溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“怎么在CDH中啟用Spark Thrift”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“怎么在CDH中啟用Spark Thrift”這篇文章吧。
2.部署Spark-assembly Jar包
1.下載spark-1.6.3-bin-hadoop2.6.tgz,下載地址如下:
https://www.apache.org/dyn/closer.lua/spark/spark-1.6.3/spark-1.6.3-bin-hadoop2.6.tgz
2.將下載的spark-1.6.3-bin-hadoop2.6.tgz上傳至集群的任意節點并解壓,這里以cdh02節點為例
[root@cdh02 ~]# tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz
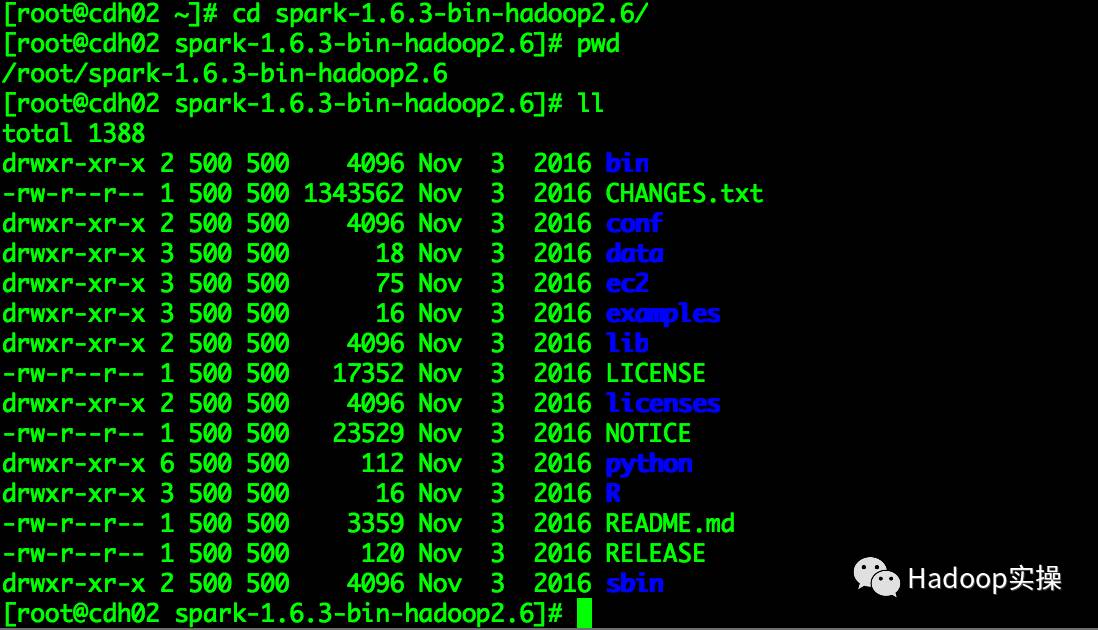
