溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何深度解析Kafka,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Kafka簡介
Kafka是一種分布式的,基于發布/訂閱的消息系統。主要設計目標如下:
以時間復雜度為O(1)的方式提供消息持久化能力,即使對TB級以上數據也能保證常數時間的訪問性能
高吞吐率。即使在非常廉價的商用機器上也能做到單機支持每秒100K條消息的傳輸
支持Kafka Server間的消息分區,及分布式消費,同時保證每個partition內的消息順序傳輸
同時支持離線數據處理和實時數據處理
解耦
在項目啟動之初來預測將來項目會碰到什么需求,是極其困難的。消息隊列在處理過程中間插入了一個隱含的、基于數據的接口層,兩邊的處理過程都要實現這一接口。這允許你獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束
冗余
有些情況下,處理數據的過程會失敗。除非數據被持久化,否則將造成丟失。消息隊列把數據進行持久化直到它們已經被完全處理,通過這一方式規避了數據丟失風險。在被許多消息隊列所采用的”插入-獲取-刪除”范式中,在把一個消息從隊列中刪除之前,需要你的處理過程明確的指出該消息已經被處理完畢,確保你的數據被安全的保存直到你使用完畢。
擴展性
因為消息隊列解耦了你的處理過程,所以增大消息入隊和處理的頻率是很容易的;只要另外增加處理過程即可。不需要改變代碼、不需要調節參數。擴展就像調大電力按鈕一樣簡單。
靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量并不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用消息隊列能夠使關鍵組件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。
可恢復性
當體系的一部分組件失效,不會影響到整個系統。消息隊列降低了進程間的耦合度,所以即使一個處理消息的進程掛掉,加入隊列中的消息仍然可以在系統恢復后被處理。而這種允許重試或者延后處理請求的能力通常是造就一個略感不便的用戶和一個沮喪透頂的用戶之間的區別。
送達保證
消息隊列提供的冗余機制保證了消息能被實際的處理,只要一個進程讀取了該隊列即可。在此基礎上,IronMQ提供了一個”只送達一次”保證。無論有多少進程在從隊列中領取數據,每一個消息只能被處理一次。這之所以成為可能,是因為獲取一個消息只是”預定”了這個消息,暫時把它移出了隊列。除非客戶端明確的表示已經處理完了這個消息,否則這個消息會被放回隊列中去,在一段可配置的時間之后可再次被處理。
順序保證
在大多使用場景下,數據處理的順序都很重要。消息隊列本來就是排序的,并且能保證數據會按照特定的順序來處理。IronMO保證消息通過FIFO(先進先出)的順序來處理,因此消息在隊列中的位置就是從隊列中檢索他們的位置。
緩沖
在任何重要的系統中,都會有需要不同的處理時間的元素。例如,加載一張圖片比應用過濾器花費更少的時間。消息隊列通過一個緩沖層來幫助任務***效率的執行—寫入隊列的處理會盡可能的快速,而不受從隊列讀的預備處理的約束。該緩沖有助于控制和優化數據流經過系統的速度。
理解數據流
在一個分布式系統里,要得到一個關于用戶操作會用多長時間及其原因的總體印象,是個巨大的挑戰。消息系列通過消息被處理的頻率,來方便的輔助確定那些表現不佳的處理過程或領域,這些地方的數據流都不夠優化。
異步通信
很多時候,你不想也不需要立即處理消息。消息隊列提供了異步處理機制,允許你把一個消息放入隊列,但并不立即處理它。你想向隊列中放入多少消息就放多少,然后在你樂意的時候再去處理它們。
RabbitMQ
RabbitMQ是使用Erlang編寫的一個開源的消息隊列,本身支持很多的協議:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量級,更適合于企業級的開發。同時實現了Broker構架,這意味著消息在發送給客戶端時先在中心隊列排隊。對路由,負載均衡或者數據持久化都有很好的支持。
Redis
Redis是一個基于Key-Value對的NoSQL數據庫,開發維護很活躍。雖然它是一個Key-Value數據庫存儲系統,但它本身支持MQ功能,所以完全可以當做一個輕量級的隊列服務來使用。對于RabbitMQ和Redis的入隊和出隊操作,各執行100萬次,每10萬次記錄一次執行時間。測試數據分為128Bytes、512Bytes、1K和10K四個不同大小的數據。實驗表明:入隊時,當數據比較小時Redis的性能要高于RabbitMQ,而如果數據大小超過了10K,Redis則慢的無法忍受;出隊時,無論數據大小,Redis都表現出非常好的性能,而RabbitMQ的出隊性能則遠低于Redis。
ZeroMQ
ZeroMQ號稱最快的消息隊列系統,尤其針對大吞吐量的需求場景。ZMQ能夠實現RabbitMQ不擅長的高級/復雜的隊列,但是開發人員需要自己組合多種技術框架,技術上的復雜度是對這MQ能夠應用成功的挑戰。ZeroMQ具有一個獨特的非中間件的模式,你不需要安裝和運行一個消息服務器或中間件,因為你的應用程序將扮演了這個服務角色。你只需要簡單的引用ZeroMQ程序庫,可以使用NuGet安裝,然后你就可以愉快的在應用程序之間發送消息了。但是ZeroMQ僅提供非持久性的隊列,也就是說如果宕機,數據將會丟失。其中,Twitter的Storm 0.9.0以前的版本中默認使用ZeroMQ作為數據流的傳輸(Storm從0.9版本開始同時支持ZeroMQ和Netty作為傳輸模塊)。
ActiveMQ
ActiveMQ是Apache下的一個子項目。 類似于ZeroMQ,它能夠以代理人和點對點的技術實現隊列。同時類似于RabbitMQ,它少量代碼就可以高效地實現高級應用場景。
Kafka/Jafka
Kafka是Apache下的一個子項目,是一個高性能跨語言分布式發布/訂閱消息隊列系統,而Jafka是在Kafka之上孵化而來的,即Kafka的一個升級版。具有以下特性:快速持久化,可以在O(1)的系統開銷下進行消息持久化;高吞吐,在一臺普通的服務器上既可以達到10W/s的吞吐速率;完全的分布式系統,Broker、Producer、Consumer都原生自動支持分布式,自動實現復雜均衡;支持Hadoop數據并行加載,對于像Hadoop的一樣的日志數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka通過Hadoop的并行加載機制來統一了在線和離線的消息處理。Apache Kafka相對于ActiveMQ是一個非常輕量級的消息系統,除了性能非常好之外,還是一個工作良好的分布式系統。
Terminology
Broker
