溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎么深入解析kubernetes資源管理,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
資源,無論是計算資源、存儲資源、網絡資源,對于容器管理調度平臺來說都是需要關注的一個核心問題。
在 kubernetes 中,任何可以被申請、分配,最終被使用的對象,都是 kubernetes 中的資源,比如 CPU、內存。
而且針對每一種被 kubernetes 所管理的資源,都會被賦予一個【資源類型名】,這些名字都是符合 RFC 1123 規則的,比如 CPU,它對應的資源名全稱為 kubernetes.io/cpu(在展示時一般直接簡寫為 cpu);GPU 資源對應的資源名為 alpha.kubernetes.io/nvidia-gpu。
除了名字以外,針對每一種資源還會對應有且僅有一種【基本單位】。這個基本單位一般是在 kubernetes 組件內部統一用來表示這種資源的數量的,比如 memory 的基本單位就是字節。
但是為了方便開發者使用,在開發者通過 yaml 文件或者 kubectl 同 kubernetes 進行交互時仍可以使用多種可讀性更好的資源單位,比如內存的 Gi。而當這些信息進入 kubernetes 內部后,還是會被顯式的轉換為最基本單位。
所有的資源類型,又可以被劃分為兩大類:可壓縮(compressible)和不可壓縮(incompressible)的。其評判標準就在于: 如果系統限制或者縮小容器對可壓縮資源的使用的話,只會影響服務對外的服務性能,比如 CPU 就是一種非常典型的可壓縮資源。
對于不可壓縮資源來說,資源的緊缺是有可能導致服務對外不可用的,比如內存就是一種非常典型的不可壓縮資源。
目前 kubernetes 默認帶有兩類基本資源
? CPU
? memory
其中 CPU,不管底層的機器是通過何種方式提供的(物理機 or 虛擬機),一個單位的 CPU 資源都會被標準化為一個標準的 "Kubernetes Compute Unit" ,大致和 x86 處理器的一個單個超線程核心是相同的。
CPU 資源的基本單位是 millicores,因為 CPU 資源其實準確來講,指的是 CPU 時間。所以它的基本單位為 millicores,1 個核等于 1000 millicores。也代表了 kubernetes 可以將單位 CPU 時間細分為 1000 份,分配給某個容器。
memory 資源的基本單位比較好理解,就是字節。
另外,kubernetes 針對用戶的自定制需求,還為用戶提供了 device plugin 機制,讓用戶可以將資源類型進一步擴充,比如現在比較常用的 nvidia gpu 資源。這個特性可以使用戶能夠在 kubernetes 中管理自己業務中特有的資源,并且無需修改 kubernetes 自身源碼。
而且 kubernetes 自身后續還會進一步支持更多非常通用的資源類型,比如網絡帶寬、存儲空間、存儲 iops 等等。
所以如上,我們就回答了 kubernetes 是如何定義資源的問題。
了解了 kubernetes 是如何對資源進行定義的,我們再來看
kubernetes 所管理的集群中的每一臺計算節點都包含一定的資源,kubernetes 是如何獲知這臺計算節點有多少資源的呢?這些資源中又有多少可以被用戶容器所使用呢?
我們在使用 kubernetes 時會發現:每一個 Node 對象的信息中,有關資源的描述部分如下述所示 (通過 kubectl get node xxx -o yaml 命令可以得到)
allocatable: cpu: "40" memory: 263927444Ki pods: "110" capacity: cpu: "40" memory: 264029844Ki pods: "110"
其中 【capacity】 就是這臺 Node 的【資源真實量】,比如這臺機器是 8核 32G 內存,那么在 capacity 這一欄中就會顯示 CPU 資源有 8 核,內存資源有 32G(內存可能是通過 Ki 單位展示的)。
而 【allocatable】 指的則是這臺機器【可以被容器所使用的資源量】。在任何情況下,allocatable 是一定小于等于 capacity 的。
比如剛剛提到的 8 核機器的,它的 CPU capacity 是 8 核,但是它的 cpu allocatable 量可以被調整為 6 核,也就是說調度到這臺機器上面的容器一共最多可以使用 6 核 CPU,另外 2 核 CPU 可以被機器用來給其他非容器進程使用。
首先看 【capacity】 ,由于 capacity 反映的是這臺機器的資源真實數量,所以確認這個信息的任務理所應當交給運行在每臺機器上面的 kubelet 上。
kubelet 目前把 cadvisor 的大量代碼直接作為 vendor 引入。其實就相當于在 kubelet 內部啟動了一個小的 cadvisor。在 kubelet 啟動后,這個內部的 cadvisor 子模塊也會相應啟動,并且獲取這臺機器上面的各種信息。其中就包括了有關這臺機器的資源信息,而這個信息也自然作為這臺機器的真實資源信息,通過 kubelet 再上報給 apiserver。
如果要介紹 allocatable 信息如何確認,首先必須介紹 Node Allocatable Resource 特性 [6]。 Node Allocatable Resource 特性是由 kubernetes 1.6 版本引進的一個特性。主要解決的問題就是:為每臺計算節點的【非容器進程】預留資源。
