溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Spark Streaming結合Flume和Kafka的日志分析是怎樣的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
按照 http://my.oschina.net/sunmin/blog/692994
整合安裝Flume+Kafka+SparkStreaming
將flume/conf/producer.conf將需要監控的日志輸出文件修改為本地的log 路徑: /var/log/nginx/www.eric.aysaas.com-access.log
(快捷鍵 Ctrl + Alt + Shift + s),點擊Project Structure界面左側的“Modules”顯示下圖界面
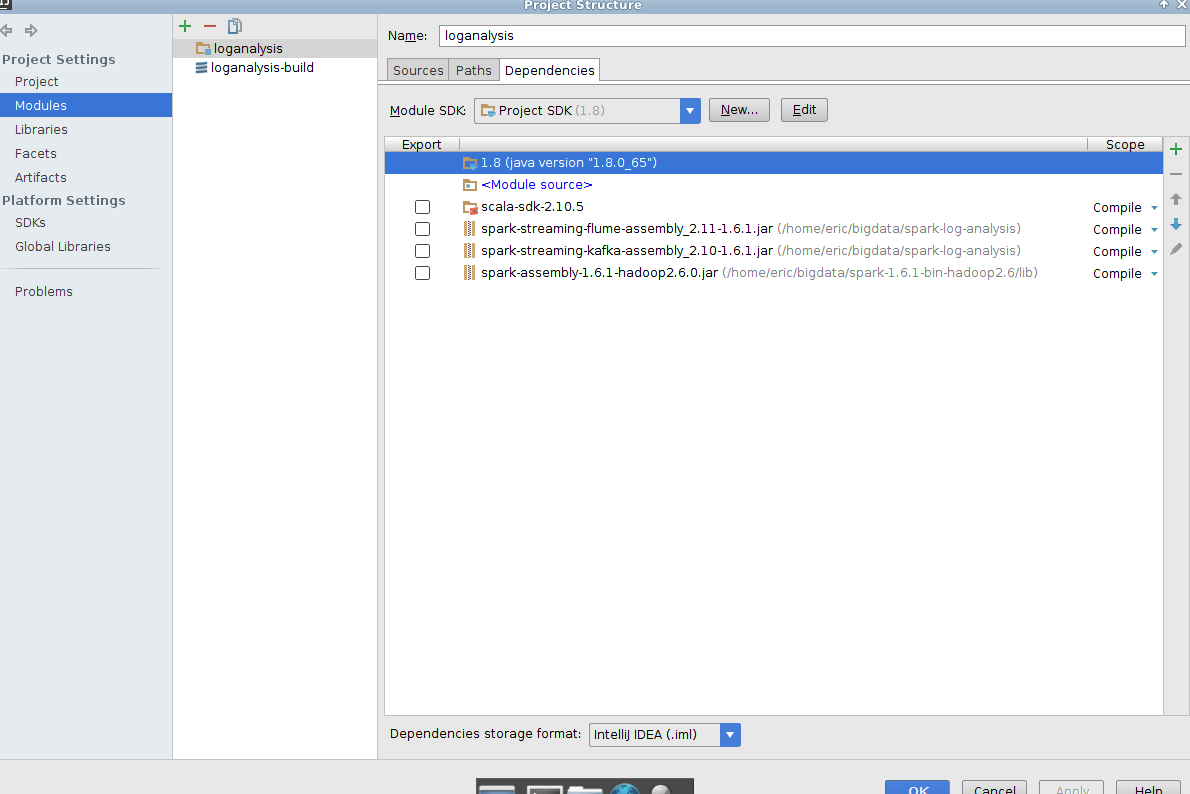
jar 包自己編譯,或者去載 http://search.maven.org/#search|ga|1|g%3A%22org.apache.spark%22%20AND%20v%3A%221.6.1%22
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* flume+kafka+SparkStreaming 實時 nginx 日志獲取
* Created by eric on 16/6/29.
*/
object KafkaLog {
def main(agrs: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[1]").setAppName("StreamingTest")
val ssc = new StreamingContext(sparkConf, Seconds(20))//代表一個給定的秒數的實例
val topic = "HappyBirthDayToAnYuan"
val topicSet = topic.split(" ").toSet
//用 brokers and topics 創建 direct kafka stream
val kafkaParams = Map[String, String]("metadata.broker.list" -> "localhost:9092")
//直接從 kafka brokers 拉取信息,而不使用任何接收器.