Kafka集群包含一個或多個服務器,這種服務器被稱為broker
Topic
每條發布到Kafka集群的消息都有一個類別,這個類別被稱為topic。(物理上不同topic的消息分開存儲,邏輯上一個topic的消息雖然保存于一個或多個broker上但用戶只需指定消息的topic即可生產或消費數據而不必關心數據存于何處)
Partition
parition是物理上的概念,每個topic包含一個或多個partition,創建topic時可指定parition數量。每個partition對應于一個文件夾,該文件夾下存儲該partition的數據和索引文件
Producer
負責發布消息到Kafka broker
Consumer
消費消息。每個consumer屬于一個特定的consuer group(可為每個consumer指定group name,若不指定group name則屬于默認的group)。使用consumer high level API時,同一topic的一條消息只能被同一個consumer group內的一個consumer消費,但多個consumer group可同時消費這一消息。
Kafka架構
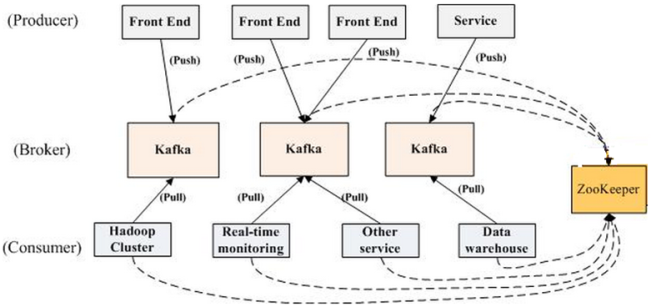
如上圖所示,一個典型的kafka集群中包含若干producer(可以是web前端產生的page view,或者是服務器日志,系統CPU、memory等),若干broker(Kafka支持水平擴展,一般broker數量越多,集群吞吐率越高),若干consumer group,以及一個Zookeeper集群。Kafka通過Zookeeper管理集群配置,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式將消息發布到broker,consumer使用pull模式從broker訂閱并消費消息。
Push vs. Pull
作為一個messaging system,Kafka遵循了傳統的方式,選擇由producer向broker push消息并由consumer從broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事實上,push模式和pull模式各有優劣。
push模式很難適應消費速率不同的消費者,因為消息發送速率是由broker決定的。push模式的目標是盡可能以最快速度傳遞消息,但是這樣很容易造成consumer來不及處理消息,典型的表現就是拒絕服務以及網絡擁塞。而pull模式則可以根據consumer的消費能力以適當的速率消費消息。
Topic & Partition
Topic在邏輯上可以被認為是一個在的queue,每條消費都必須指定它的topic,可以簡單理解為必須指明把這條消息放進哪個queue里。為了使得Kafka的吞吐率可以水平擴展,物理上把topic分成一個或多個partition,每個partition在物理上對應一個文件夾,該文件夾下存儲這個partition的所有消息和索引文件。
每個日志文件都是“log entries”序列,每一個log entry包含一個4字節整型數(值為N),其后跟N個字節的消息體。每條消息都有一個當前partition下唯一的64字節的offset,它指明了這條消息的起始位置。磁盤上存儲的消費格式如下:
message length : 4 bytes (value: 1+4+n)
“magic” value : 1 byte
crc : 4 bytes
payload : n bytes
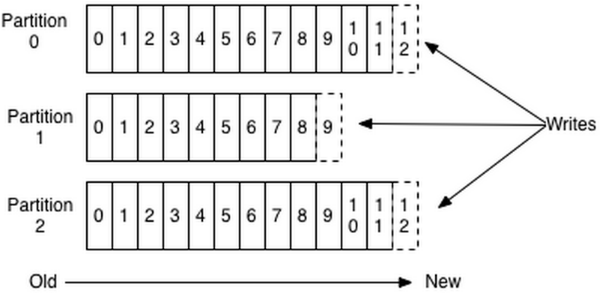
這個“log entries”并非由一個文件構成,而是分成多個segment,每個segment名為該segment***條消息的offset和“.kafka”組成。另外會有一個索引文件,它標明了每個segment下包含的log entry的offset范圍,如下圖所示。
因為每條消息都被append到該partition中,是順序寫磁盤,因此效率非常高(經驗證,順序寫磁盤效率比隨機寫內存還要高,這是Kafka高吞吐率的一個很重要的保證)。
每一條消息被發送到broker時,會根據paritition規則選擇被存儲到哪一個partition。如果partition規則設置的合理,所有消息可以均勻分布到不同的partition里,這樣就實現了水平擴展。(如果一個topic對應一個文件,那這個文件所在的機器I/O將會成為這個topic的性能瓶頸,而partition解決了這個問題)。在創建topic時可以在$KAFKA_HOME/config/server.properties中指定這個partition的數量(如下所示),當然也可以在topic創建之后去修改parition數量。
# The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=3
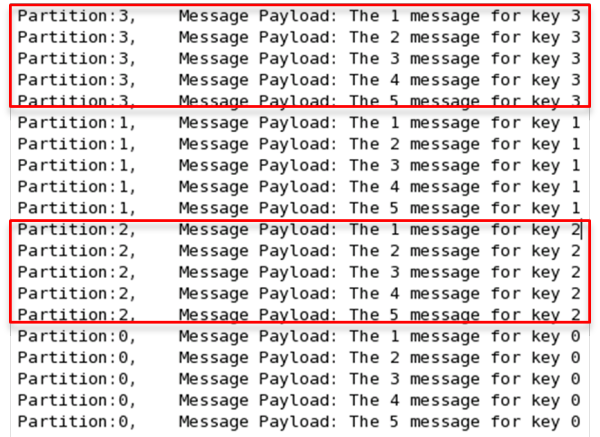
在發送一條消息時,可以指定這條消息的key,producer根據這個key和partition機制來判斷將這條消息發送到哪個parition。paritition機制可以通過指定producer的paritition. class這一參數來指定,該class必須實現kafka.producer.Partitioner接口。本例中如果key可以被解析為整數則將對應的整數與partition總數取余,該消息會被發送到該數對應的partition。(每個parition都會有個序號)
import kafka.producer.Partitioner; import kafka.utils.VerifiableProperties; public class JasonPartitioner<T> implements Partitioner { public JasonPartitioner(VerifiableProperties verifiableProperties) {} @Override public int partition(Object key, int numPartitions) { try { int partitionNum = Integer.parseInt((String) key); return Math.abs(Integer.parseInt((String) key) % numPartitions); } catch (Exception e) { return Math.abs(key.hashCode() % numPartitions); } } }如果將上例中的class作為partition.class,并通過如下代碼發送20條消息(key分別為0,1,2,3)至topic2(包含4個partition)。