3.將解壓出來的spark-assembly-1.6.3-hadoop2.6.0.jar拷貝至CDH的jars目錄
[root@cdh02 spark-1.6.3-bin-hadoop2.6]# scp /root/spark-1.6.3-bin-hadoop2.6/lib/spark-assembly-1.6.3-hadoop2.6.0.jar /opt/cloudera/parcels/CDH/jars/
4.替換CDH中spark默認的spark-assembly jar包
[root@cdh02 lib]# cd /opt/cloudera/parcels/CDH/lib/spark/lib
[root@cdh02 lib]# rm -rf spark-assembly-1.6.0-cdh6.13.0-hadoop2.6.0-cdh6.13.0.jar
[root@cdh02 lib]# ln -s ../../../jars/spark-assembly-1.6.3-hadoop2.6.0.jar spark-assembly-1.6.0-cdh6.13.0-hadoop2.6.0-cdh6.13.0.jar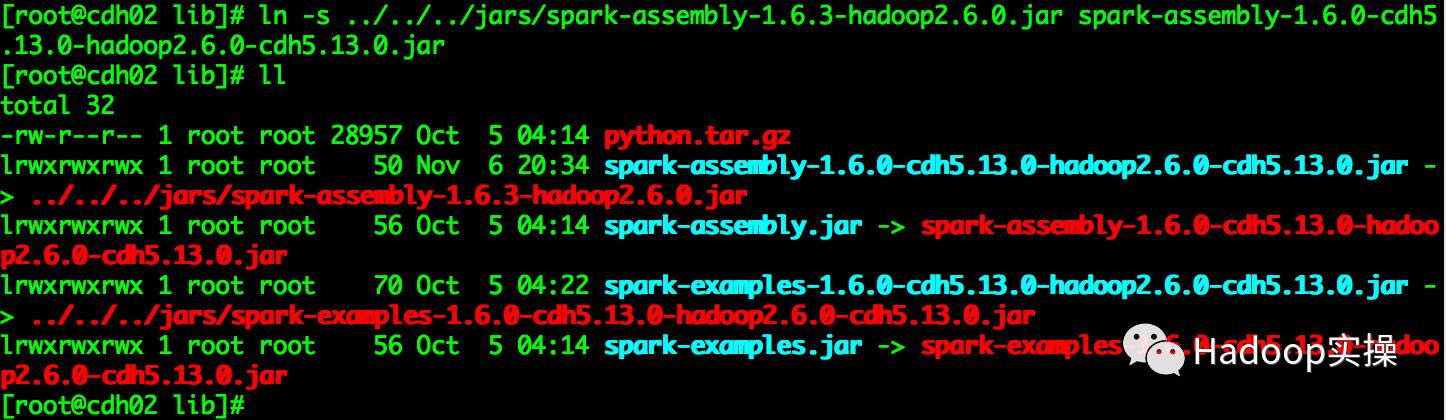
