溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
最近由于業務需求,測試各種組件的高可用性。由于我們的環境在AWS 北京部署。只有兩個Aviable Zone(可用區)。
注釋:有兩個數據中心,相互需要做容災的需求,和本文測試的情況是相同的。
而Zookeeper需要3個以上的單數節點同時工作,并且,必須保證半數以上的節點存活,還能正常提供服務。
那么,針對只有兩個AZ的情況,不管怎么規劃,都有概率遇到存在半數以上的AZ掛掉,導致整個Zookeeper不可用的情況。
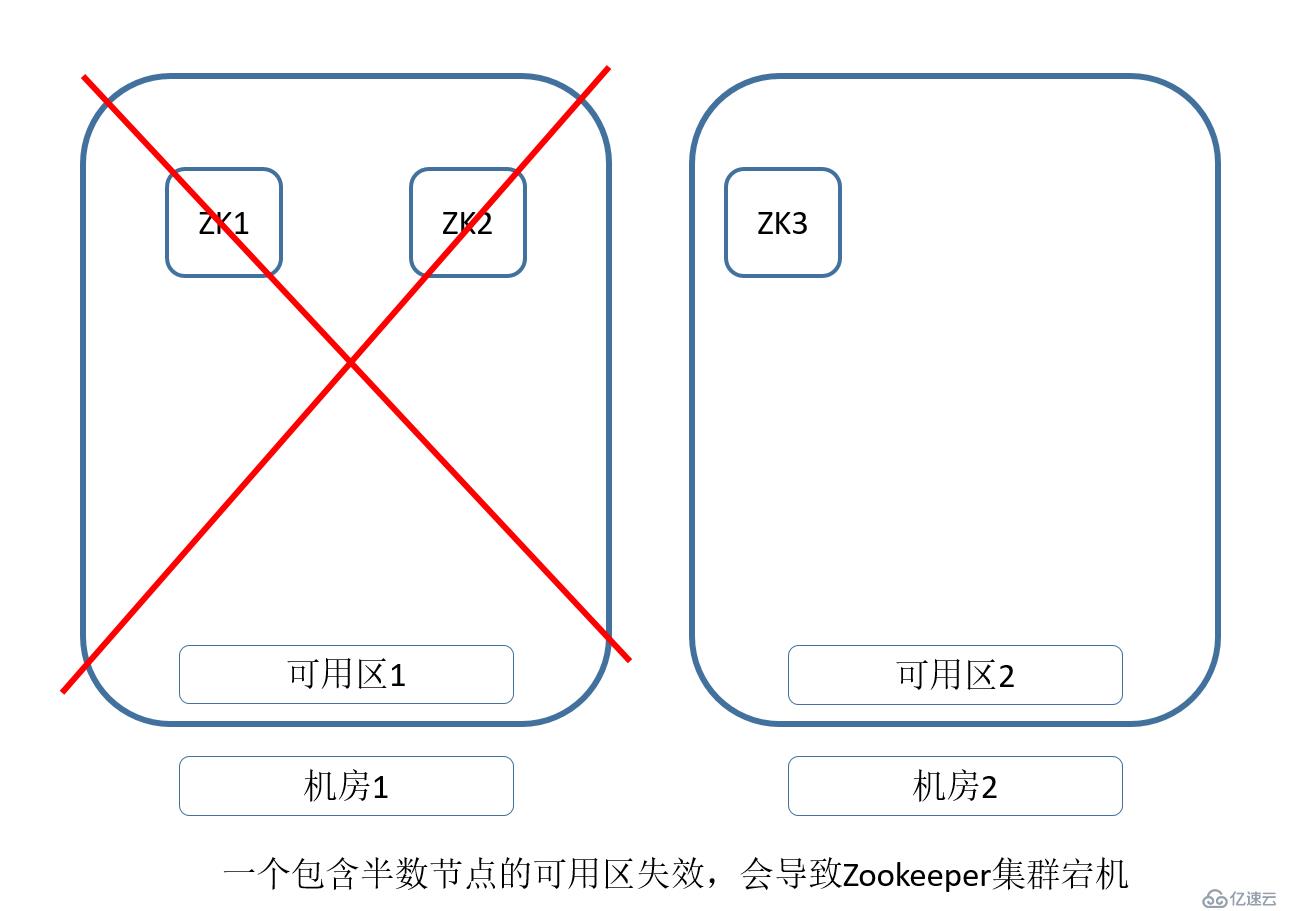
所以,我們能做的就是,在這個AZ掛掉之后,我們怎么盡快處理,并恢復環境。
我們準備兩個軟件安裝好,參數配置好的機器。在可用區1完全掛掉之后,可以手動啟動兩個備用節點。將可用區2的Zookeeper數量增加過半數。就可以在可用區2恢復Zookeeper的服務。
參考下圖:
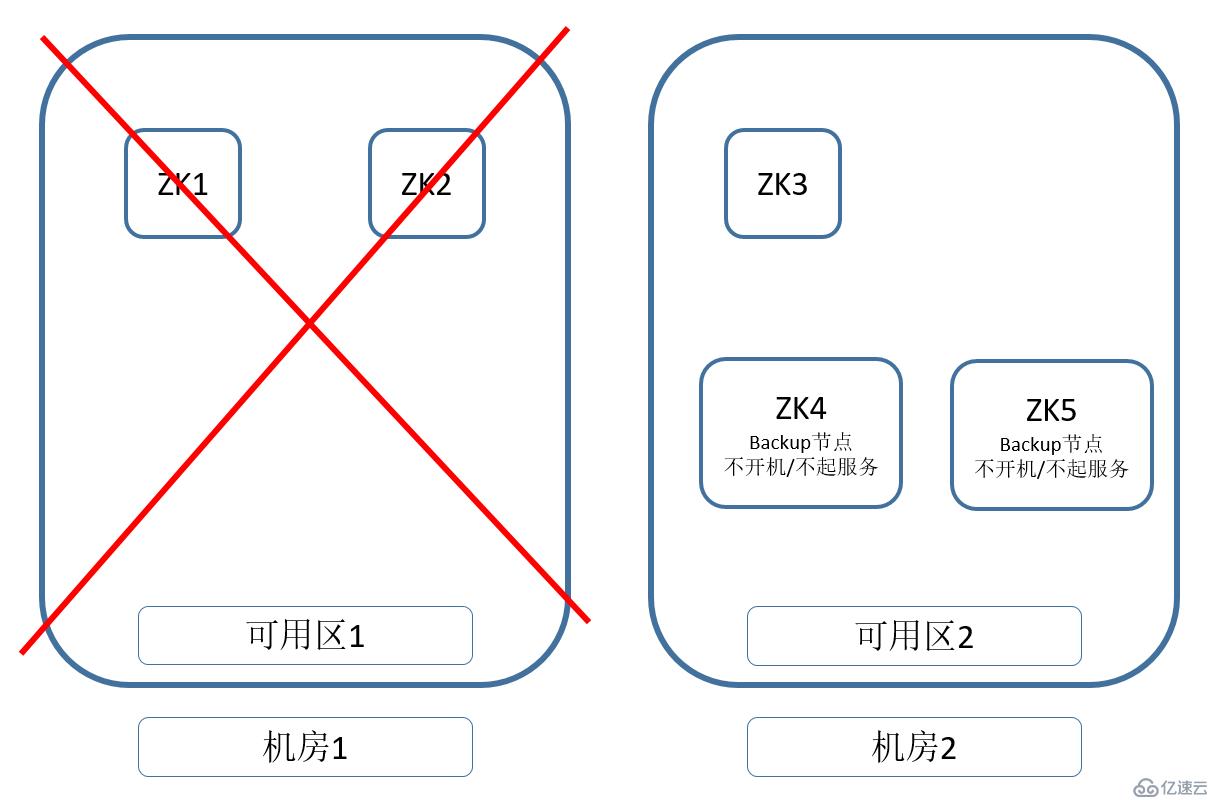
以上的設想,是否能實現呢?