public void sendMessage() throws InterruptedException{ for(int i = 1; i <= 5; i++){ List messageList = new ArrayList<KeyedMessage<String, String>>(); for(int j = 0; j < 4; j++){ messageList.add(new KeyedMessage<String, String>("topic2", j+"", "The " + i + " message for key " + j)); } producer.send(messageList); } producer.close(); }則key相同的消息會被發送并存儲到同一個partition里,而且key的序號正好和partition序號相同。(partition序號從0開始,本例中的key也正好從0開始)。如下圖所示。
對于傳統的message queue而言,一般會刪除已經被消費的消息,而Kafka集群會保留所有的消息,無論其被消費與否。當然,因為磁盤限制,不可能***保留所有數據(實際上也沒必要),因此Kafka提供兩種策略去刪除舊數據。一是基于時間,二是基于partition文件大小。例如可以通過配置$KAFKA_HOME/config/server.properties,讓Kafka刪除一周前的數據,也可通過配置讓Kafka在partition文件超過1GB時刪除舊數據,如下所示。
############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=300000 # By default the log cleaner is disabled and the log retention policy will default to #just delete segments after their retention expires. # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs #can then be marked for log compaction. log.cleaner.enable=false
這里要注意,因為Kafka讀取特定消息的時間復雜度為O(1),即與文件大小無關,所以這里刪除文件與Kafka性能無關,選擇怎樣的刪除策略只與磁盤以及具體的需求有關。另外,Kafka會為每一個consumer group保留一些metadata信息—當前消費的消息的position,也即offset。這個offset由consumer控制。正常情況下consumer會在消費完一條消息后線性增加這個offset。當然,consumer也可將offset設成一個較小的值,重新消費一些消息。因為offet由consumer控制,所以Kafka broker是無狀態的,它不需要標記哪些消息被哪些consumer過,不需要通過broker去保證同一個consumer group只有一個consumer能消費某一條消息,因此也就不需要鎖機制,這也為Kafka的高吞吐率提供了有力保障。
Kafka從0.8開始提供partition級別的replication,replication的數量可在$KAFKA_HOME/config/server.properties中配置。
default.replication.factor = 1
該 Replication與leader election配合提供了自動的failover機制。replication對Kafka的吞吐率是有一定影響的,但極大的增強了可用性。默認情況下,Kafka的replication數量為1。每個partition都有一個唯一的leader,所有的讀寫操作都在leader上完成,leader批量從leader上pull數據。一般情況下partition的數量大于等于broker的數量,并且所有partition的leader均勻分布在broker上。follower上的日志和其leader上的完全一樣。
和大部分分布式系統一樣,Kakfa處理失敗需要明確定義一個broker是否alive。對于Kafka而言,Kafka存活包含兩個條件,一是它必須維護與Zookeeper的session(這個通過Zookeeper的heartbeat機制來實現)。二是follower必須能夠及時將leader的writing復制過來,不能“落后太多”。
leader會track“in sync”的node list。如果一個follower宕機,或者落后太多,leader將把它從”in sync” list中移除。這里所描述的“落后太多”指follower復制的消息落后于leader后的條數超過預定值,該值可在$KAFKA_HOME/config/server.properties中配置
#If a replica falls more than this many messages behind the leader, the leader will remove the follower from ISR and treat it as dead replica.lag.max.messages=4000 #If a follower hasn't sent any fetch requests for this window of time, the leader will remove the follower from ISR (in-sync replicas) and treat it as dead replica.lag.time.max.ms=10000
需要說明的是,Kafka只解決”fail/recover”,不處理“Byzantine”(“拜占庭”)問題。
一條消息只有被“in sync” list里的所有follower都從leader復制過去才會被認為已提交。這樣就避免了部分數據被寫進了leader,還沒來得及被任何follower復制就宕機了,而造成數據丟失(consumer無法消費這些數據)。而對于producer而言,它可以選擇是否等待消息commit,這可以通過request.required.acks來設置。這種機制確保了只要“in sync” list有一個或以上的flollower,一條被commit的消息就不會丟失。
