對象是soup,則我們可以通過soup.td獲取頁面里面的第一個td元素,通過soup.find_all('td')獲取所有的td元素。也就是find_all()返回來的是一個數組元素,那么我們可以通過下標來獲取對應的內容,如下:
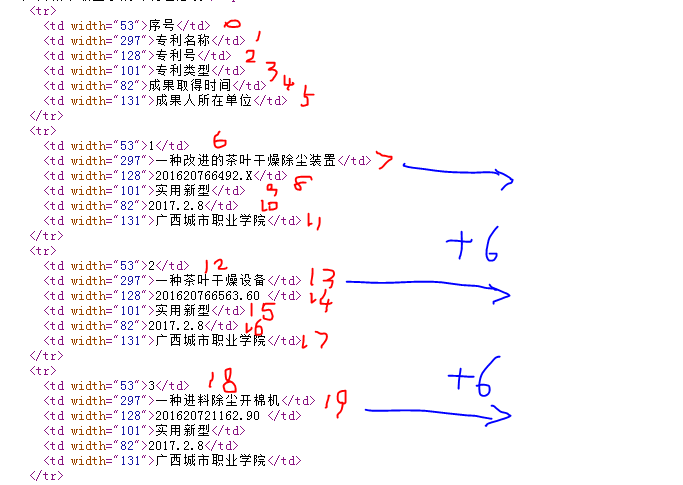
我們可以看到,第一個專利的名稱的下標是7,第二個是13,第三個是19,依次類推,所以我們可以通過間隔獲取的方式來達到效果。
代碼如下,另外要記得最后獲取的是text屬性,否則獲取的就是是<td>XXX</td>的內容:

運行效果:
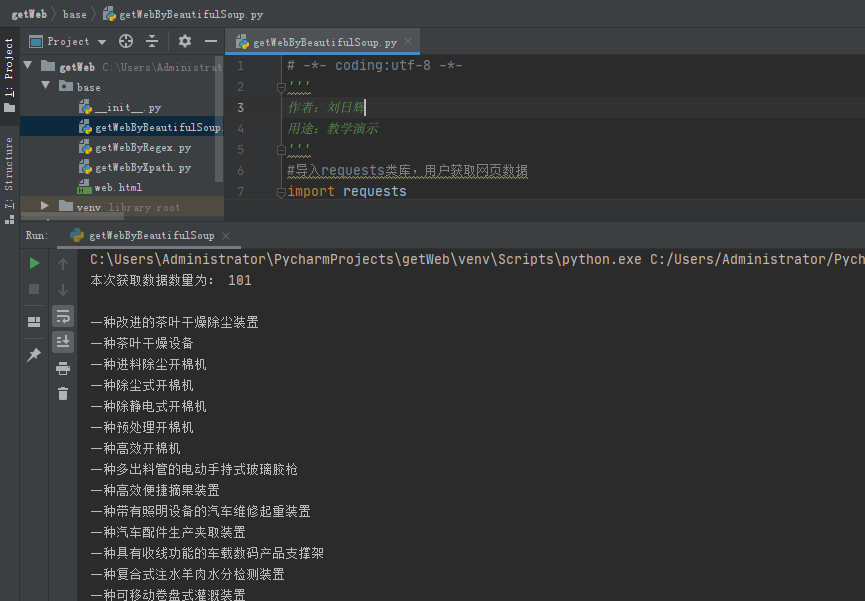
上述內容就是Python中怎么通過BeautifulSoup提取數據,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