那我們今天就來測試一下。
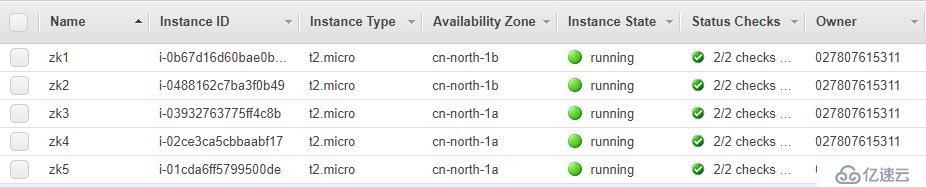
1. 一共準備了5臺機器,作為測試
2. Zookeeper的下載與安裝。
2.1 Zookeeper官方下載地址
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
2.2 下載軟件
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2.3 詳細Zookeeper安裝步驟,請參考:
https://blog.51cto.com/hsbxxl/1971241
2.4 zoo.cfg的配置 #cat zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=6 server.1=172.31.9.73:2888:3888 server.2=172.31.20.233:2888:3888 server.3=172.31.26.111:2888:3888 server.4=172.31.17.68:2888:3888 server.5=172.31.16.33:2888:3888
2.5 ?根據zoo.cfg創建data和log兩個文件夾
mkdir?-p?/data/zookeeper/data? mkdir?-p?/data/zookeeper/log
2.6 根據節點號碼,修改文件
echo?1?>?/data/zookeeper/data/myid
3. 一共準備了5臺EC2進行測試,并且都已經安裝好Zookeeper
但是只啟動三臺,另兩個機器作為standby
下圖可以看到,已經有三臺啟動zookeeper,
注意,在Zookeeper啟動的過程中,必須保證三臺及以上,zookeeper集群才能正常工作
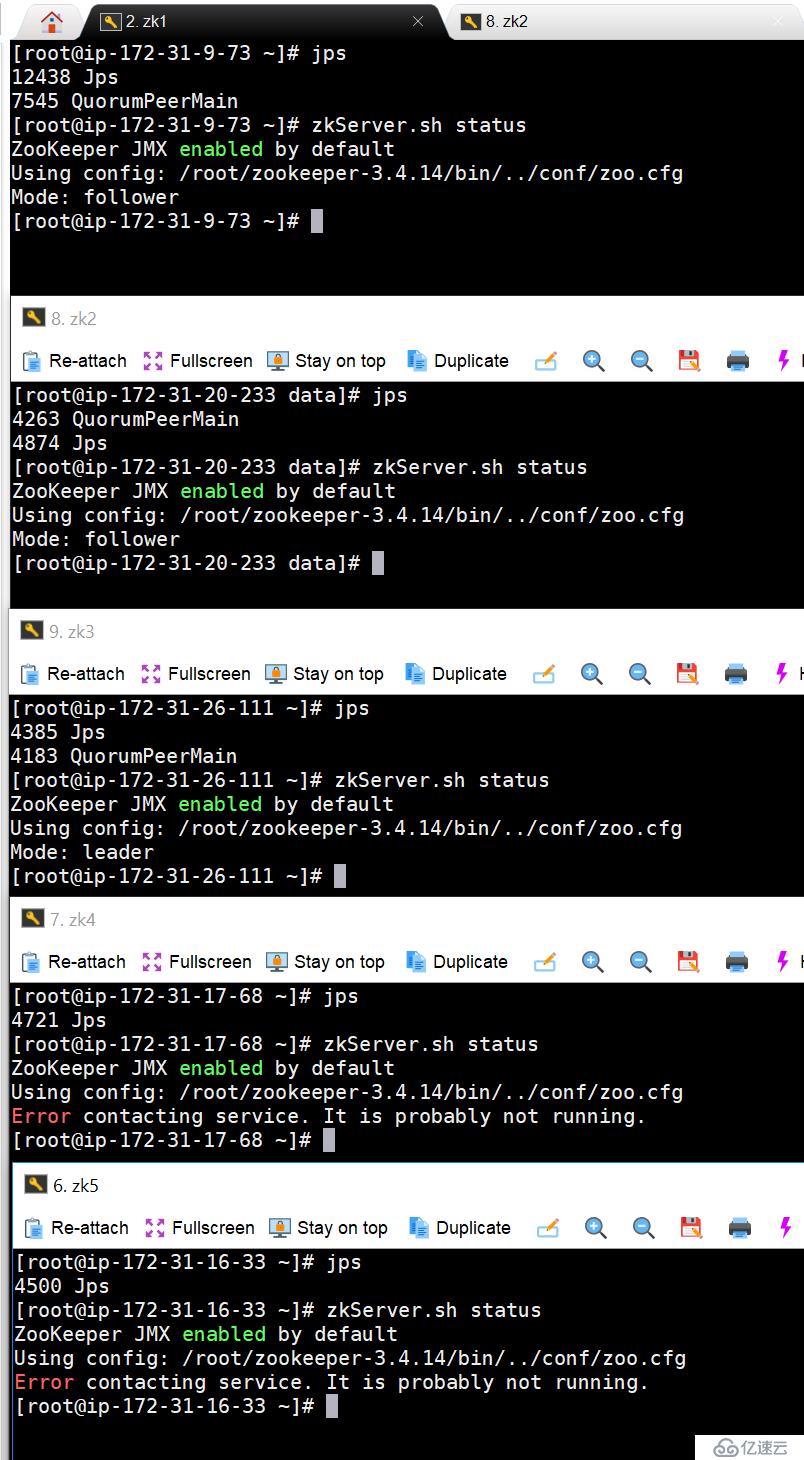
4. 接下來,我開始逐個機器關機,看zookeeper的狀態
當前leader在zk3上,我們先關閉zk1,再關閉zk3,看Leader會不會飄到zk2上
4.1 在zk1上執行kill,殺掉進程
[root@ip-172-31-9-73?~]#?jps 12438?Jps 7545?QuorumPeerMain [root@ip-172-31-9-73?~]#?zkServer.sh?status ZooKeeper?JMX?enabled?by?default Using?config:?/root/zookeeper-3.4.14/bin/../conf/zoo.cfg Mode:?follower [root@ip-172-31-9-73?~]#?kill?-9?7545
4.2 在zk5上通過zkCli鏈接zk3,并可以查詢數據。
在zk1上kill掉進程之后,理論上,還有zk2和zk3存活,但是zkCli的連接顯示已經報錯。
[root@ip-172-31-16-33?bin]#?./zkCli.sh?-server?172.31.26.111:2181 Connecting?to?172.31.26.111:2181 ...... [zk:?172.31.26.111:2181(CONNECTED)?0]?ls?/ [zk-permanent,?zookeeper,?test] [zk:?172.31.26.111:2181(CONNECTED)?1]?2019-06-23?07:28:06,581?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1158]?-?Unable?to?read?additional?data?from?server?sessionid?0x30000c504530000,?likely?server?has?closed?socket,?closing?socket?connection?and?attempting?reconnect ...... 2019-06-23?07:28:09,822?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]?-?Opening?socket?connection?to?server?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.?Will?not?attempt?to?authenticate?using?SASL?