這里的復制機制即不是同步復制,也不是單純的異步復制。事實上,同步復制要求“活著的”follower都復制完,這條消息才會被認為commit,這種復制方式極大的影響了吞吐率(高吞吐率是Kafka非常重要的一個特性)。而異步復制方式下,follower異步的從leader復制數據,數據只要被leader寫入log就被認為已經commit,這種情況下如果follwer都落后于leader,而leader突然宕機,則會丟失數據。而Kafka的這種使用“in sync” list的方式則很好的均衡了確保數據不丟失以及吞吐率。follower可以批量的從leader復制數據,這樣極大的提高復制性能(批量寫磁盤),極大減少了follower與leader的差距(前文有說到,只要follower落后leader不太遠,則被認為在“in sync” list里)。
上文說明了Kafka是如何做replication的,另外一個很重要的問題是當leader宕機了,怎樣在follower中選舉出新的leader。因為follower可能落后許多或者crash了,所以必須確保選擇“***”的follower作為新的leader。一個基本的原則就是,如果leader不在了,新的leader必須擁有原來的leader commit的所有消息。這就需要作一個折衷,如果leader在標明一條消息被commit前等待更多的follower確認,那在它die之后就有更多的follower可以作為新的leader,但這也會造成吞吐率的下降。
一種非常常用的選舉leader的方式是“majority 靈秀”(“少數服從多數”),但Kafka并未采用這種方式。這種模式下,如果我們有2f+1個replica(包含leader和follower),那在commit之前必須保證有f+1個replica復制完消息,為了保證正確選出新的leader,fail的replica不能超過f個。因為在剩下的任意f+1個replica里,至少有一個replica包含有***的所有消息。這種方式有個很大的優勢,系統的latency只取決于最快的幾臺server,也就是說,如果replication factor是3,那latency就取決于最快的那個follower而非最慢那個。majority vote也有一些劣勢,為了保證leader election的正常進行,它所能容忍的fail的follower個數比較少。如果要容忍1個follower掛掉,必須要有3個以上的replica,如果要容忍2個follower掛掉,必須要有5個以上的replica。也就是說,在生產環境下為了保證較高的容錯程度,必須要有大量的replica,而大量的replica又會在大數據量下導致性能的急劇下降。這就是這種算法更多用在Zookeeper這種共享集群配置的系統中而很少在需要存儲大量數據的系統中使用的原因。例如HDFS的HA feature是基于majority-vote-based journal,但是它的數據存儲并沒有使用這種expensive的方式。
實際上,leader election算法非常多,比如Zookeper的Zab, Raft和Viewstamped Replication。而Kafka所使用的leader election算法更像微軟的PacificA算法。
Kafka在Zookeeper中動態維護了一個ISR(in-sync replicas) set,這個set里的所有replica都跟上了leader,只有ISR里的成員才有被選為leader的可能。在這種模式下,對于f+1個replica,一個Kafka topic能在保證不丟失已經ommit的消息的前提下容忍f個replica的失敗。在大多數使用場景中,這種模式是非常有利的。事實上,為了容忍f個replica的失敗,majority vote和ISR在commit前需要等待的replica數量是一樣的,但是ISR需要的總的replica的個數幾乎是majority vote的一半。
雖然majority vote與ISR相比有不需等待最慢的server這一優勢,但是Kafka作者認為Kafka可以通過producer選擇是否被commit阻塞來改善這一問題,并且節省下來的replica和磁盤使得ISR模式仍然值得。
上文提到,在ISR中至少有一個follower時,Kafka可以確保已經commit的數據不丟失,但如果某一個partition的所有replica都掛了,就無法保證數據不丟失了。這種情況下有兩種可行的方案:
等待ISR中的任一個replica“活”過來,并且選它作為leader
選擇***個“活”過來的replica(不一定是ISR中的)作為leader
這就需要在可用性和一致性當中作出一個簡單的平衡。如果一定要等待ISR中的replica“活”過來,那不可用的時間就可能會相對較長。而且如果ISR中的所有replica都無法“活”過來了,或者數據都丟失了,這個partition將永遠不可用。選擇***個“活”過來的replica作為leader,而這個replica不是ISR中的replica,那即使它并不保證已經包含了所有已commit的消息,它也會成為leader而作為consumer的數據源(前文有說明,所有讀寫都由leader完成)。Kafka0.8.*使用了第二種方式。根據Kafka的文檔,在以后的版本中,Kafka支持用戶通過配置選擇這兩種方式中的一種,從而根據不同的使用場景選擇高可用性還是強一致性。
上文說明了一個parition的replication過程,然爾Kafka集群需要管理成百上千個partition,Kafka通過round-robin的方式來平衡partition從而避免大量partition集中在了少數幾個節點上。同時Kafka也需要平衡leader的分布,盡可能的讓所有partition的leader均勻分布在不同broker上。另一方面,優化leadership election的過程也是很重要的,畢竟這段時間相應的partition處于不可用狀態。一種簡單的實現是暫停宕機的broker上的所有partition,并為之選舉leader。實際上,Kafka選舉一個broker作為controller,這個controller通過watch Zookeeper檢測所有的broker failure,并負責為所有受影響的parition選舉leader,再將相應的leader調整命令發送至受影響的broker,過程如下圖所示。
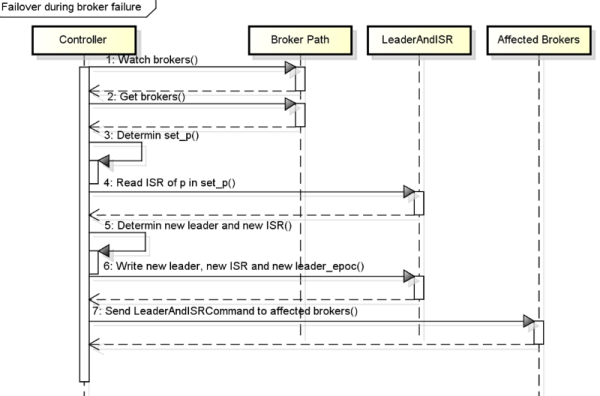
這樣做的好處是,可以批量的通知leadership的變化,從而使得選舉過程成本更低,尤其對大量的partition而言。如果controller失敗了,幸存的所有broker都會嘗試在Zookeeper中創建/controller->{this broker id},如果創建成功(只可能有一個創建成功),則該broker會成為controller,若創建不成功,則該broker會等待新controller的命令。
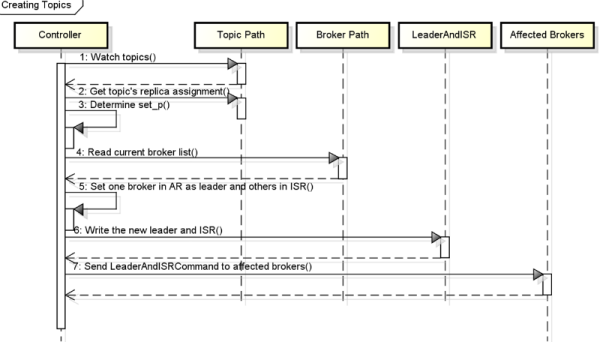
(本節所有描述都是基于consumer hight level API而非low level API)。