5.將spark-assembly-1.6.3-hadoop2.6.0.jar包上傳至HDFS目錄
[root@cdh02 lib]# sudo -u spark hadoop fs -mkdir -p /user/spark/share/lib
[root@cdh02 lib]# sudo -u spark hadoop fs -put /opt/cloudera/parcels/CDH/jars/spark-assembly-1.6.3-hadoop2.6.0.jar /user/spark/share/lib
[root@cdh02 lib]# sudo -u spark hadoop fs -chmod 755 /user/spark/share/lib/spark-assembly-1.6.3-hadoop2.6.0.jar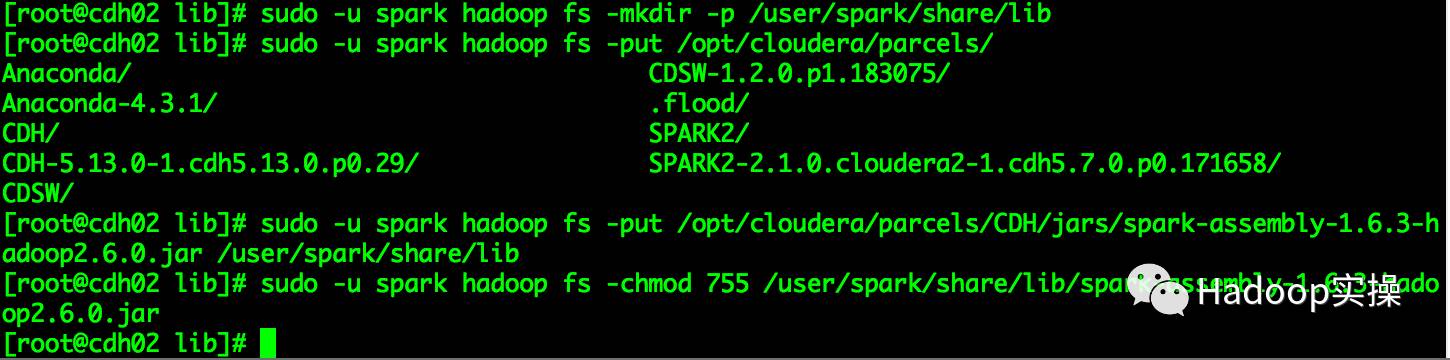
6.在CM上對Spark進行配置,配置如下:
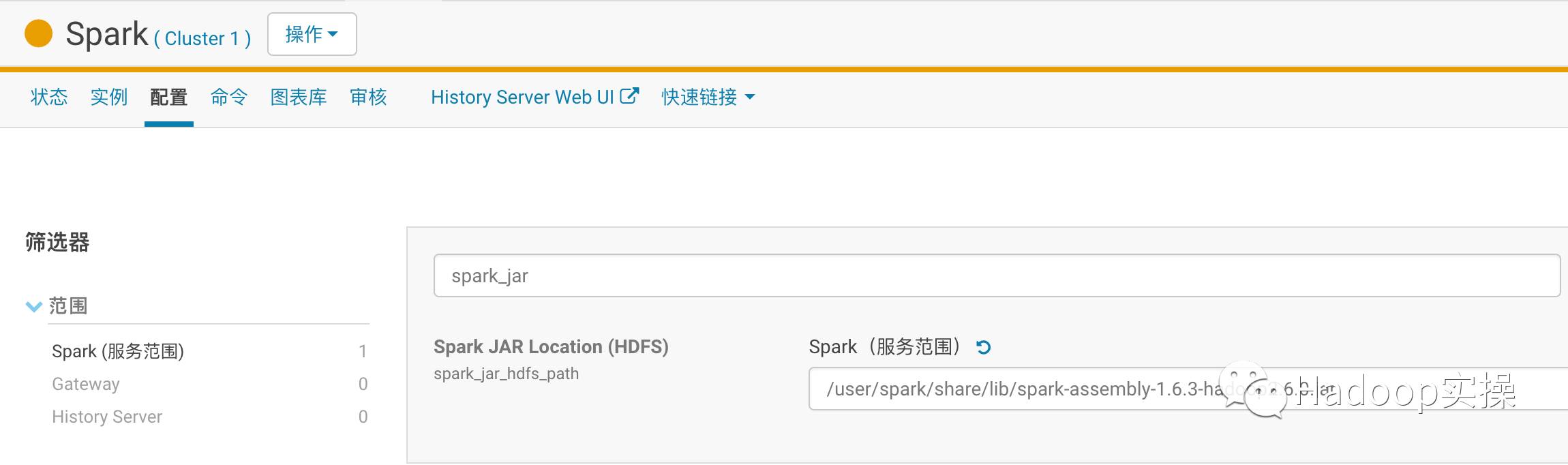
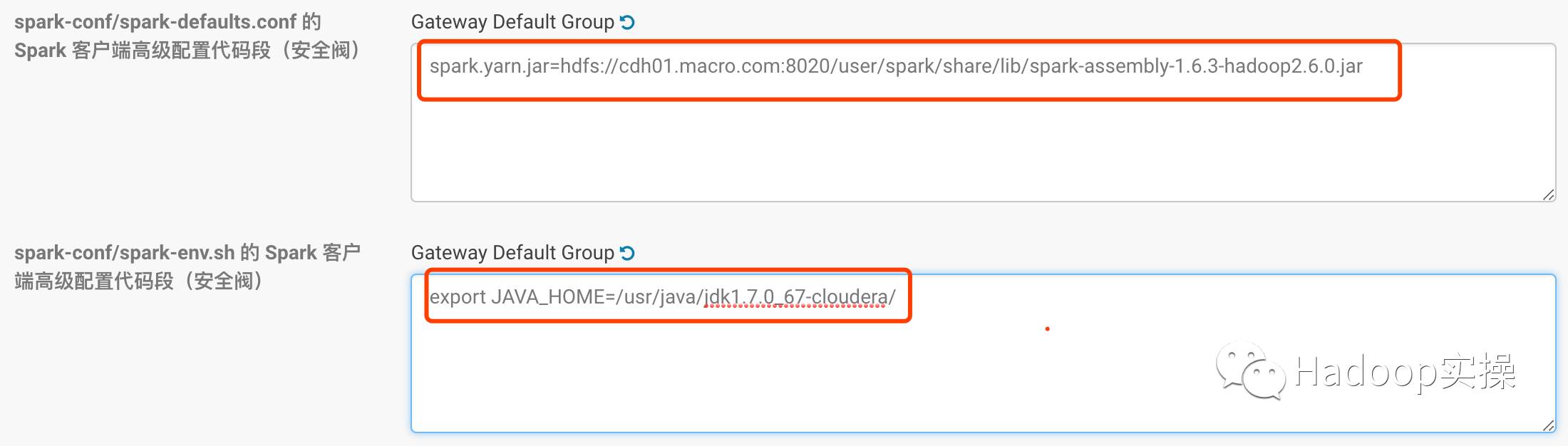
保存配置并重啟Spark服務。
7.修改/etc/spark/conf/ classpath.txt文件在末尾增加如下內容
/opt/cloudera/parcels/CDH-5.13.0-1.cdh6.13.0.p0.29/jars/spark-lineage_2.10-1.6.0-cdh6.13.0.jar

由于CDH5.11以后版本,Navigator2.10增加了Spark的血緣分析,所以這里需要添加spark-lineage_2.10-1.6.0-cdh6.13.0.jar包,否則連接Spark會報錯找不到com.cloudera.spark.lineage.ClouderaNavigatorListener類。
3.部署Spark ThriftServer啟動和停止腳本
1.拷貝Spark ThriftServer啟動和停止腳本