(unknown?error) 2019-06-23?07:28:09,824?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@879]?-?Socket?connection?established?to?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181,?initiating?session 2019-06-23?07:28:09,825?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1158]?-?Unable?to?read?additional?data?from?server?sessionid?0x30000c504530000,?likely?server?has?closed?socket,?closing?socket?connection?and?attempting?reconnect
4.3 我們繼續 kill掉zk3上的進程,只保留zk2上的進程。但是我們已經無法確認zk2是Leader還是Follow,或者說,他是否還保留有數據。
[root@ip-172-31-26-111?bin]#?jps 4183?QuorumPeerMain 4648?Jps [root@ip-172-31-26-111?bin]#?kill?-9?4183 [root@ip-172-31-26-111?bin]#?jps 4658?Jps
4.4 zk3上進程kill掉之后,鏈接就不只是上面的報錯了,而是直接連接拒絕
[root@ip-172-31-16-33?bin]#?./zkCli.sh?-server?172.31.26.111:2181 Connecting?to?172.31.26.111:2181 ...... Welcome?to?ZooKeeper! 2019-06-23?07:35:18,411?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]?-?Opening?socket?connection?to?server?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.?Will?not?attempt?to?authenticate?using?SASL?(unknown?error) JLine?support?is?enabled 2019-06-23?07:35:18,533?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1162]?-?Socket?error?occurred:?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181:?Connection?refused [zk:?172.31.26.111:2181(CONNECTING)?0]?2019-06-23?07:35:19,639?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1025]?-?Opening?socket?connection?to?server?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181.?Will?not?attempt?to?authenticate?using?SASL?(unknown?error) 2019-06-23?07:35:19,640?[myid:]?-?INFO??[main-SendThread(ip-172-31-26-111.cn-north-1.compute.internal:2181):ClientCnxn$SendThread@1162]?-?Socket?error?occurred:?ip-172-31-26-111.cn-north-1.compute.internal/172.31.26.111:2181:?Connection?refused
4.5 可以看到zk2上的進程還在,
#?jps 5155?QuorumPeerMain 5211?Jps