每一個consumer實例都屬于一個consumer group,每一條消息只會被同一個consumer group里的一個consumer實例消費。(不同consumer group可以同時消費同一條消息)
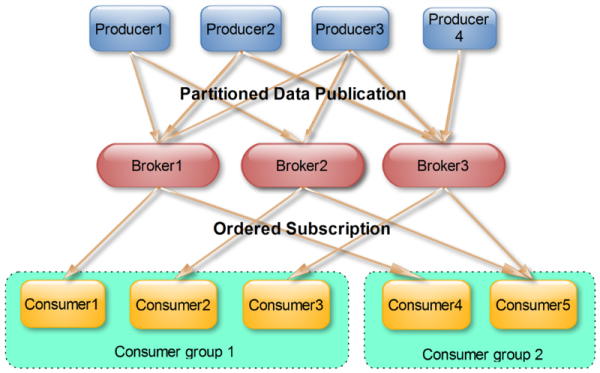
很多傳統的message queue都會在消息被消費完后將消息刪除,一方面避免重復消費,另一方面可以保證queue的長度比較少,提高效率。而如上文所將,Kafka并不刪除已消費的消息,為了實現傳統message queue消息只被消費一次的語義,Kafka保證保證同一個consumer group里只有一個consumer會消費一條消息。與傳統message queue不同的是,Kafka還允許不同consumer group同時消費同一條消息,這一特性可以為消息的多元化處理提供了支持。實際上,Kafka的設計理念之一就是同時提供離線處理和實時處理。根據這一特性,可以使用Storm這種實時流處理系統對消息進行實時在線處理,同時使用Hadoop這種批處理系統進行離線處理,還可以同時將數據實時備份到另一個數據中心,只需要保證這三個操作所使用的consumer在不同的consumer group即可。下圖展示了Kafka在Linkedin的一種簡化部署。
為了更清晰展示Kafka consumer group的特性,筆者作了一項測試。創建一個topic (名為topic1),創建一個屬于group1的consumer實例,并創建三個屬于group2的consumer實例,然后通過producer向topic1發送key分別為1,2,3r的消息。結果發現屬于group1的consumer收到了所有的這三條消息,同時group2中的3個consumer分別收到了key為1,2,3的消息。如下圖所示。
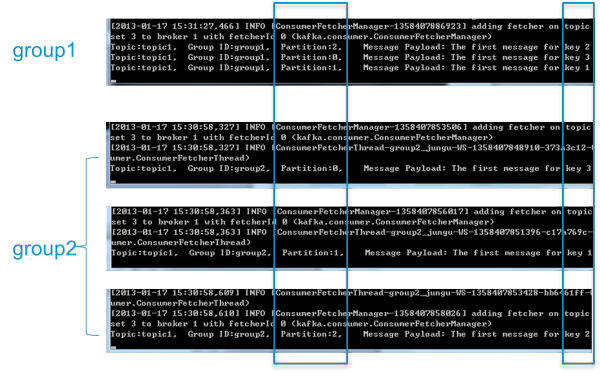
(本節所講述內容均基于Kafka consumer high level API)
Kafka保證同一consumer group中只有一個consumer會消息某條消息,實際上,Kafka保證的是穩定狀態下每一個consumer實例只會消費某一個或多個特定partition的數據,而某個partition的數據只會被某一個特定的consumer實例所消費。這樣設計的劣勢是無法讓同一個consumer group里的consumer均勻消費數據,優勢是每個consumer不用都跟大量的broker通信,減少通信開銷,同時也降低了分配難度,實現也更簡單。另外,因為同一個partition里的數據是有序的,這種設計可以保證每個partition里的數據也是有序被消費。
如果某consumer group中consumer數量少于partition數量,則至少有一個consumer會消費多個partition的數據,如果consumer的數量與partition數量相同,則正好一個consumer消費一個partition的數據,而如果consumer的數量多于partition的數量時,會有部分consumer無法消費該topic下任何一條消息。
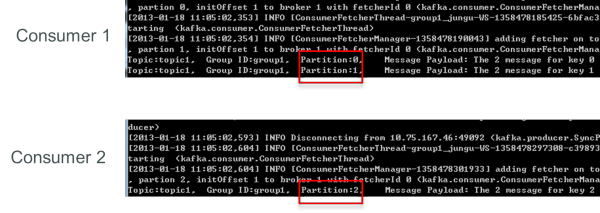
如下例所示,如果topic1有0,1,2共三個partition,當group1只有一個consumer(名為consumer1)時,該 consumer可消費這3個partition的所有數據。

增加一個consumer(consumer2)后,其中一個consumer(consumer1)可消費2個partition的數據,另外一個consumer(consumer2)可消費另外一個partition的數據。
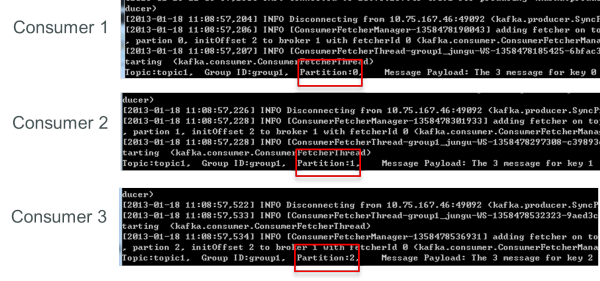
再增加一個consumer(consumer3)后,每個consumer可消費一個partition的數據。consumer1消費partition0,consumer2消費partition1,consumer3消費partition2
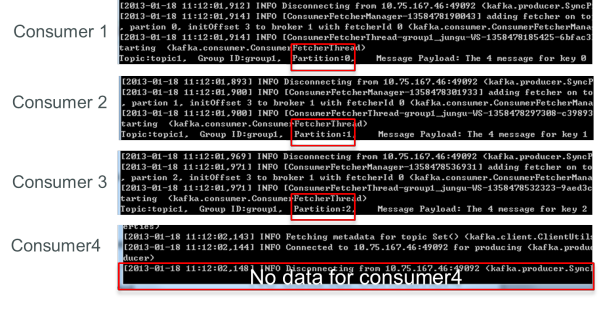
再增加一個consumer(consumer4)后,其中3個consumer可分別消費一個partition的數據,另外一個consumer(consumer4)不能消費topic1任何數據。
此時關閉consumer1,剩下的consumer可分別消費一個partition的數據。
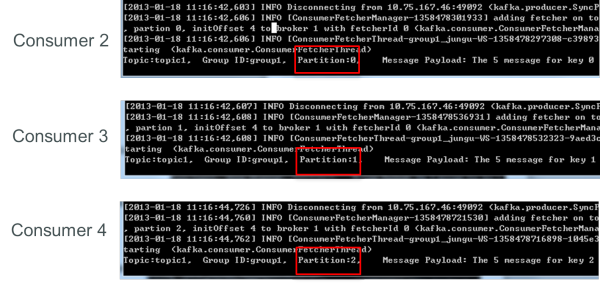
接著關閉consumer2,剩下的consumer3可消費2個partition,consumer4可消費1個partition。
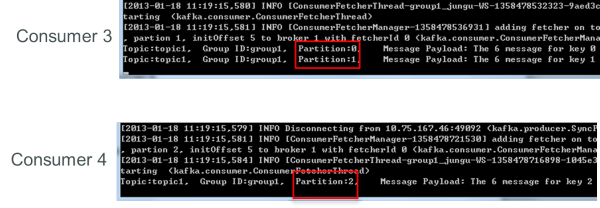
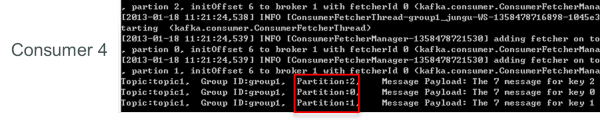
再關閉consumer3,剩下的consumer4可同時消費topic1的3個partition。
consumer rebalance算法如下:
Sort PT (all partitions in topic T)
Sort CG(all consumers in consumer group G)
Let i be the index position of Ci in CG and let N=size(PT)/size(CG)
Remove current entries owned by Ci from the partition owner registry
Assign partitions from iN to (i+1)N-1 to consumer Ci
Add newly assigned partitions to the partition owner registry
目前consumer rebalance的控制策略是由每一個consumer通過Zookeeper完成的。具體的控制方式如下:
Register itself in the consumer id registry under its group.
Register a watch on changes under the consumer id registry.
Register a watch on changes under the broker id registry.
If the consumer creates a message stream using a topic filter, it also registers a watch on changes under the broker topic registry.
Force itself to rebalance within in its consumer group.
