溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Schedulerx2.0分布式計算原理及最佳實踐是怎么樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Schedulerx2.0的客戶端提供分布式執行、多種任務類型、統一日志等框架,用戶只要依賴schedulerx-worker這個jar包,通過schedulerx2.0提供的編程模型,簡單幾行代碼就能實現一套高可靠可運維的分布式執行引擎。
這篇文章重點是介紹基于schedulerx2.0的分布式執行引擎原理和最佳實踐,相信看完這篇文章,大家都能寫出高效率的分布式作業,說不定速度能提升好幾倍:)
Worker總體架構參考Yarn的架構,分為TaskMaster, Container, Processor三層:
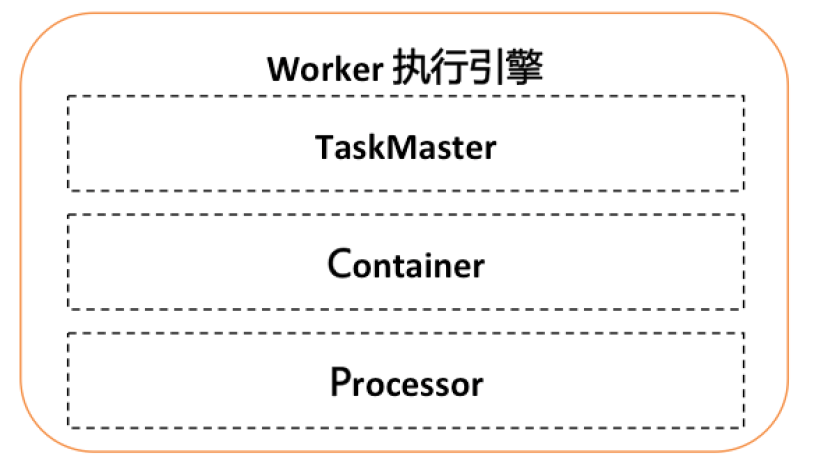