4.6 并且通過下面命令,可以檢查到zk2 的2181端口還在提供服務
#?echo?ruok?|?nc?localhost?2181 imok
4.7 但是其他命令是沒有正常輸出的,只有echo ruok | nc localhost 2181輸出ok。
#?echo?ruok?|?nc?172.31.16.33?2181 imok[root@ip-172-31-16-33?bin]#?echo?conf?|?nc?172.31.16.33?2181 This?ZooKeeper?instance?is?not?currently?serving?requests #?echo?dump?|?nc?172.31.16.33?2181 This?ZooKeeper?instance?is?not?currently?serving?requests
4.8 ?ZooKeeper 四字命令
ZooKeeper 四字命令 | 功能描述 |
conf | 輸出相關服務配置的詳細信息。 |
cons | 列出所有連接到服務器的客戶端的完全的連接 / 會話的詳細信息。包括“接受 / 發送”的包數量、會話 id 、操作延遲、最后的操作執行等等信息。 |
dump | 列出未經處理的會話和臨時節點。 |
envi | 輸出關于服務環境的詳細信息(區別于 conf 命令)。 |
reqs | 列出未經處理的請求 |
ruok | 測試服務是否處于正確狀態。如果確實如此,那么服務返回“imok ”,否則不做任何相應。 |
stat | 輸出關于性能和連接的客戶端的列表。 |
wchs | 列出服務器 watch 的詳細信息。 |
wchc | 通過 session 列出服務器 watch 的詳細信息,它的輸出是一個與watch 相關的會話的列表。 |
wchp | 通過路徑列出服務器?watch 的詳細信息。它輸出一個與 session相關的路徑。 |
4.9 正常情況下,以上命令可以輸出:
# echo dump | nc 172.31.20.233 2181
SessionTracker?dump: org.apache.zookeeper.server.quorum.LearnerSessionTracker@77714302 ephemeral?nodes?dump: Sessions?with?Ephemerals?(0):
# echo conf | nc 172.31.20.233 2181
clientPort=2181 dataDir=/data/zookeeper/data/version-2 dataLogDir=/data/zookeeper/log/version-2 tickTime=2000 maxClientCnxns=60 minSessionTimeout=4000 maxSessionTimeout=40000 serverId=2 initLimit=10 syncLimit=5 electionAlg=3 electionPort=3888 quorumPort=2888 peerType=0
# echo envi| nc 172.31.20.233 2181
Environment: zookeeper.version=3.4.14-4c25d480e66aadd371de8bd2fd8da255ac140bcf,?built?on?03/06/2019?16:18?GMT host.name=ip-172-31-20-233.cn-north-1.compute.internal java.version=1.8.0_212 java.vendor=Oracle?Corporation java.home=/usr/java/jdk1.8.0_212-amd64/jre