在這種策略下,每一個consumer或者broker的增加或者減少都會觸發consumer rebalance。因為每個consumer只負責調整自己所消費的partition,為了保證整個consumer group的一致性,所以當一個consumer觸發了rebalance時,該consumer group內的其它所有consumer也應該同時觸發rebalance。
目前(2015-01-19)***版(0.8.2)Kafka采用的是上述方式。但該方式有不利的方面:
Herd effect
任何broker或者consumer的增減都會觸發所有的consumer的rebalance
Split Brain
每個consumer分別單獨通過Zookeeper判斷哪些partition down了,那么不同consumer從Zookeeper“看”到的view就可能不一樣,這就會造成錯誤的reblance嘗試。而且有可能所有的consumer都認為rebalance已經完成了,但實際上可能并非如此。
根據Kafka官方文檔,Kafka作者正在考慮在還未發布的0.9.x版本中使用中心協調器(coordinator)。大體思想是選舉出一個broker作為coordinator,由它watch Zookeeper,從而判斷是否有partition或者consumer的增減,然后生成rebalance命令,并檢查是否這些rebalance在所有相關的consumer中被執行成功,如果不成功則重試,若成功則認為此次rebalance成功(這個過程跟replication controller非常類似,所以我很奇怪為什么當初設計replication controller時沒有使用類似方式來解決consumer rebalance的問題)。流程如下:
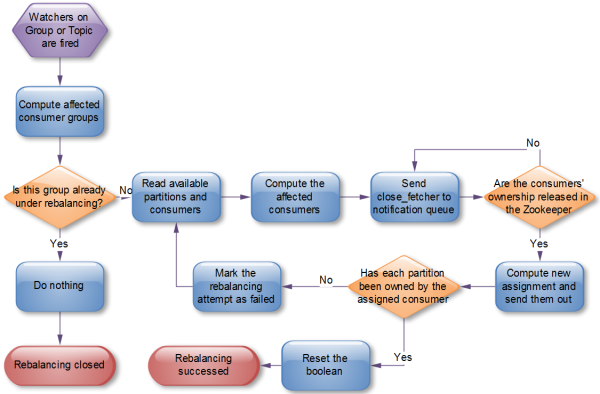
通過上文介紹,想必讀者已經明天了producer和consumer是如何工作的,以及Kafka是如何做replication的,接下來要討論的是Kafka如何確保消息在producer和consumer之間傳輸。有這么幾種可能的delivery guarantee:
At most once 消息可能會丟,但絕不會重復傳輸
At least one 消息絕不會丟,但可能會重復傳輸
Exactly once 每條消息肯定會被傳輸一次且僅傳輸一次,很多時候這是用戶所想要的。
Kafka的delivery guarantee semantic非常直接。當producer向broker發送消息時,一旦這條消息被commit,因數replication的存在,它就不會丟。但是如果producer發送數據給broker后,遇到的網絡問題而造成通信中斷,那producer就無法判斷該條消息是否已經commit。這一點有點像向一個自動生成primary key的數據庫表中插入數據。雖然Kafka無法確定網絡故障期間發生了什么,但是producer可以生成一種類似于primary key的東西,發生故障時冪等性的retry多次,這樣就做到了Exactly one。截止到目前(Kafka 0.8.2版本,2015-01-25),這一feature還并未實現,有希望在Kafka未來的版本中實現。(所以目前默認情況下一條消息從producer和broker是確保了At least once,但可通過設置producer異步發送實現At most once)。
接下來討論的是消息從broker到consumer的delivery guarantee semantic。(僅針對Kafka consumer high level API)。consumer在從broker讀取消息后,可以選擇commit,該操作會在Zookeeper中存下該consumer在該partition下讀取的消息的offset。該consumer下一次再讀該partition時會從下一條開始讀取。如未commit,下一次讀取的開始位置會跟上一次commit之后的開始位置相同。當然可以將consumer設置為autocommit,即consumer一旦讀到數據立即自動commit。如果只討論這一讀取消息的過程,那Kafka是確保了Exactly once。但實際上實際使用中consumer并非讀取完數據就結束了,而是要進行進一步處理,而數據處理與commit的順序在很大程度上決定了消息從broker和consumer的delivery guarantee semantic。
讀完消息先commit再處理消息。這種模式下,如果consumer在commit后還沒來得及處理消息就crash了,下次重新開始工作后就無法讀到剛剛已提交而未處理的消息,這就對應于At most once
讀完消息先處理再commit。這種模式下,如果處理完了消息在commit之前consumer crash了,下次重新開始工作時還會處理剛剛未commit的消息,實際上該消息已經被處理過了。這就對應于At least once。在很多情況使用場景下,消息都有一個primary key,所以消息的處理往往具有冪等性,即多次處理這一條消息跟只處理一次是等效的,那就可以認為是Exactly once。(人個感覺這種說法有些牽強,畢竟它不是Kafka本身提供的機制,而且primary key本身不保證操作的冪等性。而且實際上我們說delivery guarantee semantic是討論被處理多少次,而非處理結果怎樣,因為處理方式多種多樣,我們的系統不應該把處理過程的特性—如是否冪等性,當成Kafka本身的feature)
如果一定要做到Exactly once,就需要協調offset和實際操作的輸出。精典的做法是引入兩階段提交。如果能讓offset和操作輸入存在同一個地方,會更簡潔和通用。這種方式可能更好,因為許多輸出系統可能不支持兩階段提交。比如,consumer拿到數據后可能把數據放到HDFS,如果把***的offset和數據本身一起寫到HDFS,那就可以保證數據的輸出和offset的更新要么都完成,要么都不完成,間接實現Exactly once。(目前就high level API而言,offset是存于Zookeeper中的,無法存于HDFS,而low level API的offset是由自己去維護的,可以將之存于HDFS中)
總之,Kafka默認保證At least once,并且允許通過設置producer異步提交來實現At most once。而Exactly once要求與目標存儲系統協作,幸運的是Kafka提供的offset可以使用這種方式非常直接非常容易。
紙上得來終覺淺,絕知些事要躬行。筆者希望能親自測一下Kafka的性能,而非從網上找一些測試數據。所以筆者曾在0.8發布前兩個月做過詳細的Kafka0.8性能測試,不過很可惜測試報告不慎丟失。所幸在網上找到了Kafka的創始人之一的Jay Kreps的bechmark。以下描述皆基于該benchmark。(該benchmark基于Kafka0.8.1)
該benchmark用到了六臺機器,機器配置如下
Intel Xeon 2.5 GHz processor with six cores
Six 7200 RPM SATA drives
32GB of RAM
1Gb Ethernet
這6臺機器其中3臺用來搭建Kafka broker集群,另外3臺用來安裝Zookeeper及生成測試數據。6個drive都直接以非RAID方式掛載。實際上kafka對機器的需求與Hadoop的類似。
該項測試只測producer的吞吐率,也就是數據只被持久化,沒有consumer讀數據。
在這一測試中,創建了一個包含6個partition且沒有replication的topic。然后通過一個線程盡可能快的生成50 million條比較短(payload100字節長)的消息。測試結果是821,557 records/second(78.3MB/second)。
之所以使用短消息,是因為對于消息系統來說這種使用場景更難。因為如果使用MB/second來表征吞吐率,那發送長消息無疑能使得測試結果更好。
整個測試中,都是用每秒鐘delivery的消息的數量乘以payload的長度來計算MB/second的,沒有把消息的元信息算在內,所以實際的網絡使用量會比這個大。對于本測試來說,每次還需傳輸額外的22個字節,包括一個可選的key,消息長度描述,CRC等。另外,還包含一些請求相關的overhead,比如topic,partition,acknowledgement等。這就導致我們比較難判斷是否已經達到網卡極限,但是把這些overhead都算在吞吐率里面應該更合理一些。因此,我們已經基本達到了網卡的極限。
初步觀察此結果會認為它比人們所預期的要高很多,尤其當考慮到Kafka要把數據持久化到磁盤當中。實際上,如果使用隨機訪問數據系統,比如RDBMS,或者key-velue store,可預期的***訪問頻率大概是5000到50000個請求每秒,這和一個好的RPC層所能接受的遠程請求量差不多。而該測試中遠超于此的原因有兩個。