在 kubernetes 集群中的每一個節點上,除了用戶容器還會運行很多其他的重要組件,他們并不是以容器的方式來運行的,這些組件的類型主要分為兩個大類:
kubernetes daemon:kubernetes 相關的 daemon 程序,比如 kubelet,dockerd 等等。 system daemon:和 kubernetes 不相關的其他系統級 daemon 程序,比如 sshd 等等。
這兩種進程對于整個物理機穩定的重要性是毋庸置疑的。所以針對這兩種進程,kubernetes 分別提供了 Kube-Reserved 和 System-Reserved 特性,可以分別為這兩組進程設定一個預留的計算資源量,比如預留 2 核 4G 的計算資源給系統進程用。
我們應該都有了解,kubernetes 底層是通過 cgroup 特性來實現資源的隔離與限制的,而這種資源的預留也是通過 cgroup 技術來實現的。
在默認情況下,針對每一種基本資源(CPU、memory),kubernetes 首先會創建一個根 cgroup 組,作為所有容器 cgroup 的根,名字叫做 kubepods。這個 cgroup 就是用來限制這臺計算節點上所有 pod 所使用的資源的。默認情況下這個 kubepods cgroup 組所獲取的資源就等同于該計算節點的全部資源。
但是,當開啟 Kube-Reserved 和 System-Reserved 特性時,kubernetes 則會為 kubepods cgroup 再創建兩個同級的兄弟 cgroup,分別叫做 kube-reserved 和 system-reserved,分別用來為 kubernetes daemon、system daemon 預留一定的資源并且與 kubepods cgroup 共同分配這個機器的資源。所以 kubepods 能夠被分配到的資源勢必就會小于機器的資源真實量了,這樣從而就達到了為 kubernetes daemon,system daemon 預留資源的效果。
所以如果開啟了 Kube-Reserved 和 System-Reserved 的特性的話,在計算 Node Allocatable 資源數量時必須把這兩個 cgroup 占用的資源先減掉。
所以,假設當前機器 CPU 資源的 Capacity 是 32 核,然后我們分別設置 Kube-Reserved 為 2 核,System-Reserved 為 1 核,那么這臺機器真正能夠被容器所使用的 CPU 資源只有 29 核。
但是在計算 memory 資源的 allocatable 數量時,除了 Kube-Reserved,System-Reserved 之外,還要考慮另外一個因素。那就是 Eviction Threshold。
Eviction Threshold 對應的是 kubernetes 的 eviction policy 特性。該特性也是 kubernetes 引入的用于保護物理節點穩定性的重要特性。當機器上面的【內存】以及【磁盤資源】這兩種不可壓縮資源嚴重不足時,很有可能導致物理機自身進入一種不穩定的狀態,這個很顯然是無法接受的。
所以 kubernetes 官方引入了 eviction policy 特性,該特性允許用戶為每臺機器針對【內存】、【磁盤】這兩種不可壓縮資源分別指定一個 eviction hard threshold, 即資源量的閾值。
比如我們可以設定內存的 eviction hard threshold 為 100M,那么當這臺機器的內存可用資源不足 100M 時,kubelet 就會根據這臺機器上面所有 pod 的 QoS 級別(Qos 級別下面會介紹),以及他們的內存使用情況,進行一個綜合排名,把排名最靠前的 pod 進行遷移,從而釋放出足夠的內存資源。
所以針對內存資源,它的 allocatable 應該是 [capacity] - [kube-reserved] - [system-reserved] - [hard-eviction]
所以,如果仔細觀察你會發現:如果你的集群中沒有開啟 kube-reserved,system-reserved 特性的話,通過 kubectl get node -o yaml 會發現這臺機器的 CPU Capacity 是等于 CPU Allocatable 的,但是 Memory Capacity 卻始終大于 Memory Allocatable。主要是因為 eviction 機制,在默認情況下,會設定一個 100M 的 memory eviction hard threshold,默認情況下,memory capacity 和 memory allocatable 之間相差的就是這 100M。
通過上面我們了解了 kubernetes 如何定義并且確認在當前集群中有多少可以被利用起來的資源后,下面就來看一下 kubernetes 到底如何將這些資源分配給每一個 pod 的。
在介紹如何把資源分配給每一個 pod 之前,我們首先要看一下 pod 是如何申請資源的。這個對于大多數已經使用過 kubernetes 的童鞋來講,并不是很陌生。
kubernetes 中 pod 對資源的申請是以容器為最小單位進行的,針對每個容器,它都可以通過如下兩個信息指定它所希望的資源量:
? request
? limit
比如 :
resources: requests: cpu: 2.5 memory: "40Mi" limits: cpu: 4.0 memory: "99Mi"
那么 request,limit 分別又代表了什么含義呢?
