溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Flume整體架構是怎么樣的”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Flume整體架構是怎么樣的”這篇文章吧。
Flume是cloudera公司開源的一款分布式、可靠地進行大量日志數據采集、聚合和并轉移到存儲中;通過事務機制提供了可靠的消息傳輸支持,自帶負載均衡機制來支撐水平擴展;并且提供了一些默認組件供直接使用。
Flume目前常見的應用場景:日志--->Flume--->實時計算(如Kafka+Storm) 、日志--->Flume--->離線計算(如HDFS、HBase)、日志--->Flume--->ElasticSearch。
Flume主要分為三個組件:Source、Channel、Sink;數據流如下圖所示:
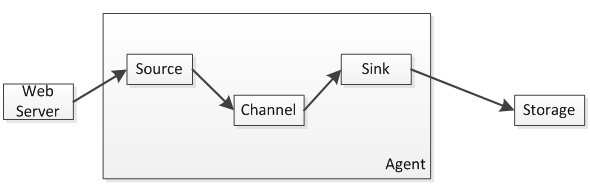
1、Source負責日志流入,比如從文件、網絡、Kafka等數據源流入數據,數據流入的方式有兩種輪訓拉取和事件驅動;
2、Channel負責數據聚合/暫存,比如暫存到內存、本地文件、數據庫、Kafka等,日志數據不會在管道停留很長時間,很快會被Sink消費掉;
3、Sink負責數據轉移到存儲,比如從Channel拿到日志后直接存儲到HDFS、HBase、Kafka、ElasticSearch等,然后再有如Hadoop、Storm、ElasticSearch之類的進行數據分析或查詢。
一個Agent會同時存在這三個組件,Source和Sink都是異步執行的,相互之間不會影響。
假設我們有采集并索引Nginx訪問日志,我們可以按照如下方式部署:
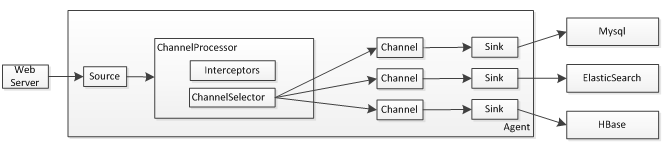
1、Source采集的日志會傳入ChannelProcessor組件,其首先通過Interceptor進行日志過濾,如果接觸過Servlet的話這個概念是類似的,可以參考《Servlet3.1規范翻譯——過濾器 》 ;過濾器可以過濾掉日志,也可以修改日志內容;
2、過濾完成后接下來會交給ChannelSelector進行處理,默認提供了兩種選擇器:復制或多路復用選擇器;復制即把一個日志復制到多個Channel;而多路復用會根據配置的選擇器條件,把符合條件的路由到相應的Channel;在寫多個Channel時可能存在存在失敗的情況,對于失敗的處理有兩種:稍后重試或者忽略。重試一般采用指數級時間進行重試。
我們之前說過Source生產日志給Channel、Sink從Channel消費日志;它倆完全是異步的,因此Sink只需要監聽自己關系的Channel變化即可。
到此我們可以對Source日志進行過濾/修改,把一個消息復制/路由到多個Channel,對于Sink的話也應該存在寫失敗的情況,Flume默認提供了如下策略:

Failover策略是給多個Sink定義優先級,假設其中一個失敗了,則路由到下一個優先級的Sink;Sink只要拋出一次異常就會被認為是失敗了,則從存活Sink中移除,然后指數級時間等待重試,默認是等待1s開始重試,最大等待重試時間是30s。
Flume也提供了負載均衡策略:
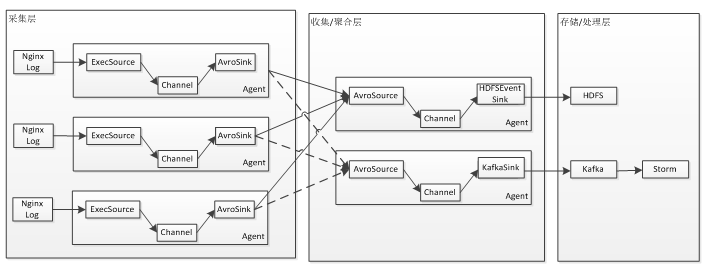
1、首先是日志采集層,該層的Agent和應用部署在同一臺機器上,負責采集如Nginx訪問日志;然后通過RPC將日志流入到收集/聚合層;在這一層應該快速的采集到日志然后流入到收集/聚合層;
2、收集/聚合層進行日志的收集或聚合,并且可以進行容錯處理,如故障轉移或負載均衡,以提升可靠性;另外可以在該層開啟文件Channel,做數據緩沖區;
3、收集/聚合層對數據進行過濾或修改然后進行存儲或處理;比如存儲到HDFS,或者流入Kafka然后通過Storm對數據進行實時處理。
以上是“Flume整體架構是怎么樣的”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





