溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Analyzing plans
分析計劃
要真正了解查詢計劃并真正能夠發現、修復或解決查詢計劃的問題, 需要對組成這些計劃的查詢操作有一個扎實的理解。總的來說, 有太多的操作員可以在一章中討論它們。此外, 可以以無數的方式將這些運算符合并到查詢計劃中。因此, 本節側重于了解最常見的查詢運算符-查詢執行的最基本的構造塊, 并對 SQL server 如何使用它們構建各種有趣的查詢計劃提供一些了解。具體地說, 本節查看掃描并查找、聯接、聚合、聯合、選擇子查詢計劃和并行性。在了解這些基本操作和計劃如何工作之后, 可以讓你盡可能地分解并理解更大、更復雜的查詢計劃。
Scans and Seeks
掃描和查找
掃描和查找是 SQL server 用來從表和索引中讀取數據的迭代器。這些迭代器是 SQL server 支持的最基本的。它們幾乎出現在每個查詢計劃中。了解掃描和查找之間的不同之處很重要: 掃描處理整個表或一個索引的整個葉級別, 而查找有效地根據謂詞從索引的一個或多個范圍返回行。
首先看一下掃描的例子。請考慮以下查詢:
SELECT [OrderId] FROM [Orders] WHERE [RequiredDate] = '1998-03-26'
RequiredDate 列沒有索引。因此, SQL server 必須讀取 Orders 表的每一行。計算每行的 RequiredDate 的謂詞;如果謂詞為 true (即, 如果行符合資格), 則返回該行。
為了最大化性能, SQL server 盡可能在掃描迭代器中計算謂詞。但是, 如果謂詞太復雜或太貴(損耗性能), 則 SQL server 可能會在單獨的篩選器迭代程序中對其進行評估。謂詞以 WHERE 關鍵字或 XML 計劃中的標記出現在文本計劃中<Predicate></Predicate>。
以下是前面查詢的文本計劃:
|--Clustered Index Scan(OBJECT:([Orders].[PK_Orders]),
WHERE:([Orders].[RequiredDate]='1998-03-26'))
圖10-6 以掃描為例。
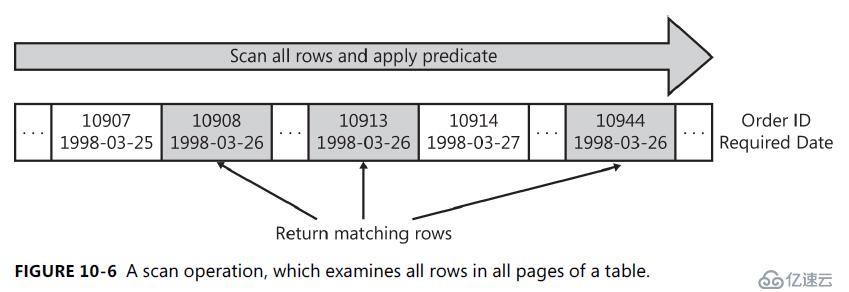
由于掃描會觸及表中的每一行是否符合條件, 因此成本與表中的總行數成正比。因此, 如果表較小或許多行符合謂詞的條件, 則掃描是一種有效的策略。但是, 如果表很大, 并且大多數行不符合條件, 則掃描會觸及更多的頁面和行, 并執行更多不必要的 i/o
現在來看一個索引查找的示例。假設我們有一個類似的查詢, 但這次謂詞在 OrderDate 列上有一個索引:
SELECT [OrderId] FROM [Orders] WHERE [OrderDate] = '1998-02-26'
這一次, SQL server 可以使用索引直接定位到符合謂詞的行。在這種情況下, 謂詞稱為查找謂詞。在大多數情況下, SQL server 不需要顯式地評估查找謂詞,索引可確保查找操作只返回符合條件的行。
查找謂詞以SEEK關鍵字或 XML 計劃中的標記出現在文本計劃中<SeekPredicates></SeekPredicates>。
以下是本示例的文本計劃:
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD)
SQL server 通過自動參數化查詢方法將參數 @1 替換為日期格式。
圖10-7 索引查找舉例。
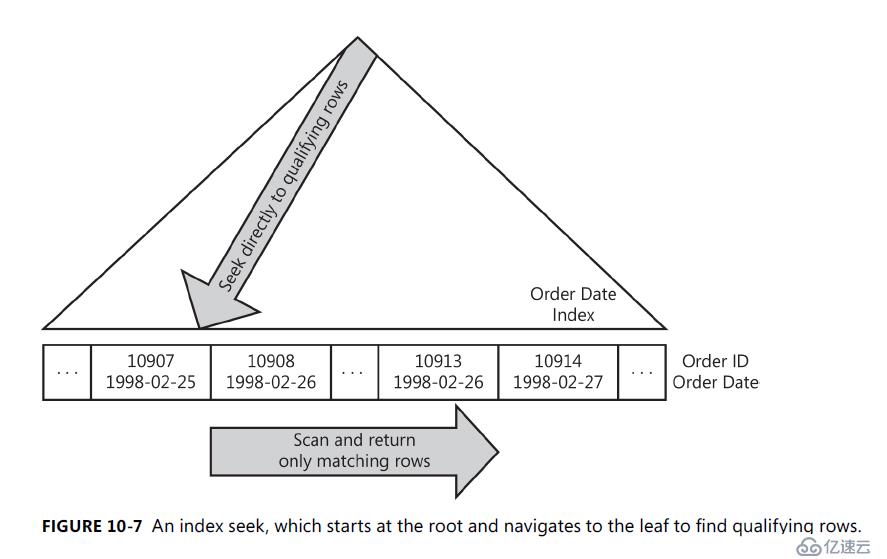
由于查找僅觸及符合資格的行和包含這些限定行的頁, 因此成本與限定行和頁的數量成正比, 而不是與表中的總行數成比例。因此, 在使用高度選擇性的查找謂詞時, 查找通常是一種更有效的策略, 即, 如果查找謂詞排除表的很大一部分。
SQL server 區分掃描和查找以及堆上的掃描 (沒有聚集索引的表)、對聚集索引的掃描以及對非聚集索引的掃描。
表10-2 所有有效組合在計劃輸出中的顯示。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