? request:
request 指的是針對這種資源,這個容器希望能夠保證能夠獲取到的最少的量。
但是在實際情況下,CPU request 是可以通過 cpu.shares 特性能夠實現的。
但是內存資源,由于它是不可壓縮的,所以在某種場景中,是有可能因為其他 memory limit 設置比 request 高的容器對內存先進行了大量使用導致其他 pod 連 request 的內存量都有可能無法得到滿足。
? limit:
limit 對于 CPU,還有內存,指的都是容器對這個資源使用的上限。
但是這兩種資源在針對容器使用量超過 limit 所表現出的行為也是不同的。
對 CPU 來說,容器使用 CPU 過多,內核調度器就會切換,使其使用的量不會超過 limit。 對內存來說,容器使用內存超過 limit,這個容器就會被 OOM kill 掉,從而發生容器的重啟。 在容器沒有指定 request 的時候,request 的值和 limit 默認相等。
而如果容器沒有指定 limit 的時候,request 和 limit 會被設置成的值則根據不同的資源有不同的策略。
kubernetes 支持用戶容器通過 request、limit 兩個字段指定自己的申請資源信息。那么根據容器指定資源的不同情況,Pod 也被劃分為 3 種不同的 QoS 級別。分別為:
? Guaranteed
? Burstable
? BestEffort
不同的 QoS 級別會在很多方面發揮作用,比如調度,eviction。
Guaranteed 級別的 pod 主要需要滿足兩點要求:
? pod 中的每一個 container 都必須包含內存資源的 limit、request 信息,并且這兩個值必須相等
? pod 中的每一個 container 都必須包含 CPU 資源的 limit、request 信息,并且這兩個信息的值必須相等
Burstable 級別的 pod 則需要滿足兩點要求:
? 資源申請信息不滿足 Guaranteed 級別的要求 ? pod 中至少有一個 container 指定了 cpu 或者 memory 的 request 信息
BestEffort 級別的 pod 需要滿足:
? pod 中任何一個 container 都不能指定 cpu 或者 memory 的 request,limit 信息
所以通過上面的描述也可以看出來,
? Guaranteed level 的 Pod 是優先級最高的,系統管理員一般對這類 Pod 的資源占用量比較明確。
? Burstable level 的 Pod 優先級其次,管理員一般知道這個 Pod 的資源需求的最小量,但是當機器資源充足的時候,還是希望他們能夠使用更多的資源,所以一般 limit > request。
? BestEffort level 的 Pod 優先級最低,一般不需要對這個 Pod 指定資源量。所以無論當前資源使用如何,這個 Pod 一定會被調度上去,并且它使用資源的邏輯也是見縫插針。當機器資源充足的時候,它可以充分使用,但是當機器資源被 Guaranteed、Burstable 的 Pod 所搶占的時候,它的資源也會被剝奪,被無限壓縮。
我們在上面兩個小節介紹了:
? pod 申請資源的方式
? pod 申請資源的方式對應的是什么 QoS 級別
最終,kubelet 就是基于 【pod 申請的資源】 + 【pod 的 QoS 級別】來最終為這個 pod 分配資源的。
而分配資源的根本方法就是基于 cgroup 的機制。
kubernetes 在拿到一個 pod 的資源申請信息后,針對每一種資源,他都會做如下幾件事情:
?對 pod 中的每一個容器,都創建一個 container level cgroup(注:這一步真實情況是 kubernetes 向 docker daemon 發送命令完成的)。
? 然后為這個 pod 創建一個 pod level cgroup ,它會成為這個 pod 下面包含的所有 container level cgroup 的父 cgroup。
? 最終,這個 pod level cgroup 最終會根據這個 pod 的 QoS 級別,可能被劃分到某一個 QoS level cgroup 中,成為這個 QoS level cgroup 的子 cgroup。
? 整個 QoS level cgroup 還是所有容器的根 cgroup - kubepods 的子 cgroup。
所以這個嵌套關系通過下述圖片可以比較清晰的展示出來。
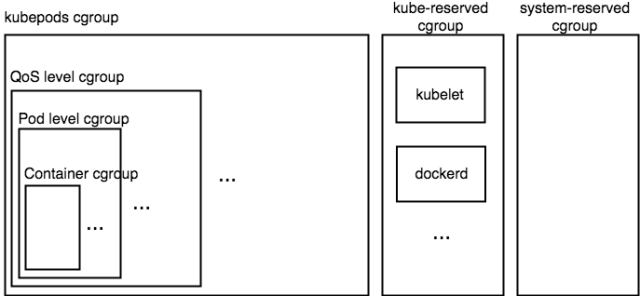
圖中代表了一個 kubernetess 計算節點的 cgroup 的層次結構(對于 cpu、memory 來說 cgroup 層次結構是完全一致的)。可見,所有 pod 的 cgroup 配置都位于 kubepods 這個大的 cgroup 下,而之前介紹的 kube-reserved cgroup 和 system-reserved cgroup 和 kubepods cgroup 位于一級,他們 3 個會共享機器的計算資源。