將 spark-1.6.3-bin-hadoop2.6/sbin/目錄下的 start-thriftserver.sh 和 stop-thriftserver.sh 腳本拷貝到/opt/cloudera/parcels/CDH/lib/spark/sbin目錄下,并設置執行權限。
[root@cdh02 sbin]# scp start-thriftserver.sh stop-thriftserver.sh /opt/cloudera/parcels/CDH/lib/spark/sbin/
[root@cdh02 sbin]# chmod +x /opt/cloudera/parcels/CDH/lib/spark/sbin/*thriftserver.sh
[root@cdh02 sbin]# ll /opt/cloudera/parcels/CDH/lib/spark/sbin/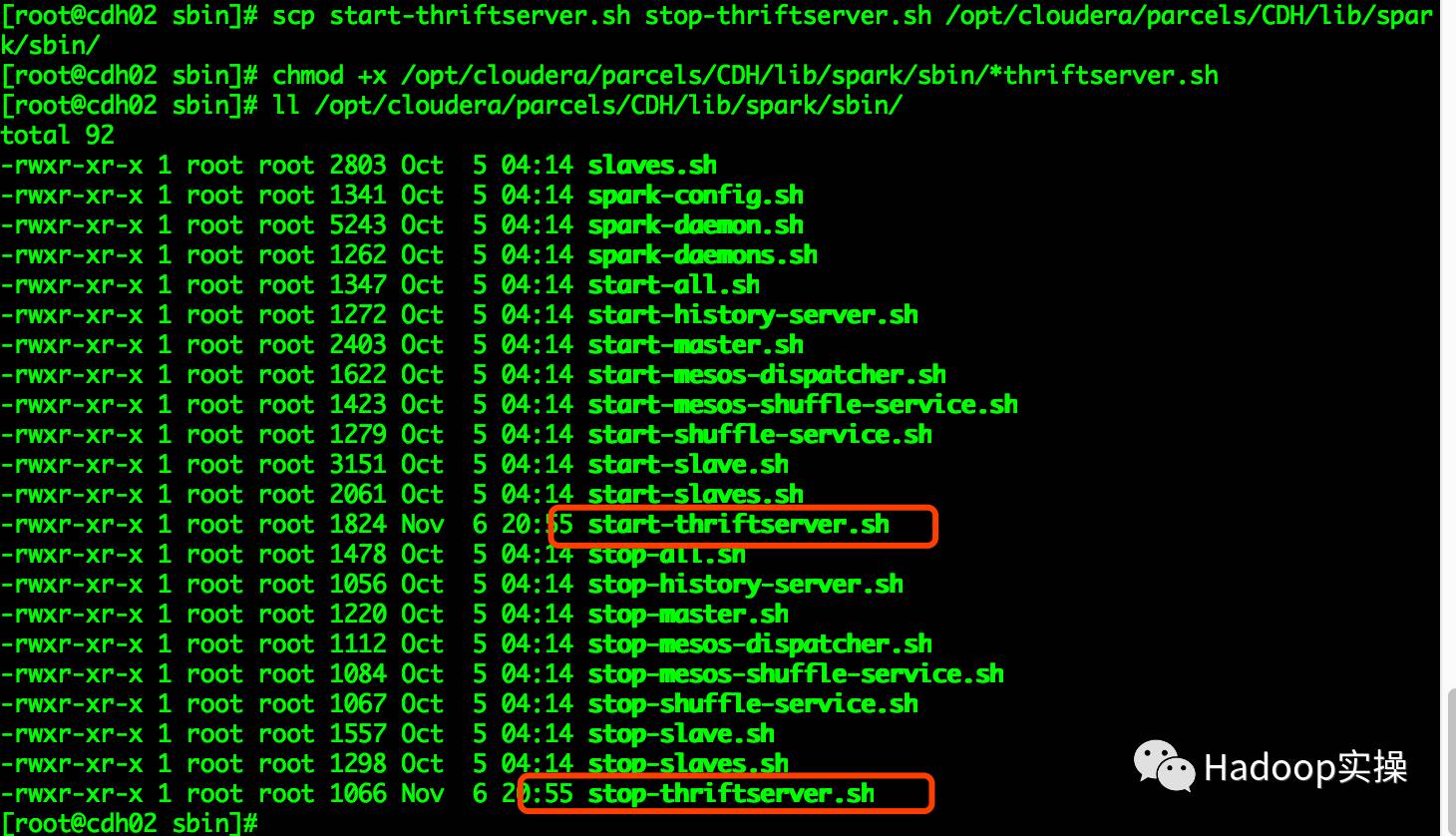
2.修改 load-spark-env.sh 腳本,這個腳本是啟動 spark 相關服務時加載環境變量信息的
[root@ip-172-31-5-190 sbin]# cd /opt/cloudera/parcels/CDH/lib/spark/bin