java.class.path=/root/zookeeper-3.4.14/bin/../zookeeper-server/target/classes:/root/zookeeper-3.4.14/bin/../build/classes:/root/zookeeper-3.4.14/bin/../zookeeper-server/target/lib/*.jar:/root/zookeeper-3.4.14/bin/../build/lib/*.jar:/root/zookeeper-3.4.14/bin/../lib/slf4j-log4j12-1.7.25.jar:/root/zookeeper-3.4.14/bin/../lib/slf4j-api-1.7.25.jar:/root/zookeeper-3.4.14/bin/../lib/netty-3.10.6.Final.jar:/root/zookeeper-3.4.14/bin/../lib/log4j-1.2.17.jar:/root/zookeeper-3.4.14/bin/../lib/jline-0.9.94.jar:/root/zookeeper-3.4.14/bin/../lib/audience-annotations-0.5.0.jar:/root/zookeeper-3.4.14/bin/../zookeeper-3.4.14.jar:/root/zookeeper-3.4.14/bin/../zookeeper-server/src/main/resources/lib/*.jar:/root/zookeeper-3.4.14/bin/../conf: java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib java.io.tmpdir=/tmp java.compiler=<NA> os.name=Linux os.arch=amd64 os.version=4.14.123-86.109.amzn1.x86_64 user.name=root user.home=/root user.dir=/root/zookeeper-3.4.14/bin
5. 這個時候,我去啟動另外兩個備用節點,zk4,zk5.這個兩個節點都是第一次啟動。
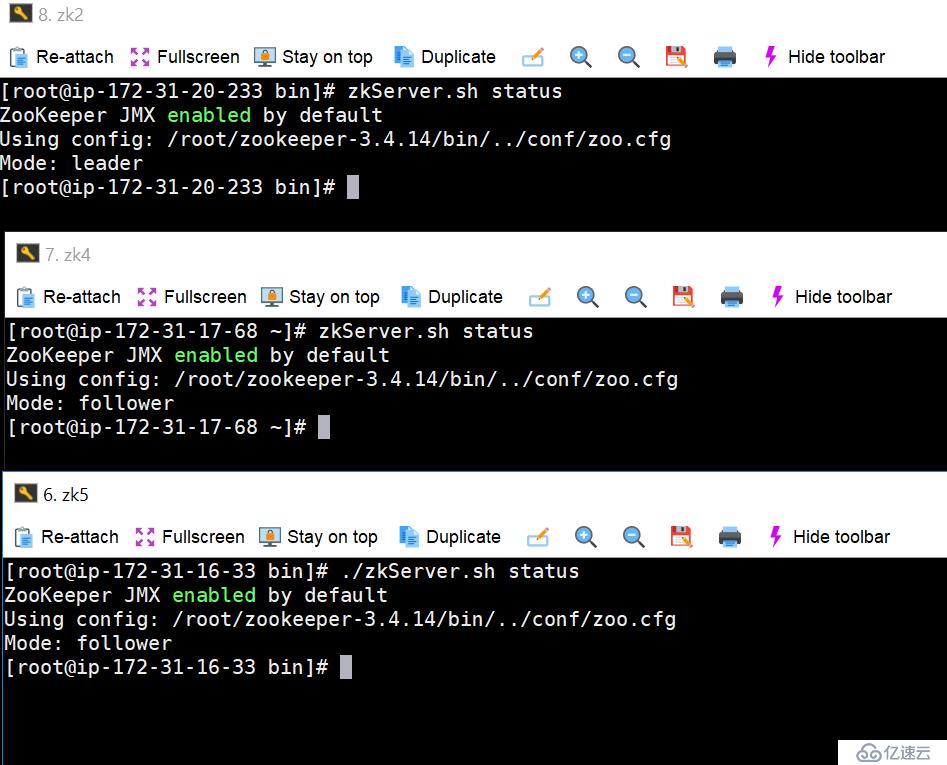
6. 再次連接到zookeeper上,可以看到,至少數據還是沒有丟失的
[root@ip-172-31-16-33?bin]#?./zkCli.sh?-server?172.31.16.33:2181 Connecting?to?172.31.16.33:2181 ...... [zk:?172.31.16.33:2181(CONNECTED)?0]?ls?/ [zk-permanent,?zookeeper,?test]
7. 通過以上測試,似乎是達到我們預期的結果。唯一的一點小問題,就是:我們有3個節點,為什么關閉1個,剩余兩個,就不能正常運行了呢?
其實,這里是有個“想當然”的小問題。
我們以為,只啟動三個. 其實,Zookeeper集群,識別的是5個, 為什么呢?
Zookeeper靠什么去識別集群中有幾個節點呢?當然不是靠“想當然”。一定是有配置文件告訴它。Zookeeper,只有兩個配置文件zoo.cfg和myid。
那就只有zoo.cfg會影響到它了。
8. 我將zoo.cfg做如下修改之后。只開啟3個節點,在關閉一個節點之后,還是可以正常運行的。
注釋掉server2和server5
#?cat?zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=6 server.1=172.31.9.73:2888:3888 #server.2=172.31.20.233:2888:3888 server.3=172.31.26.111:2888:3888 server.4=172.31.17.68:2888:3888 #server.5=172.31.16.33:2888:3888
9. 關閉server4之后,還有server2和server3活著。
[root@ip-172-31-26-111?~]#?zkServer.sh?status ZooKeeper?JMX?enabled?by?default Using?config:?/root/zookeeper-3.4.14/bin/../conf/zoo.cfg Mode:?leader [root@ip-172-31-9-73?~]#?zkServer.sh?status ZooKeeper?JMX?enabled?by?default Using?config:?/root/zookeeper-3.4.14/bin/../conf/zoo.cfg Mode:?follower
10. 總結,如果考慮兩個AZ的情況下,zookeeper節點數多的AZ出現災難情況,我們如何快速恢復?