我們首先看如何確定這個 container 對應的 container level cgroup 和它所在的 pod level cgroup。
首先,每一個 container 的 cgroup 的配置則是根據這個 container 對這種資源的 request、limit 信息來配置的。
我們分別看一下,針對 cpu、memory 兩種資源,kubernetes 是如何為每一個容器創建 container 級別的 cgroup 的。
CPU 資源
首先是 CPU 資源,我們先看一下 CPU request。
CPU request 是通過 cgroup 中 CPU 子系統中的 cpu.shares 配置來實現的。
當你指定了某個容器的 CPU request 值為 x millicores 時,kubernetes 會為這個 container 所在的 cgroup 的 cpu.shares 的值指定為 x * 1024 / 1000。即:
cpu.shares = (cpu in millicores * 1024) / 1000
舉個栗子,當你的 container 的 CPU request 的值為 1 時,它相當于 1000 millicores,所以此時這個 container 所在的 cgroup 組的 cpu.shares 的值為 1024。
這樣做希望達到的最終效果就是:
即便在極端情況下,即所有在這個物理機上面的 pod 都是 CPU 繁忙型的作業的時候(分配多少 CPU 就會使用多少 CPU),仍舊能夠保證這個 container 的能夠被分配到 1 個核的 CPU 計算量。
其實就是保證這個 container 的對 CPU 資源的最低需求。
所以可見 cpu.request 一般代表的是這個 container 的最低 CPU 資源需求。但是其實僅僅通過指定 cpu.shares 還是無法完全達到上面的效果的,還需要對 QoS level 的 cgroup 進行同步的修改。至于具體實現原理我們在后面會詳細介紹。
而針對 cpu limit,kubernetes 是通過 CPU cgroup 控制模塊中的 cpu.cfs_period_us,cpu.cfs_quota_us 兩個配置來實現的。kubernetes 會為這個 container cgroup 配置兩條信息:
cpu.cfs_period_us = 100000 (i.e. 100ms) cpu.cfs_quota_us = quota = (cpu in millicores * 100000) / 1000
在 cgroup 的 CPU 子系統中,可以通過這兩個配置,嚴格控制這個 cgroup 中的進程對 CPU 的使用量,保證使用的 CPU 資源不會超過 cfs_quota_us/cfs_period_us,也正好就是我們一開始申請的 limit 值。
可見通過 cgroup 的這個特性,就實現了限制某個容器的 CPU 最大使用量的效果。
Memory
針對內存資源,其實 memory request 信息并不會在 container level cgroup 中有體現。kubernetes 最終只會根據 memory limit 的值來配置 cgroup 的。
在這里 kubernetes 使用的 memory cgroup 子系統中的 memory.limit_in_bytes 配置來實現的。配置方式如下:
memory.limit_in_bytes = memory limit bytes
memory 子系統中的 limit_in_bytes 配置,可以限制一個 cgroup 中的所有進程可以申請使用的內存的最大量,如果超過這個值,那么根據 kubernetes 的默認配置,這個容器會被 OOM killed,容器實例就會發生重啟。
可見如果是這種實現方式的話,其實 kubernetes 并不能保證 pod 能夠真的申請到它指定的 memory.request 那么多的內存量,這也可能是讓很多使用 kubernetes 的童鞋比較困惑的地方。因為 kubernetes 在對 pod 進行調度的時候,只是保證一臺機器上面的 pod 的 memory.request 之和小于等于 node allocatable memory 的值。所以如果有一個 pod 的 memory.limit 設置的比較高,甚至沒有設置,就可能會出現一種情況,就是這個 pod 使用了大量的內存(大于它的 request,但是小于它的 limit),此時鑒于內存資源是不可壓縮的,其他的 pod 可能就沒有足夠的內存余量供其進行申請了。當然,這個問題也可以通過一個特性在一定程度進行緩解,這個會在下面介紹。
當然讀者可能會有一個問題,如果 pod 沒有指定 request 或者 limit 會怎樣配置呢?