[root@ip-172-31-5-190 bin]# pwd
/opt/cloudera/parcels/CDH/lib/spark/bin
[root@ip-172-31-5-190 bin]# 將注釋掉exec "$SPARK_HOME/bin/$SCRIPT""$@",因為在start-thriftserver.sh腳本中會執行這個命令
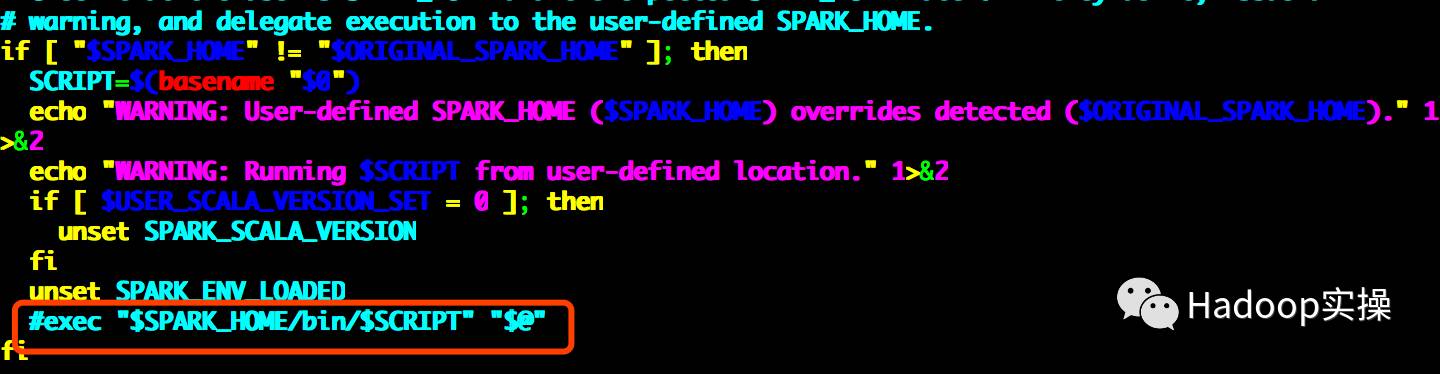
4.啟動與停止Spark ThriftServer
1.啟動Spark ThriftServer服務
[root@ip-172-31-5-190 sbin]# ./start-thriftserver.sh

檢查端口是否監聽
[root@ip-172-31-5-190 sbin]# netstat -an |grep 10000

注意:為了防止跟HiveServer2的10000端口沖突,可以自己修改Spark ThriftServer的啟動端口。
通過Yarn查看
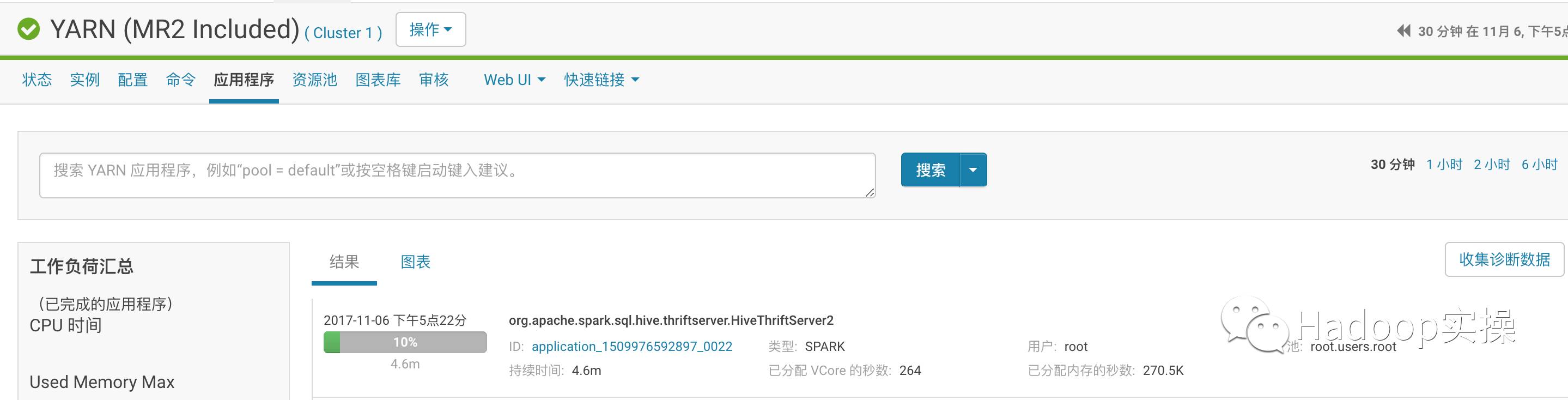