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicSet
)
val lines = messages.map(_._2)
lines.print()
val words: DStream[String] = lines.flatMap(_.split("\n"))
words.count().print()
//啟動
ssc.start()
ssc.awaitTermination()
}
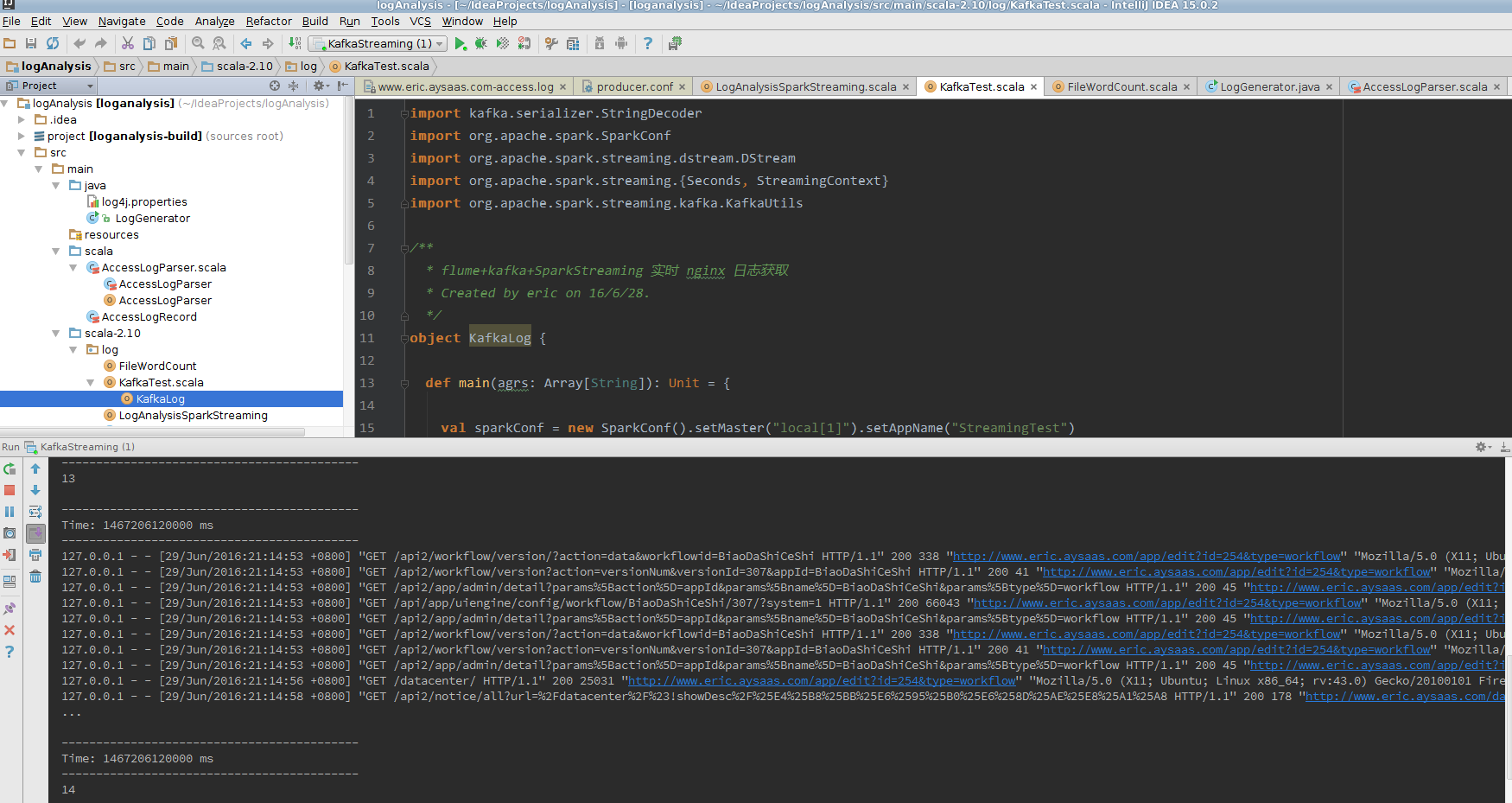
}訪問本地頁面產生日志 http://www.eric.aysaas.com/app/admin
在這20秒內總共產生的日志行數為:
看完上述內容,你們對Spark Streaming結合Flume和Kafka的日志分析是怎樣的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