如果沒有指定 limit 的話,那么 cfs_quota_us 將會被設置為 -1,即沒有限制。而如果 limit 和 request 都沒有指定的話,cpu.shares 將會被指定為 2,這個是 cpu.shares 允許指定的最小數值了。可見針對這種 pod,kubernetes 只會給他分配最少的 CPU 資源。
而對于內存來說,如果沒有 limit 的指定的話,memory.limit_in_bytes 將會被指定為一個非常大的值,一般是 2^64 ,可見含義就是不對內存做出限制。
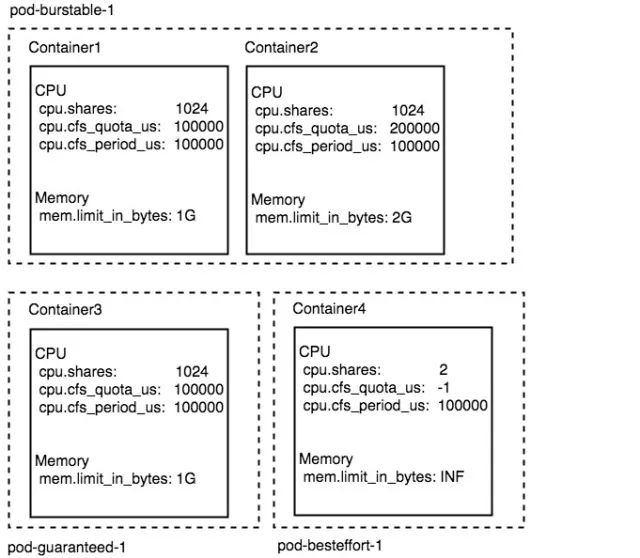
針對上面對 container level cgroup 的介紹,我們舉個具體的栗子,假設一個 pod 名字叫做 pod-burstable-1 是由兩個業務容器構成的 container1 container2,這兩個 container 的資源配置分別如下:
- image: image1 name: container1 resources: limits: cpu: 1 memory: 1Gi requests: cpu: 1 memory: 1Gi - image: image2 name: container2 resources: limits: cpu: 2 memory: 2Gi requests: cpu: 1 memory: 1Gi
所以可見這個 pod 所有容器的 request,limit 都已經被指定,但是 request 和 limit 并不完全相等,所以這個 pod 的 QoS 級別為 Burstable。
另外還有一個 pod 名字叫做 pod-guaranteed-1,它由一個 container 構成,資源配置如下:
- image: image3 name: container3 resources: limits: cpu: 1 memory: 1Gi requests: cpu: 1 memory: 1Gi
通過這個配置可見,它是一個 Guaranteed 級別的 Pod。
另外還有一個 pod 叫做 pod-besteffort-1 它有一個 container 構成,資源配置信息完全為空,那么這個 pod 就是 besteffort 級別的 pod。
所以通過上述描述的 cgroup 配置方式,這 3 個 pod 會創建 4 個 container cgroup 如下圖所示:
Pod level cgroup
創建完 container level 的 cgroup 之后,kubernetes 就會為同屬于某個 pod 的 containers 創建一個 pod level cgroup。作為它們的父 cgroup。至于為何要引入 pod level cgroup,主要是基于幾點原因:
? 方便對 pod 內的容器資源進行統一的限制
? 方便對 pod 使用的資源進行統一統計
所以對于我們上面舉的栗子,一個 pod 名稱為 pod-burstable-1,它包含兩個 container:container1、container2,那么這個 pod cgroup 的目錄結構如下:
pod-burstable-1 | +- container1 | +- container2
注:真實情況下 pod cgroup 的名稱是 pod,這里為了表示清楚,用 pod name 代替
那么為了保證這個 pod 內部的 container 能夠獲取到期望數量的資源,pod level cgroup 也需要進行相應的 cgroup 配置。而配置的方式也基本滿足一個原則:
pod level cgroup 的資源配置應該等于屬于它的 container 的資源需求之和。
但是,這個規則在不同的 QoS 級別的 pod 下也有些細節上的區別。所以針對 Guaranteed 和 Burstable 級別的 Pod,每一個 Pod 的 cgroup 配置都可以由下述 3 個公式來完成