TaskMaster:類似于yarn的AppMaster,支持可擴展的分布式執行框架,進行整個jobInstance的生命周期管理、container的資源管理,同時還有failover等能力。默認實現StandaloneTaskMaster(單機執行),BroadcastTaskMaster(廣播執行),MapTaskMaster(并行計算、內存網格、網格計算),MapReduceTaskMaster(并行計算、內存網格、網格計算)。
Container:執行業務邏輯的容器框架,支持線程/進程/docker/actor等。
Processor:業務邏輯框架,不同的processor表示不同的任務類型。
以MapTaskMaster為例,大概的原理如下圖所示:
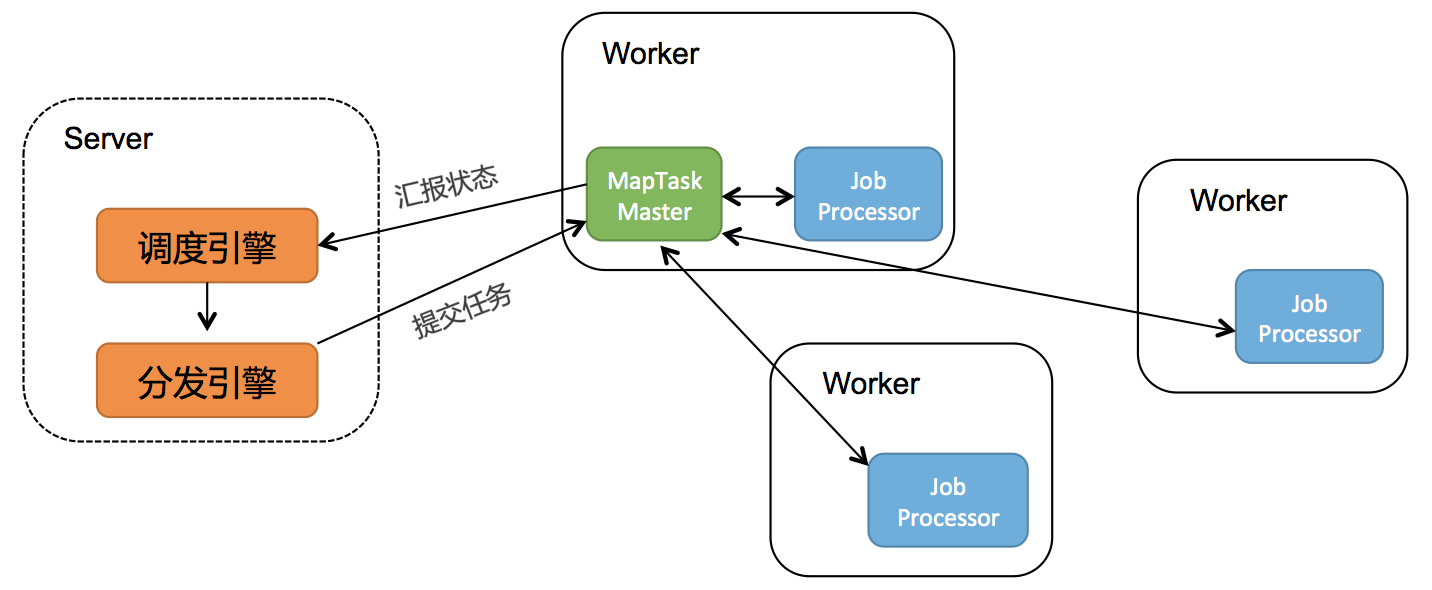
Schedulerx2.0提供了多種分布式編程模型,這篇文章主要介紹Map模型(之后的文章還會介紹MapReduce模型,適用更多的業務場景),簡單幾行代碼就可以將海量數據分布式到多臺機器上進行分布式跑批,非常簡單易用。