Kafka確保寫磁盤的過程是線性磁盤I/O,測試中使用的6塊廉價磁盤線性I/O的***吞吐量是822MB/second,這已經遠大于1Gb網卡所能帶來的吞吐量了。許多消息系統把數據持久化到磁盤當成是一個開銷很大的事情,這是因為他們對磁盤的操作都不是線性I/O。
在每一個階段,Kafka都盡量使用批量處理。如果想了解批處理在I/O操作中的重要性,可以參考David Patterson的”Latency Lags Bandwidth“
該項測試與上一測試基本一樣,唯一的區別是每個partition有3個replica(所以網絡傳輸的和寫入磁盤的總的數據量增加了3倍)。每一個broker即要寫作為leader的partition,也要讀(從leader讀數據)寫(將數據寫到磁盤)作為follower的partition。測試結果為786,980 records/second(75.1MB/second)。
該項測試中replication是異步的,也就是說broker收到數據并寫入本地磁盤后就acknowledge producer,而不必等所有replica都完成replication。也就是說,如果leader crash了,可能會丟掉一些***的還未備份的數據。但這也會讓message acknowledgement延遲更少,實時性更好。
這項測試說明,replication可以很快。整個集群的寫能力可能會由于3倍的replication而只有原來的三分之一,但是對于每一個producer來說吞吐率依然足夠好。
該項測試與上一測試的唯一區別是replication是同步的,每條消息只有在被in sync集合里的所有replica都復制過去后才會被置為committed(此時broker會向producer發送acknowledgement)。在這種模式下,Kafka可以保證即使leader crash了,也不會有數據丟失。測試結果為421,823 records/second(40.2MB/second)。
Kafka同步復制與異步復制并沒有本質的不同。leader會始終track follower replica從而監控它們是否還alive,只有所有in sync集合里的replica都acknowledge的消息才可能被consumer所消費。而對follower的等待影響了吞吐率。可以通過增大batch size來改善這種情況,但為了避免特定的優化而影響測試結果的可比性,本次測試并沒有做這種調整。
該測試相當于把上文中的1個producer,復制到了3臺不同的機器上(在1臺機器上跑多個實例對吞吐率的增加不會有太大幫忙,因為網卡已經基本飽和了),這3個producer同時發送數據。整個集群的吞吐率為2,024,032 records/second(193,0MB/second)。
消息系統的一個潛在的危險是當數據能都存于內存時性能很好,但當數據量太大無法完全存于內存中時(然后很多消息系統都會刪除已經被消費的數據,但當消費速度比生產速度慢時,仍會造成數據的堆積),數據會被轉移到磁盤,從而使得吞吐率下降,這又反過來造成系統無法及時接收數據。這樣就非常糟糕,而實際上很多情景下使用queue的目的就是解決數據消費速度和生產速度不一致的問題。
但Kafka不存在這一問題,因為Kafka始終以O(1)的時間復雜度將數據持久化到磁盤,所以其吞吐率不受磁盤上所存儲的數據量的影響。為了驗證這一特性,做了一個長時間的大數據量的測試,下圖是吞吐率與數據量大小的關系圖。
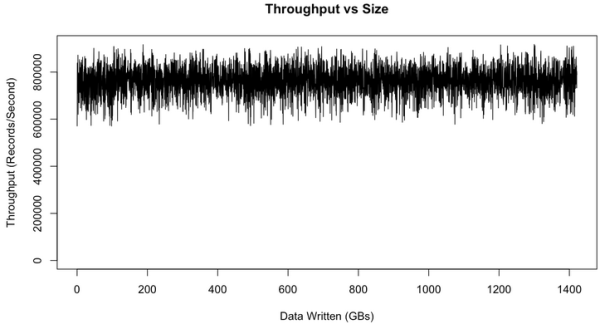
上圖中有一些variance的存在,并可以明顯看到,吞吐率并不受磁盤上所存數據量大小的影響。實際上從上圖可以看到,當磁盤數據量達到1TB時,吞吐率和磁盤數據只有幾百MB時沒有明顯區別。
這個variance是由Linux I/O管理造成的,它會把數據緩存起來再批量flush。上圖的測試結果是在生產環境中對Kafka集群做了些tuning后得到的,這些tuning方法可參考這里。
需要注意的是,replication factor并不會影響consumer的吞吐率測試,因為consumer只會從每個partition的leader讀數據,而與replicaiton factor無關。同樣,consumer吞吐率也與同步復制還是異步復制無關。
該測試從有6個partition,3個replication的topic消費50 million的消息。測試結果為940,521 records/second(89.7MB/second)。
可以看到,Kafkar的consumer是非常高效的。它直接從broker的文件系統里讀取文件塊。Kafka使用sendfile API來直接通過操作系統直接傳輸,而不用把數據拷貝到用戶空間。該項測試實際上從log的起始處開始讀數據,所以它做了真實的I/O。在生產環境下,consumer可以直接讀取producer剛剛寫下的數據(它可能還在緩存中)。實際上,如果在生產環境下跑I/O stat,你可以看到基本上沒有物理“讀”。也就是說生產環境下consumer的吞吐率會比該項測試中的要高。
將上面的consumer復制到3臺不同的機器上,并且并行運行它們(從同一個topic上消費數據)。測試結果為2,615,968 records/second(249.5MB/second)。
正如所預期的那樣,consumer的吞吐率幾乎線性增漲。
上面的測試只是把producer和consumer分開測試,而該項測試同時運行producer和consumer,這更接近使用場景。實際上目前的replication系統中follower就相當于consumer在工作。
該項測試,在具有6個partition和3個replica的topic上同時使用1個producer和1個consumer,并且使用異步復制。測試結果為795,064 records/second(75.8MB/second)。
可以看到,該項測試結果與單獨測試1個producer時的結果幾乎一致。所以說consumer非常輕量級。
上面的所有測試都基于短消息(payload 100字節),而正如上文所說,短消息對Kafka來說是更難處理的使用方式,可以預期,隨著消息長度的增大,records/second會減小,但MB/second會有所提高。下圖是records/second與消息長度的關系圖。
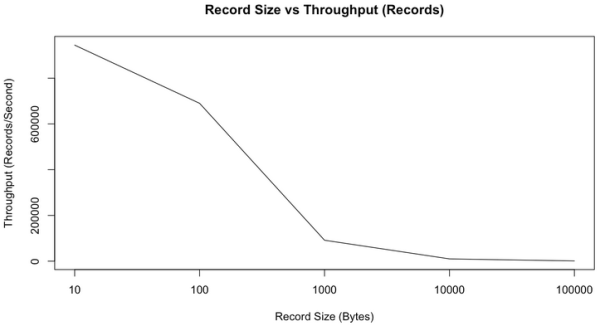
正如我們所預期的那樣,隨著消息長度的增加,每秒鐘所能發送的消息的數量逐漸減小。但是如果看每秒鐘發送的消息的總大小,它會隨著消息長度的增加而增加,如下圖所示。
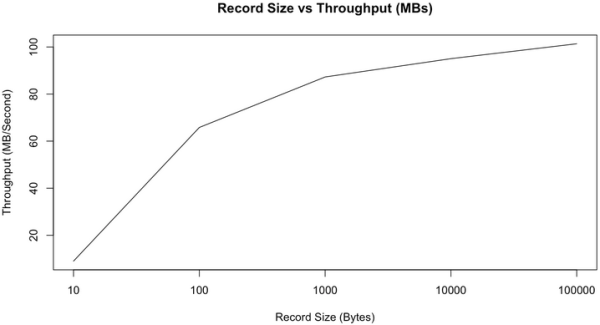
從上圖可以看出,當消息長度為10字節時,因為要頻繁入隊,花了太多時間獲取鎖,CPU成了瓶頸,并不能充分利用帶寬。但從100字節開始,我們可以看到帶寬的使用逐漸趨于飽和(雖然MB/second還是會隨著消息長度的增加而增加,但增加的幅度也越來越小)。
上文中討論了吞吐率,那消息傳輸的latency如何呢?也就是說消息從producer到consumer需要多少時間呢?該項測試創建1個producer和1個consumer并反復計時。結果是,2 ms (median), 3ms (99th percentile, 14ms (99.9th percentile)。
(這里并沒有說明topic有多少個partition,也沒有說明有多少個replica,replication是同步還是異步。實際上這會極大影響producer發送的消息被commit的latency,而只有committed的消息才能被consumer所消費,所以它會最終影響端到端的latency)
如果讀者想要在自己的機器上重現本次benchmark測試,可以參考本次測試的配置和所使用的命令。
實際上Kafka Distribution提供了producer性能測試工具,可通過bin/kafka-producer-perf-test.sh腳本來啟動。所使用的命令如下