cpu.shares=sum(pod.spec.containers.resources.requests\[cpu\]) cpu.cfs_quota_us=sum(pod.spec.containers.resources.limits\[cpu\] memory.limit_in_bytes=sum(pod.spec.containers.resources.limits\[memory\])
從公式中可見,pod level cgroup 的 cpu.shares、 cpu.cfs_quota_us、memory.limit_in_bytes 最終都等于屬于這個 pod 的 container 的這 3 值的和。
當然在 Burstable,Besteffort 的場景下,有可能 container 并沒有指定 cpu.limit、memory.limit,此時 cpu.cfs_quota_us、memory.limit_in_bytes 將不會采用這個公式,因為此時相當于不會對 pod 的 cpu,memory 的使用量做最大值的限制,所以此時這兩個配置也會參照上一節中說道的“如果 container 如果沒有設置 request 和 limit 的話”處理的方式一樣。
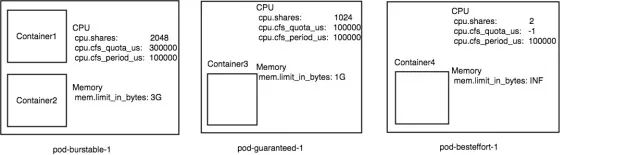
所以針對我們在上面的舉的例子 pod-burstable-1,就是一個非常典型的 burstable pod,根據 burstable pod 的資源配置公式,kubernetes 會為這個 pod 創建一個 pod 級別的 cgroup。另外 pod-guaranteed-1 也會創建一個 cgroup,這兩個 pod level cgroup 的配置如下圖所示
Besteffort pod cgroup
上面我們講到的 pod cgroup 配置規律是不能應用于 besteffort pod 的。
因為這個 QoS 級別的 pod 就像名字描述的那樣,kubernetes 只能盡可能的保證你的資源使用,在資源被極端搶占的情況,這種 pod 的資源使用量應該被一定程度的限制,無論是 cpu,還是內存(當然這兩種限制的機制完全不同)。
所以針對 besteffort 級別的 pod,由于這里面的所有容器都不包含 request,limit 信息,所以它的配置非常統一。
所以針對 cpu,整個 pod 的 cgroup 配置就只有下面:
cpu.shares = 2
可見這個配置的目標就是能夠達到,它在機器 cpu 資源充足時能使用整個機器的 cpu,因為沒有指定 limit。但是在 cpu 資源被極端搶占時,它能夠被分配的 cpu 資源很有限,相當于 2 millicores。
針對內存,沒有任何特殊配置,只是采用默認,雖然在這種情況下,這個 pod 可能會使用整個機器那么多的內存,但是 kubernetes eviction 機制會保證,內存不足時,優先刪除 Besteffort 級別的 pod 騰出足夠的內存資源。
QoS level cgroup
前面也提過,在 kubelet 啟動后,會在整個 cgroup 系統的根目錄下面創建一個名字叫做 kubepods 子 cgroup,這個 cgroup 下面會存放所有這個節點上面的 pod 的 cgroup。從而達到了限制這臺機器上所有 Pod 的資源的目的。
在 kubepods cgroup 下面,kubernetes 會進一步再分別創建兩個 QoS level cgroup,名字分別叫做:
? burstable
? besteffort
通過名字也可以推斷出,這兩個 QoS level 的 cgroup 肯定是作為各自 QoS 級別的所有 Pod 的父 cgroup 來存在的。
那么問題就來了:
? guaranteed 級別的 pod 的 pod cgroup 放在哪里了呢?
? 這兩個 QoS level cgroup 存在的目的是什么?
