溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何進行JobScheduler內幕實現,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
在spark stream程序中的一條關鍵的語句就是:ssc.start()
1,跟蹤進入StreamingContext的start 方法,有一句非常關鍵的語句scheduler.start(),是個JobScheduler(spark stream用來job調度的)
進行job調度的入口!
2,計入JobScheduler 的start方法。
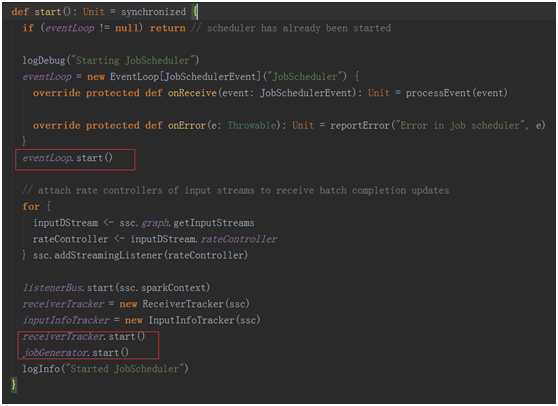
在這個方法中幾個關鍵的點是:
eventLoop.start() 一個事件循環器,用于響應其它組件發來的事件(包括job的啟動,完成,以及錯誤報告)。
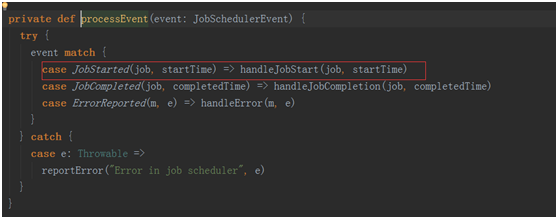 receiverTracker.start() 控制了整個receiver的生成,與數據的接受
receiverTracker.start() 控制了整個receiver的生成,與數據的接受
jobGenerator.start() 真正開始進行job的生成
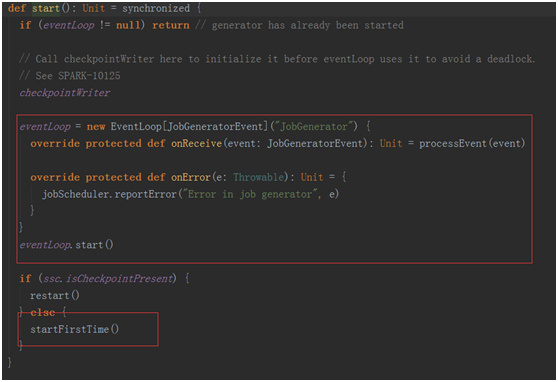 在這個方法中也維護了一個事件處理的循環器eventLoop,用于處理各種事件
在這個方法中也維護了一個事件處理的循環器eventLoop,用于處理各種事件
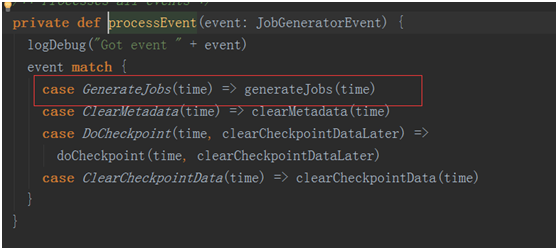 其中最為關鍵的事件是GenerateJobs(time),這個事件是進行生成job的事件!!
其中最為關鍵的事件是GenerateJobs(time),這個事件是進行生成job的事件!!
跟蹤計入generateJobs(time)
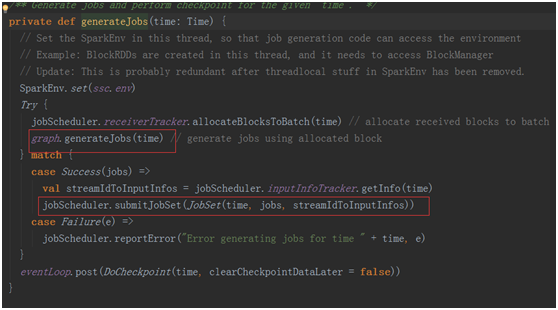
jobScheduler.receiverTracker.allocateBlocksToBatch(time) 為當前的bath分發收到的數據Blocks。
graph.generateJobs(time):根據當前編寫的程序的output動作生成相應的job并封裝進入集合中。
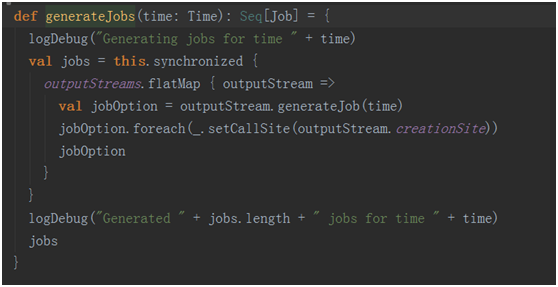
最終通過
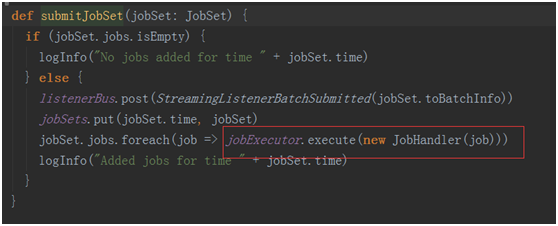
 提交作業到executor
提交作業到executor
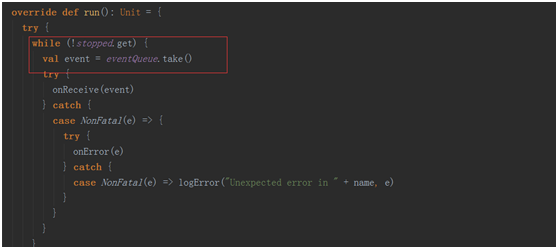
在回去看看jobGenerator.start()中的startFirstTime()
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
graph.start(startTime - graph.batchDuration)
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}第一次啟動會啟動一個定時器,該定時器會根基duration bath 不斷的的給jobGenerator中的消息循環體!
在jobGenerator中的消息循環體就會不斷的去除消息進行處理
以上就是如何進行JobScheduler內幕實現,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





