溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行FM+GBM排序模型的深度解析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
信息流短視頻以算法分發為主,人工分發為輔,依賴算法實現視頻的智能分發,達到千人千面的效果。整個分發流程分為:觸發召回、排序與重排三個階段。排序層在其中起著承上啟下的作用,是非常重要的一個環節。在排序層優化的過程中,除了借鑒業界前沿的經驗和做法,我們也做了模型上的一些創新。
信息流短視頻排序目前使用是以CTR預估為目標的Wide&Deep模型。通過引入時長特征、點擊+時長多目標優化等工作,我們取得了不錯的收益:
● 增加視頻平均播放時長特征,作為用戶真實體感信號,帶來用戶消費時長提升;
● 通過消費時長樣本加權,實現點擊+時長多目標優化,實現點擊率與消費時長的提升;
● 引入多個視頻下發場景的樣本數據,實現多場景樣本融合;
在優化排序模型的過程中,我們也調研了DeepFM/DeepCN等深度模型,這些模型無論從離線還是線上指標上,都沒有明顯優勢。在優化Wide&Deep模型的同時,更迫切的需求,是跳出原有的框架,尋找新的收益點。
cdn.com/9d7991c499d8a9b82991051261863d1811117a0a.png">
引入GBM對submodel和高級特征等信號做集成學習,效果要優于單模型。從計算學習理論上看,Wide&Deep是high-variance模型,容易過擬合(wd模型的訓練比評估指標高7%)。GBM通過boosting的方式組合集成多個submodel和高級特征,更好地發揮各自不同的作用和優勢互補,同時從整體上有更好的可解釋性。
上面是對信息流短視頻排序模型演進的簡要介紹;而其中的FM+GBM模型是我們團隊比較有開創性的一項工作,下面稍微展開介紹。
模型
向量分解機(Factorization Machines, FM)是一種應用較為廣泛的推薦模型,其發明者Steffen Rendle目前供職于Google。FM是對傳統LR模型在處理高階交互特征問題上的優化和改進:LR通過特征交叉的方式,將組合后的特征作為新特征加入到模型中,模型復雜度為O(N^2)(N為交互特征的數量,下同),記憶性較強而泛化性偏弱;FM通過將特征表征為隱向量,通過隱向量的相似度(內積)來表示特征關聯這種方式來巧妙地提升模型的泛化能力;FM模型的復雜度為O(N*k)(k為隱向量維度超參)。

以二階交互的FM模型為例,其模型定義如下:

FM本質上是一個線性模型,不同項之間以線性組合的方式影響模型的輸出。如果要考慮更加復雜的模型組合,計算復雜度將會非常高。盡管學術界也有像張量分解(Tensor Decomposition)這類處理高階交互特征的模型;但在工業級,考慮到效果與性能的折衷,往往只考慮二階的交互。但在此基礎上,我們可以考慮引入非線性的模型來優化FM模型。
在非線性模型中,樹模型(CART/GBM/Random Forest)的應用非常廣泛。我們引入GBM作為組合FM的非線性模型:

FM+GBM一期(純GBM)
一期主要打通整個實驗框架和數據流,并沒有引入額外的信號。GBM使用的信號包括:wd/lr模型等sub-model打分、點擊率/時長和體感特征,以及一些簡單的匹配度特征。整個實驗框架比較簡單:精排流程新增GBMScorer,實現以下2個功能:
● 分發服務器通過流量分桶決定精排是否使用GBM打分,由GBMScorer具體執行;
● 特征歸一化和回流。提取的特征經歸一化后返回給分發服務器,由分發服務器回流至日志服務器落盤。點擊日志也同時經由日志服務器落盤。點擊-展現日志通過reco_id+iid對齊,經清洗、過濾和反作弊處理后,提取回流特征用于模型訓練;
在調研和實驗的過程中,以下是一些經驗和教訓:
● 樣本與超參的選擇:為了讓模型盡可能地平滑,我們從7天滑動窗口的數據中隨機抽取樣本,并按比例分割訓練/驗證/測試集。通過交叉驗證的方式選擇超參;在所有的超參中,樹深度對結果的影響比較大,深度為6時效果明顯優于其他選擇。在調參過程中,auc和loss這兩項評估指標在訓練/評估/測試數據集上并沒有明顯的差異,由此可見GBM模型的泛化性。
● 離線評估指標:auc是排序模型常用的離線評估指標之一,但全局auc粒度太粗,可以結合業務計算一些細粒度的auc。行業有采用以Query為粒度,計算QAUC,即單個Query的auc,再按均值或者加權的方式融合得到的auc,比起全局auc指標更加合理。我們采用類似做法,以單次下發為粒度計算auc,再計算均值或者按點擊加權。需要注意的是,auc計算的粒度決定了劃分數據集的粒度。如果按照單次下發為粒度計算,那么一次下發的所有樣本都必須同時落在訓練/評估/測試數據集上。除此之外,單次下發中如果零點擊或者全點擊,這部分數據也是需要廢棄的。
● 特征的歸一化:尤其是對與用戶相關的特征進行歸一化尤為重要。通過分析精排打分(wd),我們發現不同用戶間的精排打分分布的差異較為顯著:同一用戶的打分方差小,分布比較集中;不同用戶用戶打分均值的方差比較大。如果不對精排打分做歸一化處理,GBM訓練過程很難收斂。
GBM和精排打分也會隨特征回流。日志對齊后,可以對這兩個模型在離線評估指標上做比較fair的對比。從全局auc/單次下發粒度auc與小流量實驗的結果來看,細粒度auc與在線實驗的效果更加趨于一致。
FM+GBM二期
一期搭建了實驗框架和數據流,二期開始考慮引入新的信號。
縱觀眼下GBM用到的信號,主要分為兩類:一是item側信號,這類特征從各個維度刻畫了item的特性:熱度、時長、質量等。這類特征有助于我們篩選精品內容,提升推薦質量baseline。二是相關性特征,用于刻畫用戶和視頻的關聯度(關聯度可以通過點擊刻畫,也可以通過時長刻畫;目前主要通過點擊),提升推薦的個性化,做到千人千面。個性化水平才是信息流的核心競爭力。
目前相關性特征通過長短期用戶畫像計算和視頻在一級/二級類目和TAG上的匹配程度,至少存在2個問題:
● BoW稀疏的特征表達無法計算語義層面的匹配度;例如,帶足球標簽的用戶和梅西的視頻通過這種方式計算得到的匹配度為0。
● 目前視頻結構化信息的準確率/覆蓋率較低,會直接影響這類特征的效果。
wd/lr模型能夠一定程度解決上述問題。尤其wd模型,通過embedding技術,將用戶和視頻本身及各個維度的結構化信息嵌入到一個低維隱向量,能夠一定程度緩解這個問題。但是這類隱向量缺乏靈活性,無法脫離wd模型單獨使用:計算用戶和視頻的匹配度,除了需要用戶和視頻的隱向量,還要結合其他特征,并經過一系列隱層的計算才能得到。
業界主流公司的做法,是通過FM模型,將所有id特征都分成在同一個空間內的隱向量,因而所有的向量都是可比的:不僅用戶與視頻本身和各個維度的匹配度,甚至用戶之間、視頻之間,都可以通過簡單的向量運算得到匹配度。從模型結構看,FM模型可以認為是能夠更加緊密刻畫這種匹配度的神經網絡結構。為此,我們引入FM模型分解點擊-展現數據,得到用戶和視頻本身及各個維度的隱向量。通過這些隱向量計算用戶和視頻的匹配度。這些信號和與其它sub-model和高級特征一起,通過GBM進行點擊率預估。
這種做法與Facebook在KDD'14發表的LR+GBDT模型有相似之處,差異在于: LR+GBDT本質上是線性模型,而FM+GBM是樹模型,能夠處理信號與目標間高度非線性的復雜關系,也具備更好的可解釋性。整個算法框架如圖所示:
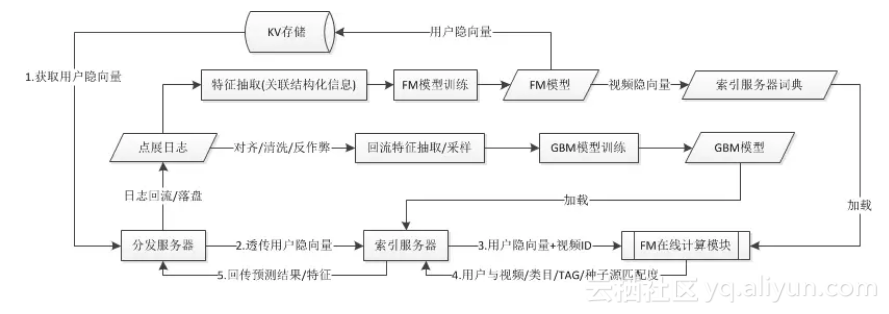
由于FM需要例行訓練,用戶隱向量灌庫和視頻隱向量加載之間存在時間差,而不同版本模型的隱向量之間是不可比的。為此我們設計了簡單的版本對齊機制:所有隱向量都會保留最近2個版本的數據;在FM在線計算模塊中,實現版本對齊的邏輯,用對齊后最新版本的隱向量計算匹配度。由于例行訓練的時間窗口為4~6個小時,保留2個版本的數據是足以保證絕大部分隱向量能夠對齊。在更加高頻的模型訓練中,可以增加版本的數量來確保模型對齊。
效果上:一期+二期離線AUC提升10%,在線CTR和人均點擊提升6%。
信息流短視頻排序層經過一段時間的迭代優化,目前已經形成 LR->WD->FM+GBM這套相對比較完備體系。這種漏斗體系有助于排序層在性能和效果之間trade-off:越往后,模型越復雜/特征越高級/計算量越大,而參與計算的視頻數據量更少。
看完上述內容,你們掌握如何進行FM+GBM排序模型的深度解析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