Producer Setup bin/kafka-topics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topic test-rep-one --partitions 6 --replication-factor 1 bin/kafka-topics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topic test --partitions 6 --replication-factor 3 Single thread, no replication bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test7 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196 Single-thread, async 3x replication bin/kafktopics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topic test --partitions 6 --replication-factor 3 bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test6 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196 Single-thread, sync 3x replication bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test 50000000 100 -1 acks=-1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=64000 Three Producers, 3x async replication bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196 Throughput Versus Stored Data bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test 50000000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196 Effect of message size for i in 10 100 1000 10000 100000; do echo "" echo $i bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test $((1000*1024*1024/$i)) $i -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=128000 done; Consumer Consumer throughput bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topic test --threads 1 3 Consumers On three servers, run: bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topic test --threads 1 End-to-end Latency bin/kafka-run-class.sh kafka.tools.TestEndToEndLatency esv4-hcl198.grid.linkedin.com:9092 esv4-hcl197.grid.linkedin.com:2181 test 5000 Producer and consumer bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance test 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196 bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topic test --threads 1
broker配置如下
############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=0 ############################# Socket Server Settings ############################# # The port the socket server listens on port=9092 # Hostname the broker will bind to and advertise to producers and consumers. # If not set, the server will bind to all interfaces and advertise the value returned from # from java.net.InetAddress.getCanonicalHostName(). #host.name=localhost # The number of threads handling network requests num.network.threads=4 # The number of threads doing disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=1048576 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=1048576 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics ############################# # The directory under which to store log files log.dirs=/grid/a/dfs-data/kafka-logs,/grid/b/dfs-data/kafka-logs,/grid/c/dfs-data/kafka-logs,/grid/d/dfs-data/kafka-logs,/grid/e/dfs-data/kafka-logs,/grid/f/dfs-data/kafka-logs # The number of logical partitions per topic per server. More partitions allow greater parallelism # for consumption, but also mean more files. num.partitions=8 ############################# Log Flush Policy ############################# # The following configurations control the flush of data to disk. This is the most # important performance knob in kafka. # There are a few important trade-offs here: # 1. Durability: Unflushed data is at greater risk of loss in the event of a crash. # 2. Latency: Data is not made available to consumers until it is flushed (which adds latency). # 3. Throughput: The flush is generally the most expensive operation. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # Per-topic overrides for log.flush.interval.ms #log.flush.intervals.ms.per.topic=topic1:1000, topic2:3000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.cleanup.interval.mins=1 ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=esv4-hcl197.grid.linkedin.com:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=1000000 # metrics reporter properties kafka.metrics.polling.interval.secs=5 kafkakafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter kafka.csv.metrics.dir=/tmp/kafka_metrics # Disable csv reporting by default. kafka.csv.metrics.reporter.enabled=false replica.lag.max.messages=10000000
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





