溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“hadoop2.7.1環境的搭建方法”,在日常操作中,相信很多人在hadoop2.7.1環境的搭建方法問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”hadoop2.7.1環境的搭建方法”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在老板的支持下,陸續劃拉到了10幾臺機器,綁定了固定IP,工作之余開始了Hadoop之旅。將要點記錄下來,以備查閱。
硬件構成:
Resource | Volume |
CPU | 2 cores |
Memory | 4 GB |
Disk | 500 GB |
Network | 100 M |
軟件構成:
Name | Version | Install Path |
CentOS | 6.7 x86_64 | / |
Oracle JDK | 7u79-linux-x64 | /usr/local/java/ |
Hadoop | 2.7.1 | /home/hadoop/ |
Flume | 1.6.0 | /home/flume/ |
Maven | 3.3.9 | /usr/local/maven/ |
Ant | 1.9.6 | /usr/local/ant |
5.6.21 Community Server | /home/mysql/ | |
D3.js | v3 |
整體架構:
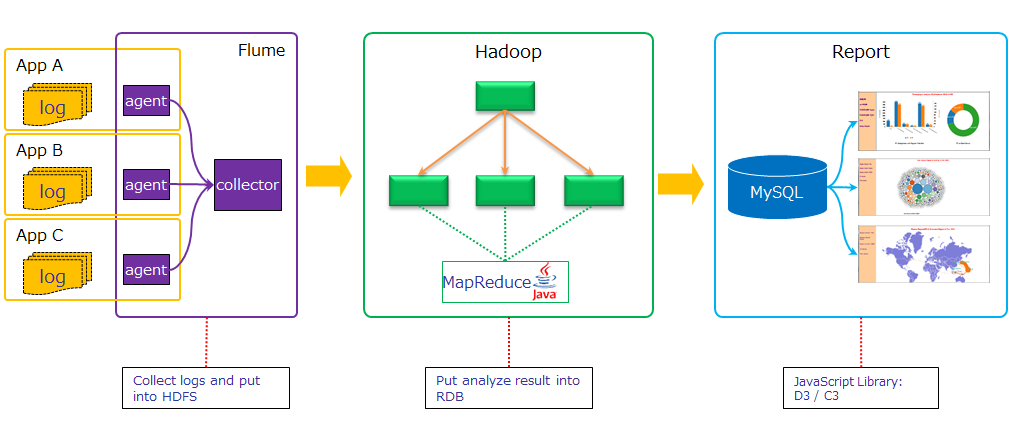
DFS和Yarn構成:
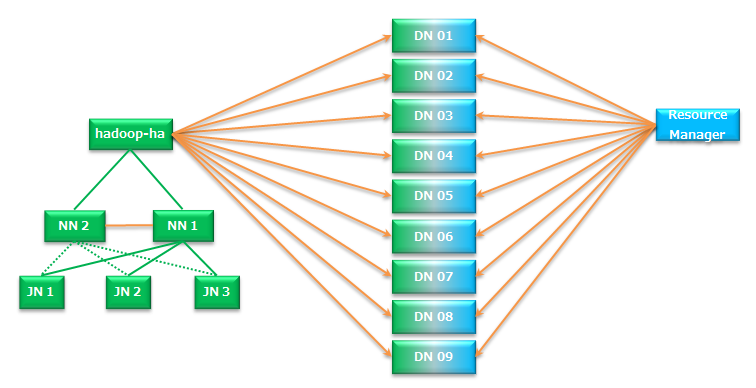
各個節點需要的配置:
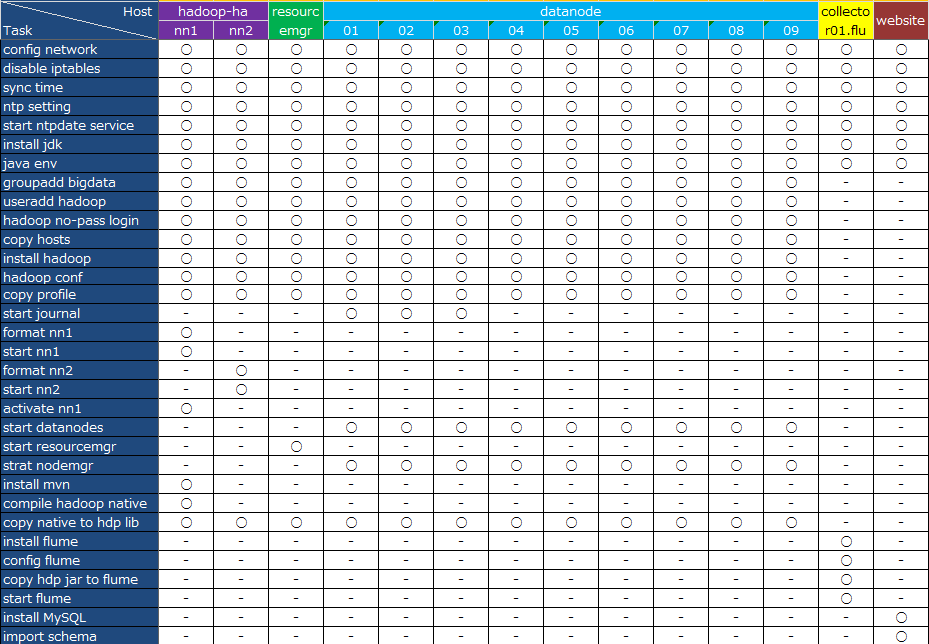