首先第一個問題,所有 guaranteed 級別的 pod 的 cgroup 其實直接位于 kubepods 這個 cgroup 之下,和 burstable、besteffort QoS level cgroup 同級。主要原因在于 guaranteed 級別的 pod 有明確的資源申請量(request)和資源限制量(limit),所以并不需要一個統一的 QoS level 的 cgroup 進行管理或限制。
針對 burstable 和 besteffort 這兩種類型的 pod,在默認情況下,kubernetes 則是希望能盡可能地提升資源利用率,所以并不會對這兩種 QoS 的 pod 的資源使用做限制。
但是在很多場景下,系統管理員還是希望能夠盡可能保證 guaranteed level pod 這種高 QoS 級別的 pod 的資源,尤其是不可壓縮資源(如內存),不要被低 QoS 級別的 pod 提前使用,導致高 QoS 級別的 pod 連它 request 的資源量的資源都無法得到滿足。
所以,kubernetes 才引入了 QoS level cgroup,主要目的就是限制低 QoS 級別的 pod 對不可壓縮資源(如內存)的使用量,為高 QoS 級別的 pod 做資源上的預留。三種 QoS 級別的優先級由高到低為 guaranteed > burstable > besteffort。
那么到底如何實現這種資源預留呢?主要是通過 kubelet 的 experimental-qos-reserved 參數來控制,這個參數能夠控制以怎樣的程度限制低 QoS 級別的 pod 的資源使用,從而對高級別的 QoS 的 pod 實現資源上的預留,保證高 QoS 級別的 pod 一定能夠使用到它 request 的資源。
目前只支持對內存這種不可壓縮資源的預留情況進行指定。比如 experimental-qos-reserved=memory=100%,代表我們要 100% 為高 QoS level 的 pod 預留資源。
所以針對這個場景,對于內存資源來說,整個 QoS Level cgroup 的配置規則如下:
burstable/memory.limit_in_bytes =
Node.Allocatable - {(summation of memory requests of `Guaranteed` pods)_(reservePercent / 100)} besteffort/memory.limit_in_bytes =
Node.Allocatable - {(summation of memory requests of all `Guaranteed` and `Burstable` pods)_(reservePercent / 100)}從公式中可見,burstable 的 cgroup 需要為比他等級高的 guaranteed 級別的 pod 的內存資源做預留,所以默認情況下,如果沒有指定這個參數,burstable cgroup 中的 pod 可以把整個機器的內存都占滿,但是如果開啟這個特性,burstable cgroup 的內存限制就需要動態的根據當前有多少 guaranteed 級別 pod 來進行動態調整了。
besteffort 也是類似,但是不一樣的地方在于 besteffort 不僅要為 guaranteed 級別的 pod 進行資源預留,還要為 burstable 級別的 pod 也進行資源的預留。
所以舉個栗子,當前機器的 allocatable 內存資源量為 8G,我們為這臺機器的 kubelet 開啟 experimental-qos-reserved 參數,并且設置為 memory=100%。如果此時創建了一個內存 request 為 1G 的 guaranteed level 的 pod,那么此時這臺機器上面的 burstable QoS level cgroup 的 memory.limit_in_bytes 的值將會被設置為 7G,besteffort QoS level cgroup 的 memory.limit_in_bytes 的值也會被設置為 7G。
而如果此時又創建了一個 burstable level 的 pod,它的內存申請量為 2G,那么此時 besteffort QoS level cgroup 的 memory.limit_in_bytes 的值也會被調整為 5G。
內存雖然搞定了,但是對于 cpu 資源反而帶來一些麻煩。
針對 besteffort 的 QoS,它的 cgroup 的 CPU 配置還是非常簡單:
besteffort/cpu.shares = 2
但是針對 burstable 的 QoS,由于所有的 burstable pod 現在都位于 kubepods 下面的 burstable 這個子組下面,根據 cpu.shares 的背后實現原理,位于不同層級下面的 cgroup,他們看待同樣數量的 cpu.shares 配置可能最終獲得不同的資源量。比如在 Guaranteed 級別的 pod cgroup 里面指定的 cpu.shares=1024,和 burstable 下面的某個 pod cgroup 指定 cpu.shares=1024 可能最終獲取的 cpu 資源并不完全相同。這個是因為 cpu.shares 自身機制導致的。
所以為了能夠解決這個問題,kubernetes 也必須動態調整 burstable cgroup 的 cpu.shares 的配置,如下文檔中描述的那樣:
burstable/cpu.shares = max(sum(Burstable pods cpu requests, 2)