針對不同的跑批場景,map模型作業還提供了并行計算、內存網格、網格計算三種執行方式:
并行計算:子任務300以下,有子任務列表。
內存網格:子任務5W以下,無子任務列表,速度快。
網格計算:子任務100W以下,無子任務列表。
因為并行任務具有子任務列表:
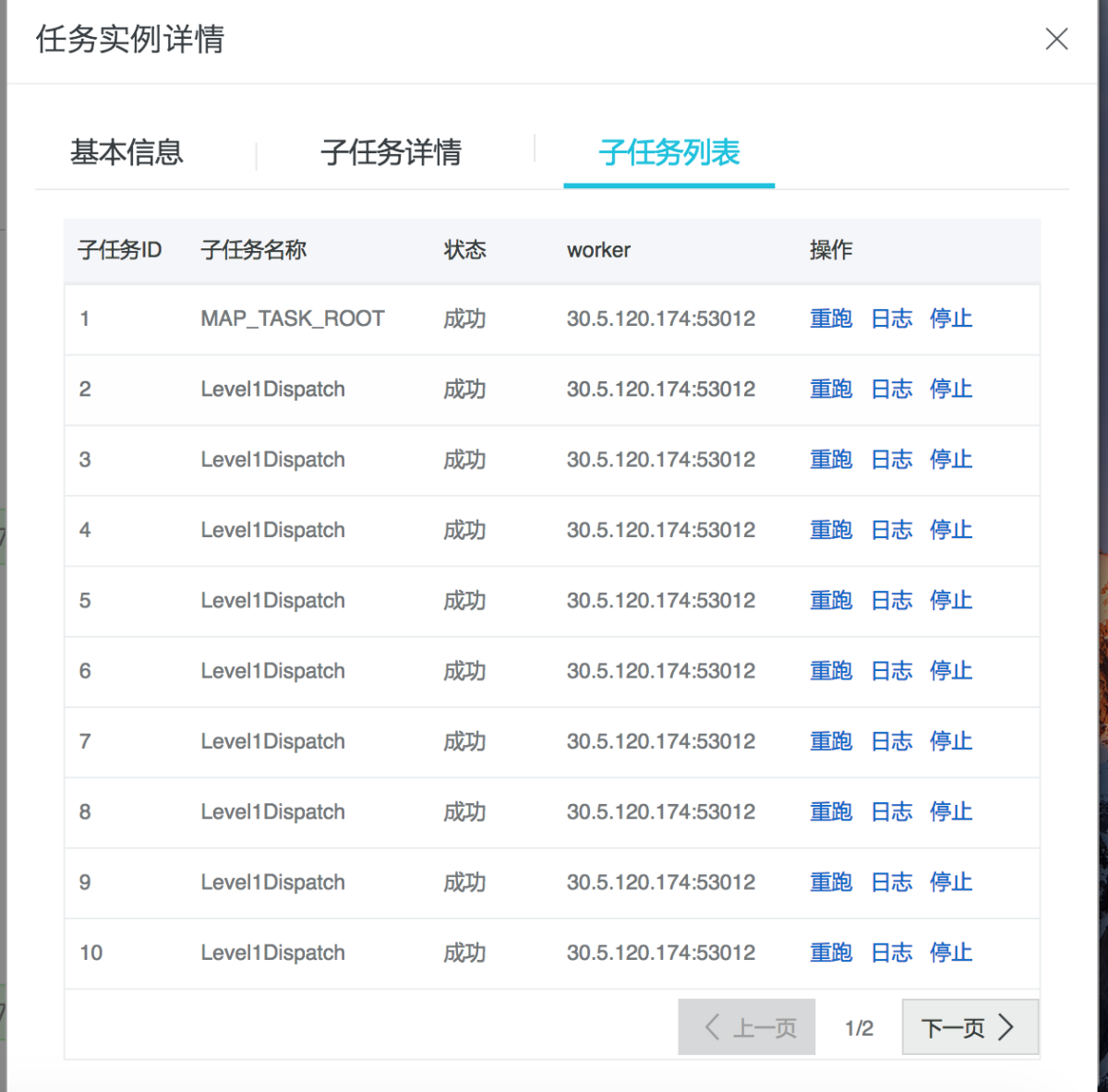
如上圖,子任務列表可以看到每個子任務的狀態、機器,還有重跑、查看日志等操作。
因為并行計算要做到子任務級別的可視化,并且worker掛了、重啟還能支持手動重跑,就需要把task持久化到server端:
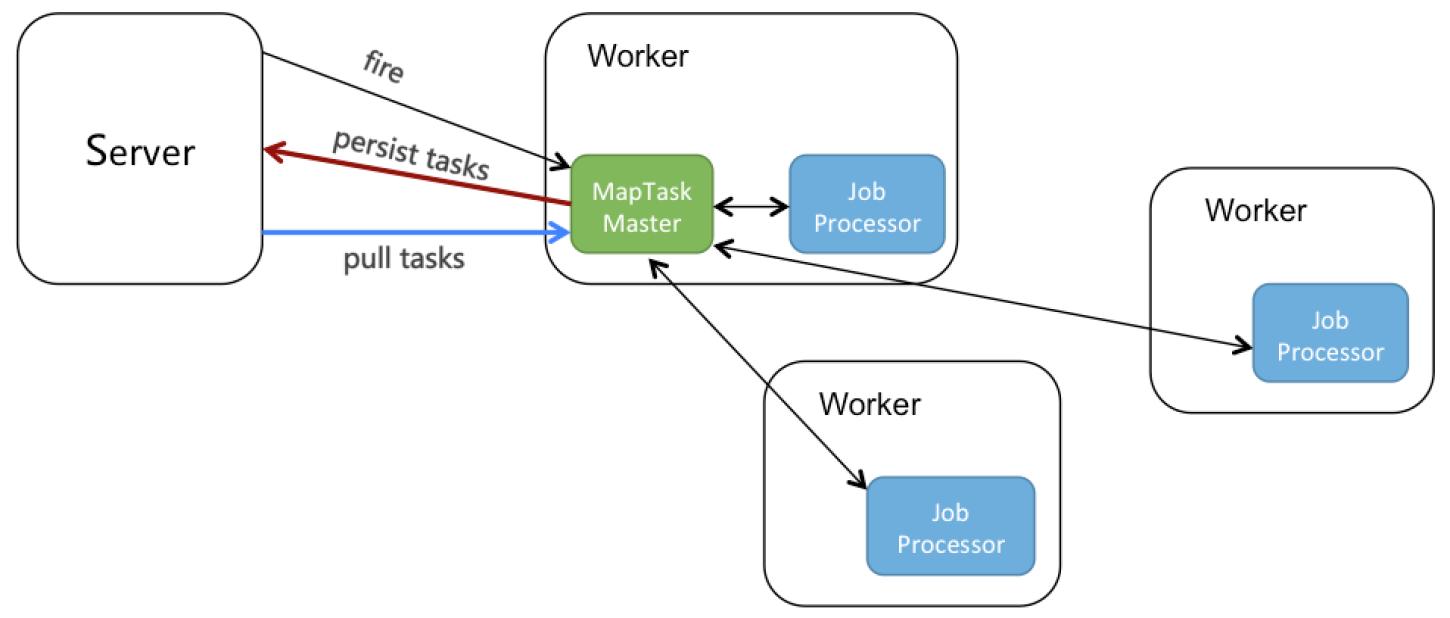
如上圖所示:
server觸發jobInstance到某個worker,選中為master。
MapTaskMaster選擇某個worker執行root任務,當執行map方法時,會回調MapTaskMaster。
MapTaskMaster收到map方法,會把task持久化到server端。