(假設Server1/Server2在1AZ,Server3/Server4/Server5在2AZ)
10.1. 在Zookeeper節點少的AZ,多準備2臺配置好zookeeper的EC2,并關機待使用。Server4/Server5具體zoo.cfg配置如下
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=6 server.3=172.31.26.111:2888:3888 server.4=172.31.17.68:2888:3888 server.5=172.31.16.33:2888:3888
10.2. ?Server1/Server2/Server3,是正常運行的節點,配置如下:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=6 server.1=172.31.9.73:2888:3888 server.2=172.31.20.233:2888:3888 server.3=172.31.26.111:2888:3888
10.3. ?災難發生,Server1/Server2所在的1AZ掛掉的情況下,需要人工介入,將Server3的配置更改為如下配置,并重啟Server3的zookeeper服務,然后啟動Server4/Server5,一定要先啟動Server3,注意順序。
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=6 server.3=172.31.26.111:2888:3888 server.4=172.31.17.68:2888:3888 server.5=172.31.16.33:2888:3888
10.4 日常運行狀態
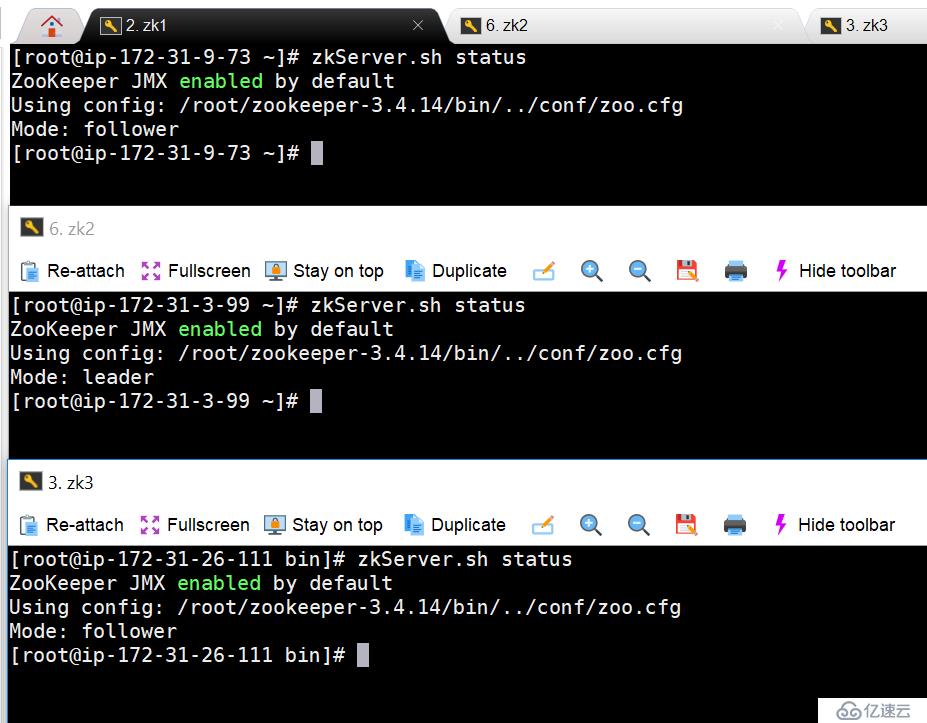
10.5 檢查已經創建的znode信息
./zkCli.sh?-server?172.31.16.33:2181?ls?/ Connecting?to?172.31.16.33:2181 [zk-permanent,?zookeeper,?test]
10.6 關閉Server1/Server2,注意順序,先關閉follow,如果先關閉leader,會發生切換。我們期望的是Server3最后以follow的身份存活。