2.停止服務
[root@ip-172-31-5-190 sbin]# ./stop-thriftserver.sh

檢查端口是否已停止

5.測試Spark Thrift
1.使用beeline通過JDBC連接Spark,可以發現連接的是Spark SQL
[root@ip-172-31-5-190 ~]# beeline
beeline> !connect jdbc:hive2://ip-172-31-5-190:10000
Enter username for jdbc:hive2://ip-172-31-5-190:10000: hive
Enter password for jdbc:hive2://ip-172-31-5-190:10000: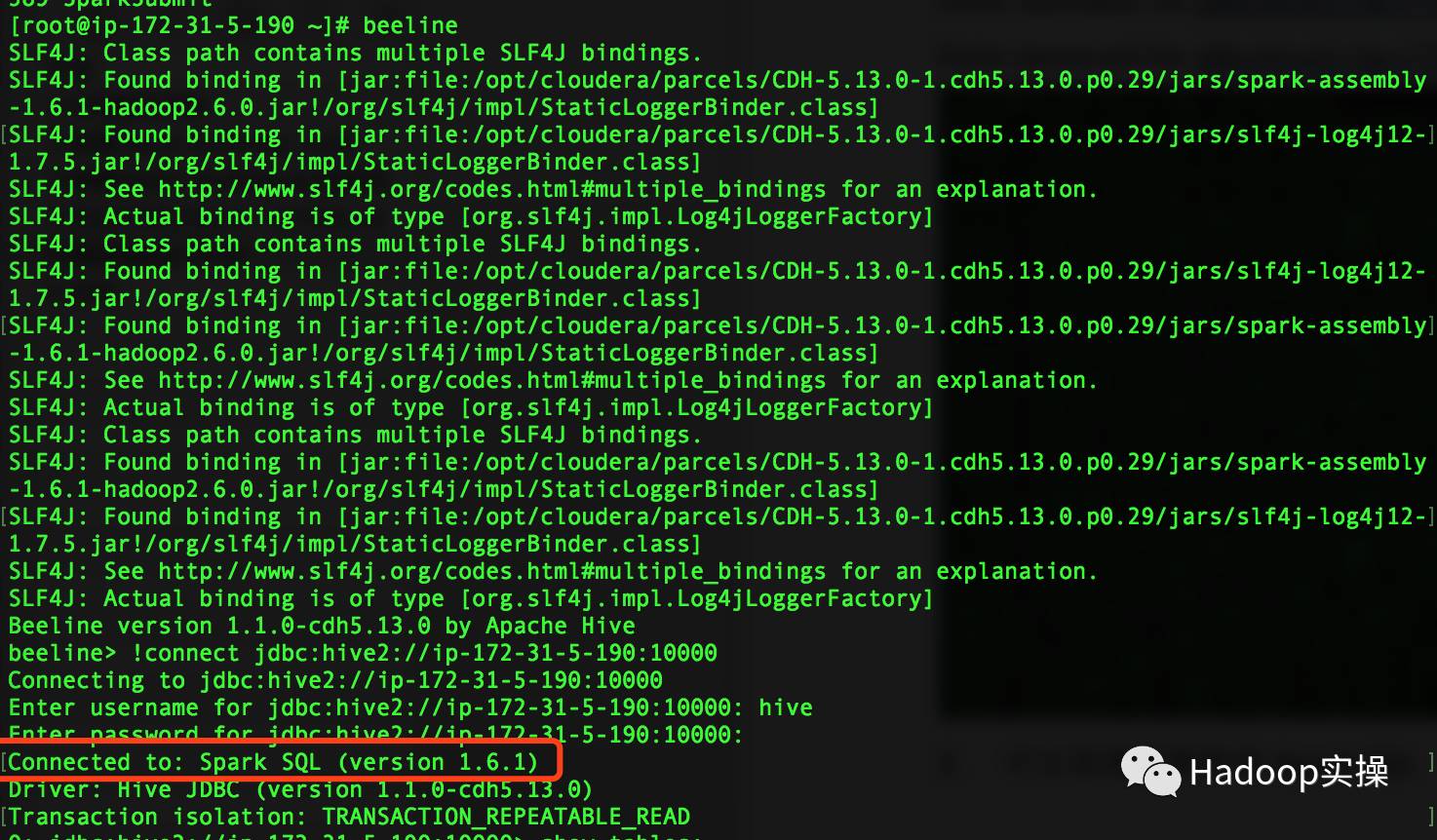
2.運行SQL測試
0: jdbc:hive2://ip-172-31-5-190:10000> show tables;
0: jdbc:hive2://ip-172-31-5-190:10000> select count(*) from test_table;