同時,MapTaskMaster還有個pull線程,不停拉取INIT狀態的task,并派發給其他worker執行。
網格計算要支持百萬級別的task,如果所有任務都往server回寫,server肯定扛不住,所以網格計算的存儲實際上是分布式在用戶自己的機器上的:
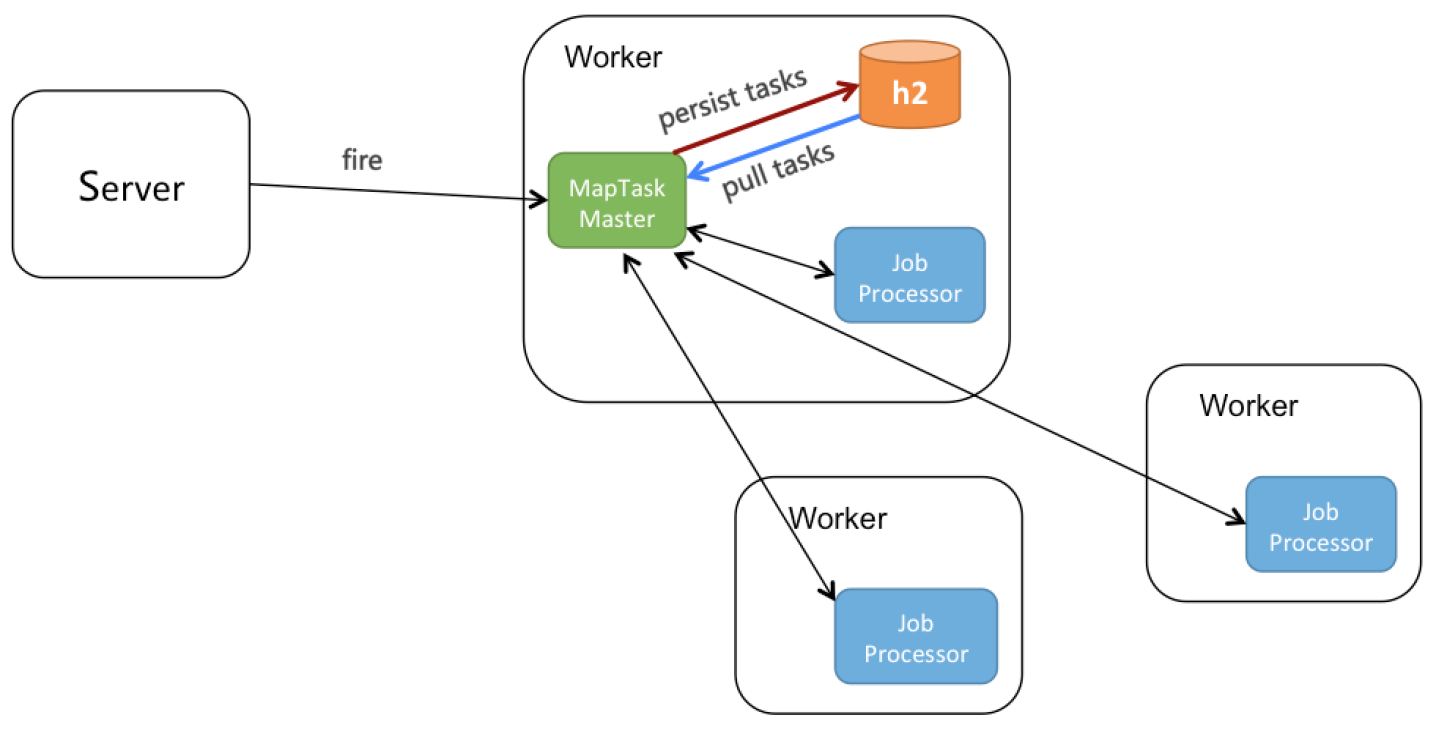
如上圖所示:
server觸發jobInstance到某個worker,選中為master。
MapTaskMaster選擇某個worker執行root任務,當執行map方法時,會回調MapTaskMaster。
MapTaskMaster收到map方法,會把task持久化到本地h3數據庫。
同時,MapTaskMaster還有個pull線程,不停拉取INIT狀態的task,并派發給其他worker執行。
舉個例子:
讀取A表中status=0的數據。
處理這些數據,插入B表。
把A表中處理過的數據的修改status=1。
數據量有4億+,希望縮短時間。
我們先看下如下代碼是否有問題?
