溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了flume架構是怎么樣的,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
flume介紹
flume是一個分布式、可靠、和高可用的海量日志采集、聚合和傳輸的系統。支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(比如文本、HDFS、Hbase等)的能力 。官方網站:http://flume.apache.org/
flume架構
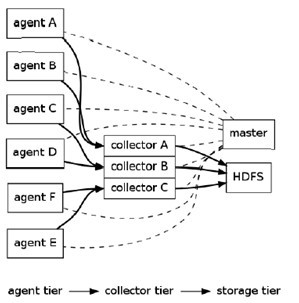
Flume采用了分層架構:分別為agent,collector和storage。用戶可以根據需要添加自己的的agent,collector或者storage。其中,agent和collector均有兩部分組成:source和sink,source是數據來源,sink是數據去向。(大三層和小三層一樣,也可以說flume分為source、channel和sink)
Flume核心概念
大的方面:
Agent使用JVM 運行Flume。每臺機器運行一個agent,但是可以在一個agent中包含多個sources和sinks。Collector將多個agent的數據收集后加載到storage中。
Storage存儲收集的數據。
Client生產數據,運行在一個獨立的線程。
小的方面:
Source從Client收集數據,傳遞給Channel。
Sink從Channel收集數據,運行在一個獨立線程。
Channel連接 sources 和 sinks ,這個有點像一個隊列。
Events是flume的數據基本單位,可以是日志記錄、 avro 對象等。
Flume組件詳解
Source從Client收集數據,傳遞給Channel。
Client端操作消費數據的來源,Flume 支持 Avro,log4j,syslog 和 http post(body為json格式)。可以讓應用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。也可以 寫一個 Source,以 IPC 或 RPC 的方式接入自己的應用,Avro和 Thrift 都可以(分別有 NettyAvroRpcClient 和 ThriftRpcClient 實現了 RpcClient接口),其中 Avro 是默認的 RPC 協議。具體代碼級別的 Client 端數據接入,可以參考官方手冊。
對現有程序改動最小的使用方式是使用是直接讀取程序原來記錄的日志文件,基本可以實現無縫接入,不需要對現有程序進行任何改動。
對于直接讀取文件 Source,有兩種方式:
ExecSource: 以運行 Linux 命令的方式,持續的輸出最新的數據,如tail -F 文件名指令,在這種方式下,取的文件名必須是指定的。 ExecSource 可以實現對日志的實時收集,但是存在Flume不運行或者指令執行出錯時,將無法收集到日志數據,無法保證日志數據的完整性。
SpoolSource: 監測配置的目錄下新增的文件,并將文件中的數據讀取出來。需要注意兩點:拷貝到 spool 目錄下的文件不可以再打開編輯;spool 目錄下不可包含相應的子目錄。
SpoolSource 雖然無法實現實時的收集數據,但是可以使用以分鐘的方式分割文件,趨近于實時。
如果應用無法實現以分鐘切割日志文件的話, 可以兩種收集方式結合使用。 在實際使用的過程中,可以結合 log4j 使用,使用 log4j的時候,將 log4j 的文件分割機制設為1分鐘一次,將文件拷貝到spool的監控目錄。
log4j 有一個 TimeRolling 的插件,可以把 log4j 分割文件到 spool 目錄。基本實現了實時的監控。Flume 在傳完文件之后,將會修改文件的后綴,變為 .COMPLETED(后綴也可以在配置文件中靈活指定)
Channel連接 sources 和 sinks ,這個有點像一個隊列
當前有幾個 channel 可供選擇,分別是 Memory Channel, JDBC Channel , File Channel,Psuedo Transaction Channel。比較常見的是前三種 channel。
MemoryChannel 可以實現高速的吞吐,但是無法保證數據的完整性。
MemoryRecoverChannel 在官方文檔的建議上已經建義使用FileChannel來替換。
FileChannel保證數據的完整性與一致性。在具體配置FileChannel時,建議FileChannel設置的目錄和程序日志文件保存的目錄設成不同的磁盤,以便提高效率。
File Channel 是一個持久化的隧道(channel),它持久化所有的事件,并將其存儲到磁盤中。因此,即使 Java 虛擬機當掉,或者操作系統崩潰或重啟,再或者事件沒有在管道中成功地傳遞到下一個代理(agent),這一切都不會造成數據丟失。Memory Channel 是一個不穩定的隧道,其原因是由于它在內存中存儲所有事件。如果 java 進程死掉,任何存儲在內存的事件將會丟失。另外,內存的空間收到 RAM大小的限制,而 File Channel 這方面是它的優勢,只要磁盤空間足夠,它就可以將所有事件數據存儲到磁盤上。
Sink從Channel收集數據,運行在一個獨立線程。
Sink在設置存儲數據時,可以向文件系統、數據庫、hadoop存數據,在日志數據較少時,可以將數據存儲在文件系中,并且設定一定的時間間隔保存數據。在日志數據較多時,可以將相應的日志數據存儲到Hadoop中,便于日后進行相應的數據分析. collectorSink("fsdir","fsfileprefix",rollmillis):collectorSink,數據通過collector匯聚之后發送到hdfs, fsdir 是hdfs目錄,fsfileprefix為文件前綴碼。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“flume架構是怎么樣的”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