0: jdbc:hive2://ip-172-31-5-190:10000> select * from test;
0: jdbc:hive2://ip-172-31-5-190:10000> select * from test_table;
0: jdbc:hive2://ip-172-31-5-190:10000> select count(test_table.s2) from test_table join test on test_table.s1=test.s1;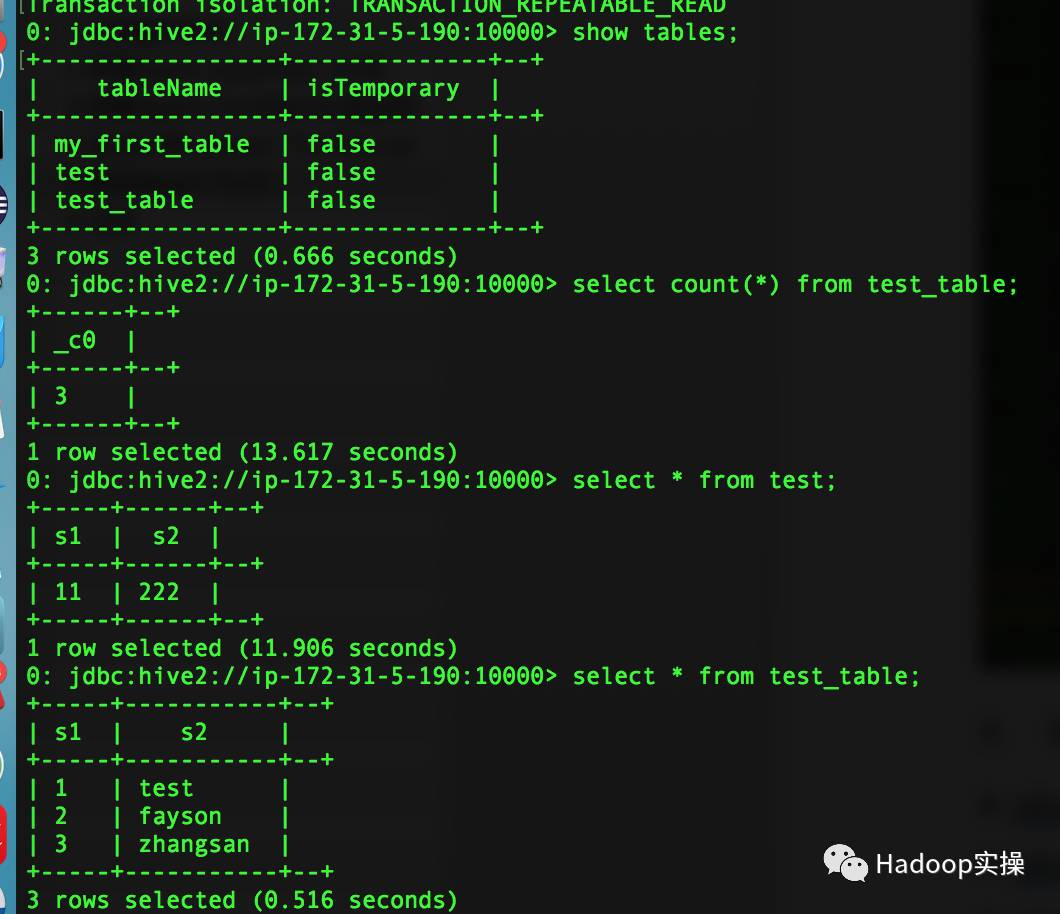

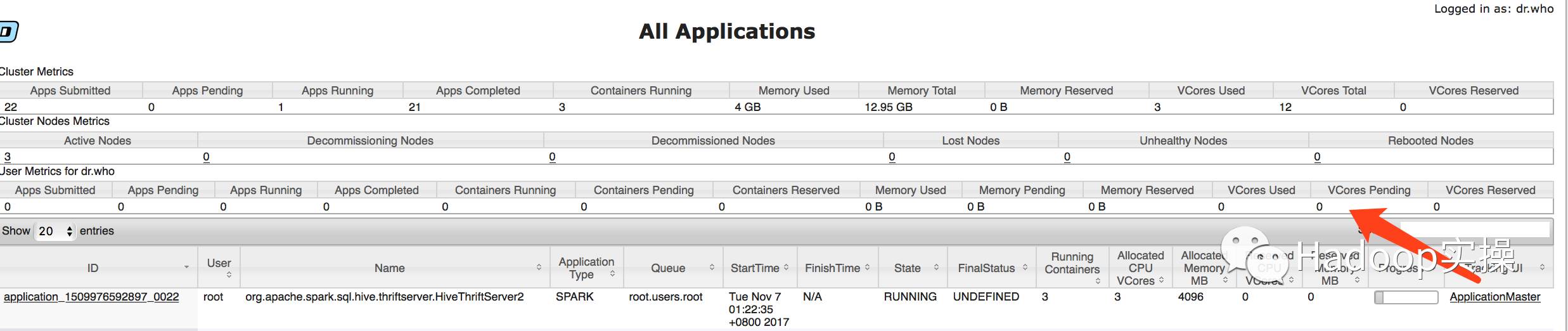
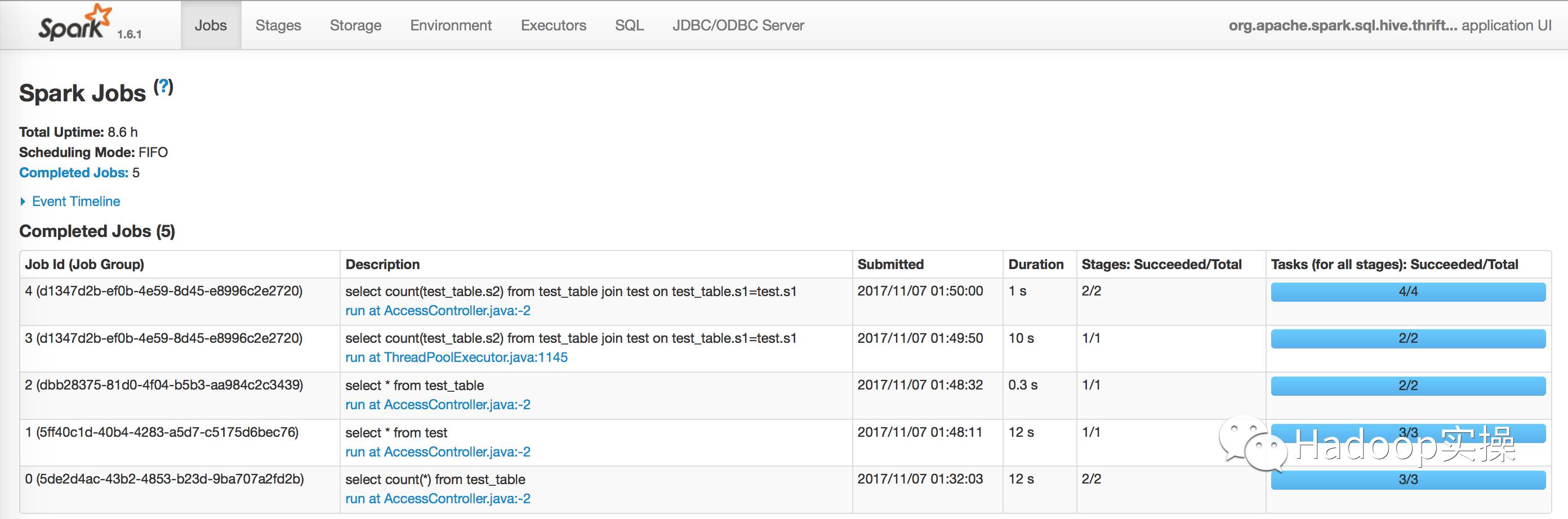
3.在Yarn的8088中查看Spark任務,可以發現都是通過Spark執行的。
以上是“怎么在CDH中啟用Spark Thrift”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