public class ScanSingleTableProcessor extends MapJobProcessor {
private static int pageSize = 1000;
@Override
public ProcessResult process(JobContext context) {
String taskName = context.getTaskName();
Object task = context.getTask();
if (WorkerConstants.MAP_TASK_ROOT_NAME.equals(taskName)) {
int recordCount = queryRecordCount();
int pageAmount = recordCount / pageSize;//計算分頁數量
for(int i = 0 ; i < pageAmount ; i ++) {
List<Record> recordList = queryRecord(i);//根據分頁查詢一頁數據
map(recordList, "record記錄");//把子任務分發出去并行處理
}
return new ProcessResult(true);//true表示執行成功,false表示失敗
} else if ("record記錄".equals(taskName)) {
//TODO
return new ProcessResult(true);
}
return new ProcessResult(false);
}
}如上面的代碼所示,在root任務中,會把數據庫所有記錄讀取出來,每一行就是一個Record,然后分發出去,分布式到不同的worker上去執行。邏輯是沒有問題的,但是實際上性能非常的差。結合網格計算原理,我們把上面的代碼繪制成下面這幅圖:
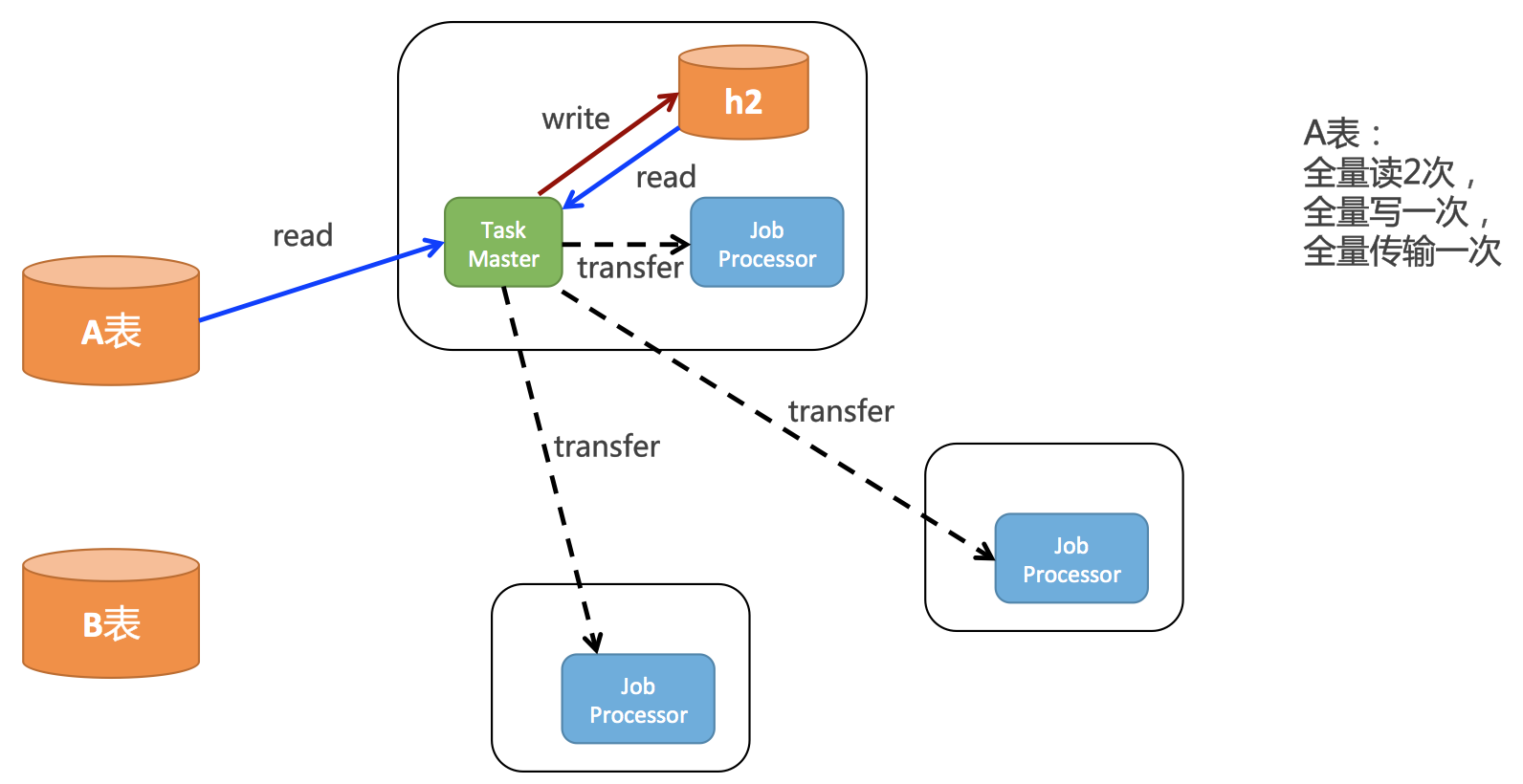
如上圖所示,root任務一開始會全量的讀取A表的數據,然后會全量的存到h3中,pull線程還會全量的從h3讀取一次所有的task,還會分發給所有客戶端。所以實際上對A表中的數據:
全量讀2次
全量寫一次
全量傳輸一次