來保證,相同的 cpu.shares 配置,對于 guaranteed 級別的 pod 和 burstable 的 pod 來說是完全一樣的。
至于為什么這樣做我們將在后面進行詳細的解釋。
所以對于我們上面的例子,3 個 pod 分別為 guaranteed,burstable,besteffort 級別的,假設當前機器的 kubelet 開啟了 experimental-qos-reserved 參數并且指定為 memory=100%。假設這 3 pod 運行在一臺 3 核 8G 內存的機器上面,那么此時整個機器的 cgroup 配置將如下:
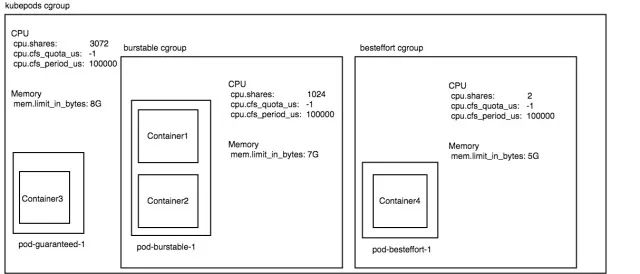
通過這一系列的配置后,我們達到的效果就是:
? 在機器 cpu 資源空閑時,pod-guaranteed-1 這個 pod 最多可以使用 1 核 cpu 的計算力。pod-burstable-1 這個 pod 最多可以使用 3 核的 cpu 計算力,pod-besteffort-1 這個 pod 可以把機器剩余的計算力跑滿。
? 當機器 cpu 資源被搶占的時候,比如 pod-guaranteed-1、pod-burstable-1 這兩種資源都在 100% 的使用 cpu 的時候,pod-guaranteed-1 仍舊可以獲取 1 核的 cpu 計算力,pod-burstable-1 仍舊可以獲取 2 核的計算力。但是 pod-besteffort-1 僅僅能獲取 2 milicores 的 cpu 計算力,是 pod-burstable-1 的千分之一。
? 該機器的 besteffort 級別的 pod,能夠使用的最大內存量為[機器內存 8G] - [sum of request of burstable 2G] - [sum of request of guaranteed 1G] = 5G
? 該機器的 burstable 級別的 pod,能夠使用的最大內存量為 [機器內存 8G] - [sum of request of guaranteed 1G] = 7G
CPU Request 的實現
CPU 資源的 request 量代表這個容器期望獲取的最小資源量。它是通過 cgroup cpu.shares 特性來實現的。但是這個 cpu.shares 真實代表的這個 cgroup 能夠獲取機器 CPU 資源的【比重】,并非【絕對值】。
比如某個 cgroup A 它的 cpu.shares = 1024 并不代表這個 cgroup A 能夠獲取 1 核的計算資源,如果這個 cgroup 所在機器一共有 2 核 CPU,除了這個 cgroup 還有另外 cgroup B 的 cpu.shares 的值為 2048 的話,那么在 CPU 資源被高度搶占的時候,cgroup A 只能夠獲取 2 * (1024/(1024 + 2048)) 即 2/3 的 CPU 核資源。
那么 kubernetes 又是如何實現,無論是什么 QoS 的 pod,只要它的某個容器的 cpu.shares = 1024,那么它就一定能夠獲取 1 核的計算資源的呢?
實現的方式其實就是通過合理的對 QoS level cgroup,Pod level cgroup 進行動態配置來實現的。
我們還可以用上面的栗子繼續描述,假設目前這 3 個 Pod 就位于一個有 3 個 CPU 核的物理機上面。此時這臺機器的 CPU cgroup 的配置會變成下面的樣子
?kubepods cgroup 的 cpu.shares 將會被設置為 3072。
?pod-guaranteed-1 中的 pod cgroup 的 cpu.shares 將會被設置為 1024,pod cgroup 內的 container3 的 container cgroup 的 cpu.shares 將會被設置為 1024。
?pod-burstable-1 所在 burstable QoS level cgroup cpu.shares 將會被設置為 2048
?pod-burstable-1 的 pod cgroup 的 cpu.shares 是 2048
?pod-burstable-1 中的 container1 的 cpu.shares 是 1024
?pod-burstable-1 中的 container2 的 cpu.shares 是 1024
所以此時的層次結構如下圖:
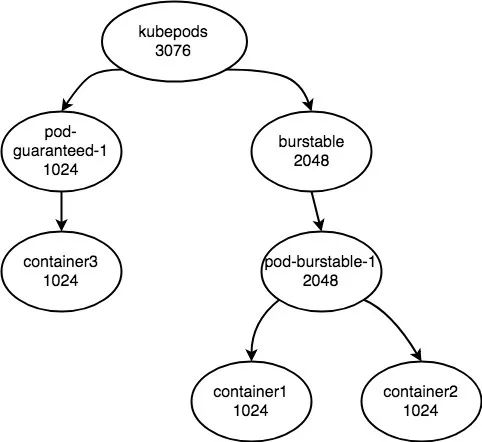
因為 besteffort 的 cpu.shares 的值僅僅為 2,可以忽略。
所以此時在計算 container1、container2、container3 在 CPU 繁忙時的 CPU 資源時,就可以按照下述公式來進行計算:
? container3 = (1024/1024) * (1024/(1024+2048)) * 3 = 1
? container1 = (1024/(1024+1024)) * (2048/2048) * (2048/1024+2048) * 3 = 1
? container2 = (1024/(1024+1024)) * (2048/2048) * (2048/1024+2048) * 3 = 1
可見,kubernetes 是通過巧妙的設置 kubepods cgroup 的 cpu.shares,以及合理的更新 burstable QoS level cgroup 的配置來實現 cpu.shares 就等于容器可以獲取的最小 CPU 資源的效果的。
看完上述內容,你們對怎么深入解析kubernetes資源管理有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