調試hadoop節點用到的命令:
sbin/hadoop-daemon.sh start journal
bin/hdfs namenode format
sbin/hadoop-daemon.sh start namenode
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
bin/hdfs haadmin -transitionToActive nn1
sbin/hadoop-daemons.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
調試完畢后的集群啟動/關閉命令:
sbin/start-dfs.sh
sbin/start-yarn.sh
bin/hdfs haadmin -transitionToActive nn1
sbin/stop-dfs.sh
sbin/stop-yarn.sh
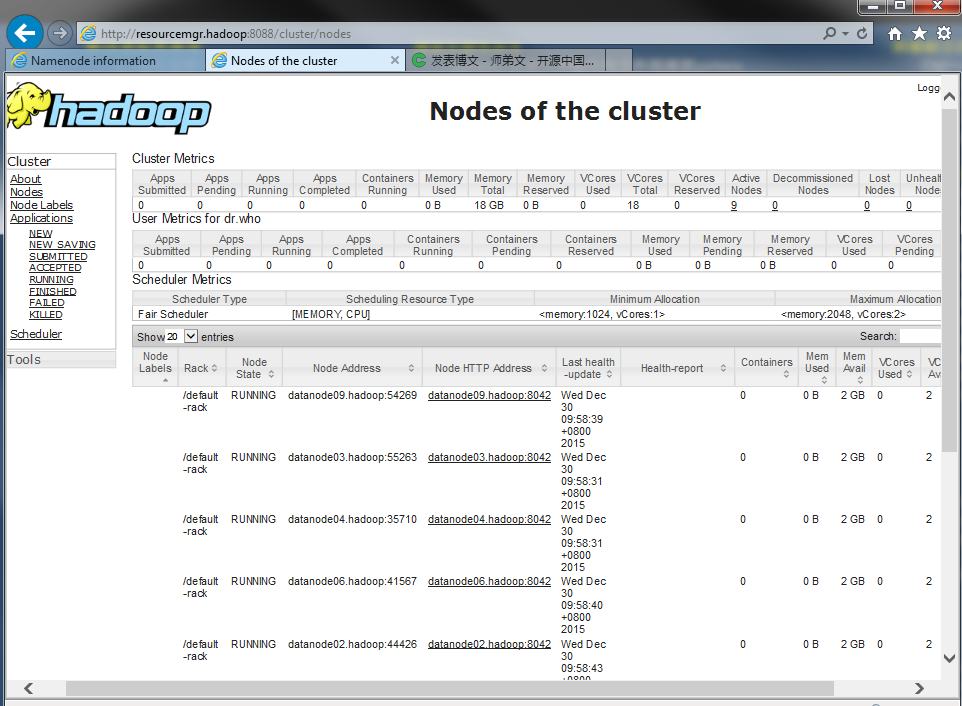
DFS管理界面:
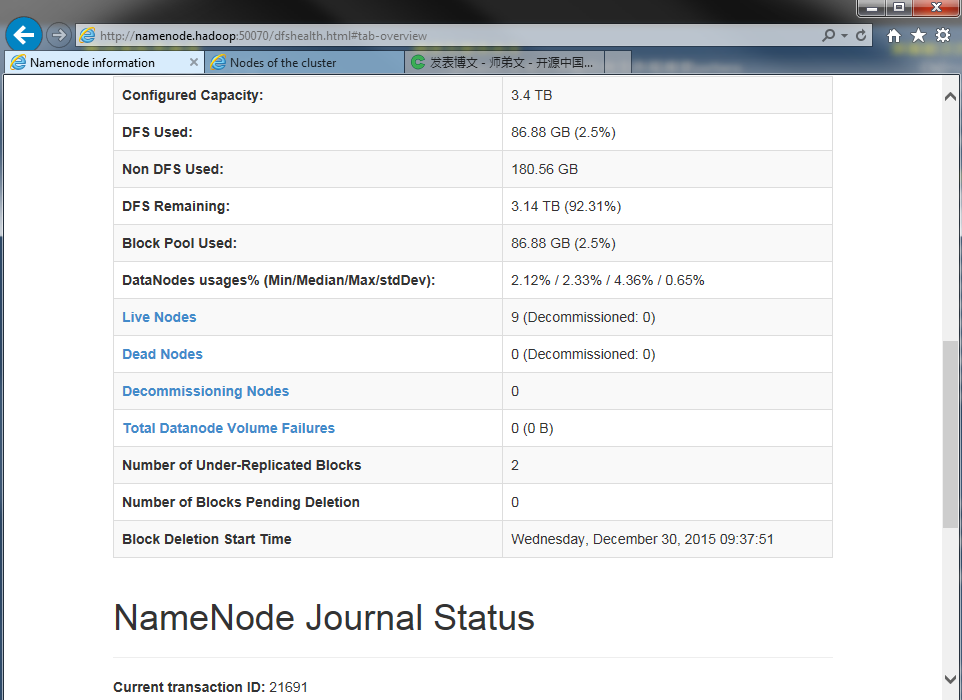
YARN管理界面:
正在把150G日志手動導入DFS,暫時還沒用上Flume,后面逐步集成進來。
MR運行結果存入DFS或者灌入MySQL都試驗成功,回頭整理。
Yarn的資源隊列臨時配置了一個,現在只是能跑,還不明白咋回事,抽時間繼續研究。
在4個data node節點上(昨晚才湊到9節點)對15G日志跑一個過濾useragent的MR,需要8分鐘,這樣算下來需要1天時間才能對1個月的日志解析完,孰能忍!性能優化需要陸續展開。
到此,關于“hadoop2.7.1環境的搭建方法”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