這個效率是非常低的。
下面給出正面案例的代碼:
public class ScanSingleTableJobProcessor extends MapJobProcessor {
private static final int pageSize = 100;
static class PageTask {
private int startId;
private int endId;
public PageTask(int startId, int endId) {
this.startId = startId;
this.endId = endId;
}
public int getStartId() {
return startId;
}
public int getEndId() {
return endId;
}
}
@Override
public ProcessResult process(JobContext context) {
String taskName = context.getTaskName();
Object task = context.getTask();
if (taskName.equals(WorkerConstants.MAP_TASK_ROOT_NAME)) {
System.out.println("start root task");
Pair<Integer, Integer> idPair = queryMinAndMaxId();
int minId = idPair.getFirst();
int maxId = idPair.getSecond();
List<PageTask> taskList = Lists.newArrayList();
int step = (int) ((maxId - minId) / pageSize); //計算分頁數量
for (int i = minId; i < maxId; i+=step) {
taskList.add(new PageTask(i, (i+step > maxId ? maxId : i+step)));
}
return map(taskList, "Level1Dispatch");
} else if (taskName.equals("Level1Dispatch")) {
PageTask record = (PageTask)task;
long startId = record.getStartId();
long endId = record.getEndId();
//TODO
return new ProcessResult(true);
}
return new ProcessResult(true);
}
@Override
public void postProcess(JobContext context) {
//TODO
System.out.println("all tasks is finished.");
}
private Pair<Integer, Integer> queryMinAndMaxId() {
//TODO select min(id),max(id) from xxx
return null;
}
}如上面的代碼所示,
每個task不是整行記錄的record,而是PageTask,里面就2個字段,startId和endId。
root任務,沒有全量的讀取A表,而是讀一下整張表的minId和maxId,然后構造PageTask進行分頁。比如task1表示PageTask[1,1000],task2表示PageTask[1001,2000]。每個task處理A表不同的數據。
在下一級task中,如果拿到的是PageTask,再根據id區間去A表處理數據。
根據上面的代碼和網格計算原理,得出下面這幅圖:
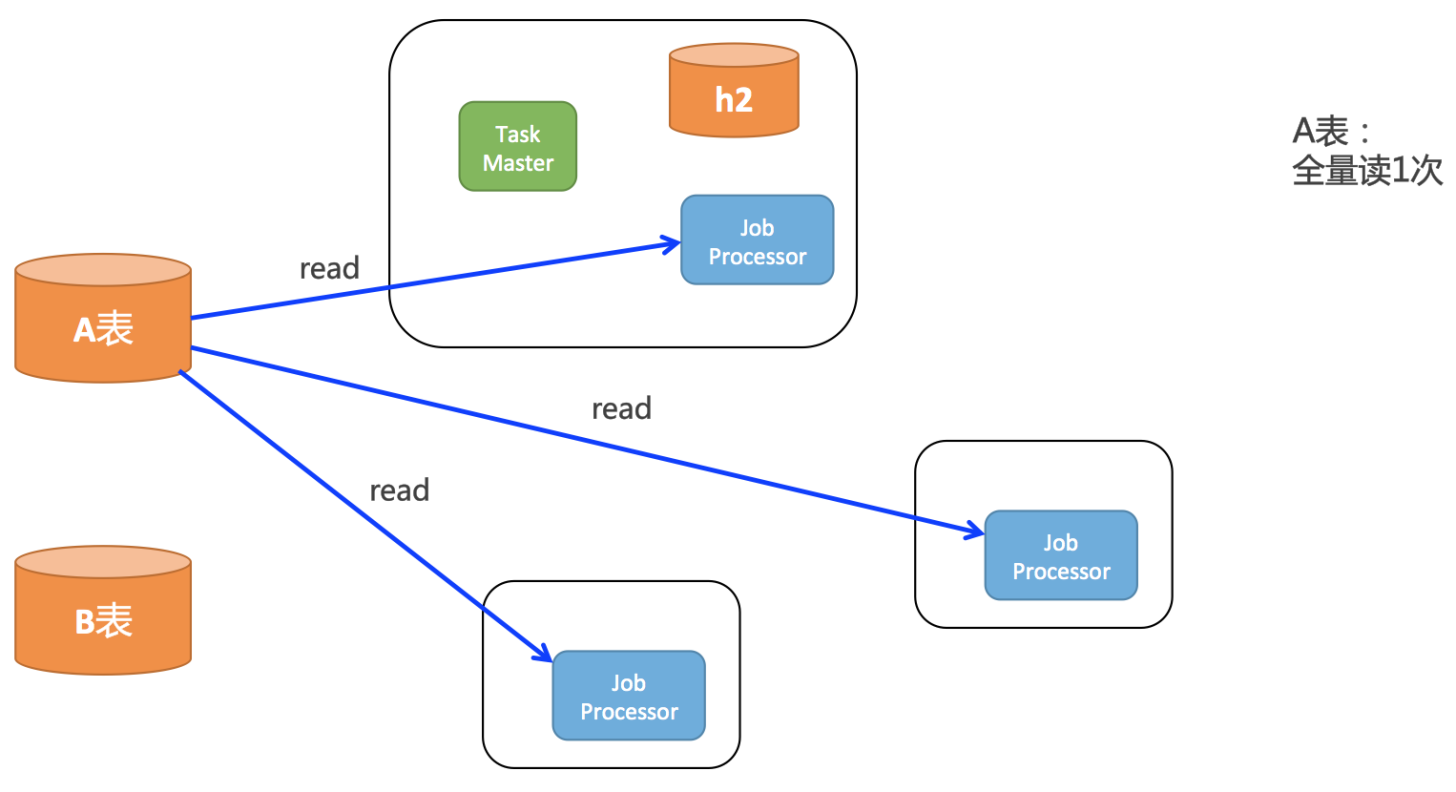
如上圖所示,
A表只需要全量讀取一次。
子任務數量比反面案例少了上千、上萬倍。
子任務的body非常小,如果recod中有大字段,也少了上千、上萬倍。
綜上,對A表訪問次數少了好幾倍,對h3存儲壓力少了上萬倍,不但執行速度可以快很多,還保證不會把自己本地的h3數據庫搞掛。
上述內容就是Schedulerx2.0分布式計算原理及最佳實踐是怎么樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