11. 最終可以看到測試結果,一切都是按照我們“想當然”的方向發展。
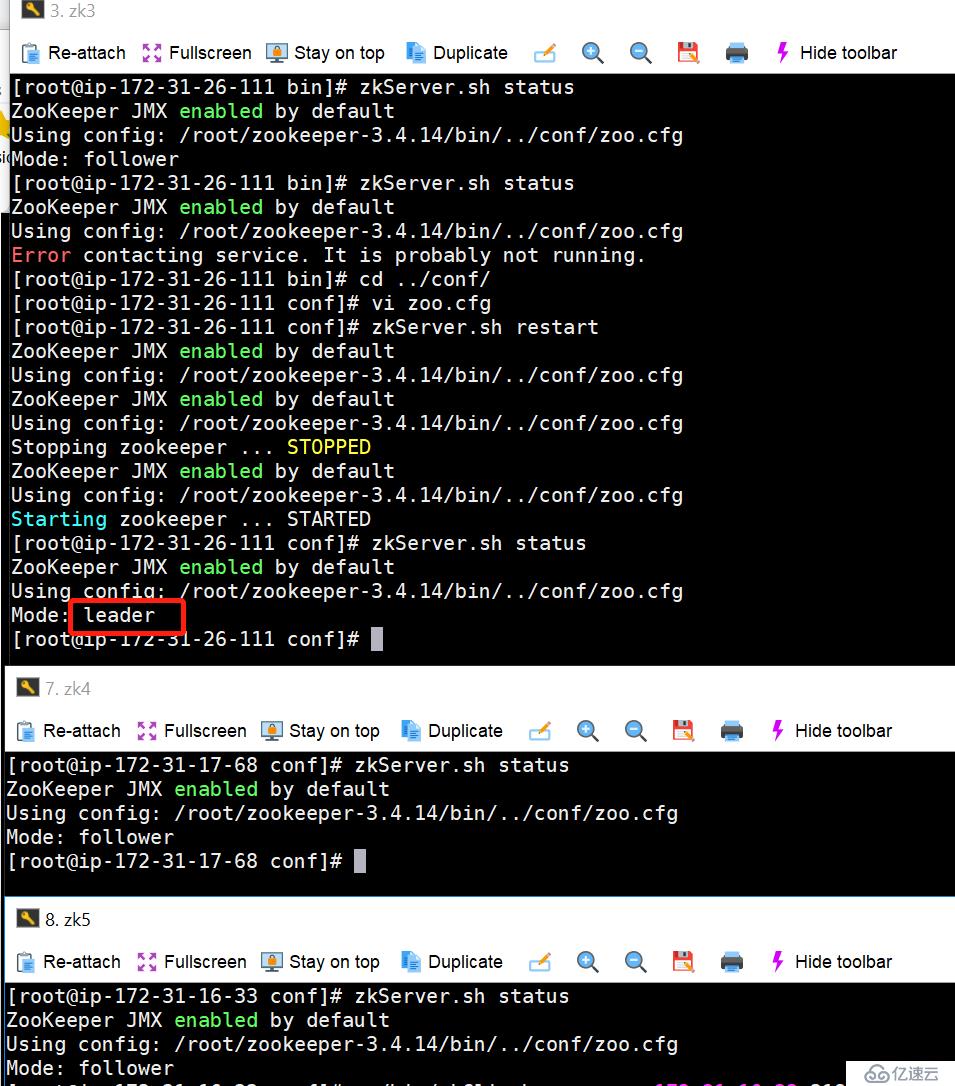
12. 最后驗證zookeeper中的znode數據,還是都存在的。
./zkCli.sh??-server?172.31.16.33:2181?ls?/ Connecting?to?172.31.16.33:2181 [zk-permanent,?zookeeper,?test]
13. 其實數據一直是在這個路徑下,只要有一個節點還保留,就會保存下去。
#?ls?/data/zookeeper/data/ myid??version-2??zookeeper_server.pid
注意:一定要保證Server4/Server5的下面兩個路徑是空的,不然會出現,Server4/Server5識別的是之前的陳舊信息。
/data/zookeeper/data/version-2 /data/zookeeper/log/version-2
14. 說到這里,我們可以理解到,Zookeeper的全部數據,都是存放在下面兩個路徑中。如果需要做備份,可以直接在OS層面,做cp備份即可。
dataDir=/data/zookeeper/data dataLogDir=/data/zookeeper/log
衍生一個想法,就是如果想做跨Region,北京(主環境)到寧夏(容災環境)的zookeeper的高可用怎么做呢?
我們可以考慮將北京的zookeeper的數據文件定期備份,并導入到寧夏的環境。
具體步驟:
<1. 在寧夏啟動一個Zookeeper集群,并配置好,然后關閉zookeeper服務,清空掉數據文件夾。
<2. 在北京,通過腳本定期檢查zookeeper各個節點狀態,從一個運行健康的節點,定期備份數據到S3的一個bucket,為每個文件加上時間戳。
<3. 通過S3的Cross Region Replication,同步到寧夏。
<4. 然后在寧夏,從S3讀取備份文件,并還原到災備的zookeeper中。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





