溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么使用卷積神經網絡和openCV預測年齡和性別,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
越來越多的應用程序與年齡和性別的自動分類相關,特別是自從社交平臺和社交媒體興起以來。盡管如此,現有的方法在真實圖像上的性能仍然明顯不足,特別是與最近報道的與人臉識別相關的任務在性能上的巨大飛躍相比。——使用卷積神經網絡進行年齡和性別分類(https://talhassner.github.io/home/publication/2015_CVPR)
年齡和性別是人臉的兩個重要屬性,在社會交往中起著非常基礎的作用,使得從單個人臉圖像中估計年齡和性別成為智能應用中的一項重要任務,如訪問控制、人機交互、執法、營銷智能以及視覺監控等。
真實世界用例:
最近我遇到了Quividi,它是一個人工智能軟件應用程序,用于根據在線人臉分析檢測經過的用戶的年齡和性別,并根據目標受眾自動開始播放廣告。
另一個例子可能是AgeBot,它是一個Android應用程序,通過人臉識別從照片中確定你的年齡。它可以猜測你的年齡和性別,同時也可以在一張照片中找到多張臉,并估計每張臉的年齡。
受上述用例的啟發,我們將在本文中構建一個簡單的年齡和性別檢測模型。所以讓我們從我們的用例開始:
用例——我們將做一些人臉識別,人臉檢測的工作,而且,我們將使用CNN(卷積神經網絡)從youtube視頻中預測年齡和性別,只要視頻URL是可以用的,你就不需要下載視頻。有趣的部分是CNN在視頻網址上用于年齡和性別預測。
要求: pip install OpenCV-python numpy pip install pafy pip install youtube_dl(了解更多關于youtube-dl的信息:https://rg3.github.io/youtube-dl/)
pafy:pafy庫用于檢索YouTube內容和元數據(如標題、分級、觀看次數、持續時間、分級、作者、縮略圖、關鍵字等)。更多有關pafy,點擊網址:https://pypi.org/project/pafy/
讓我們檢查一個樣本:
import pafy url = 'https://www.youtube.com/watch?v=c07IsbSNqfI&feature=youtu.be' vPafy = pafy.new(url) print vPafy.title print vPafy.rating print vPafy.viewcount print vPafy.author print vPafy.length print vPafy.description
Testing file uploads with Postman (multipart/form-data) 4.87096786499 11478 Valentin Despa 1688 ?????? ???? Check my online course on Postman. Get it for only $10 (limited supply): https://www.udemy.com/postman-the-complete-guide/?couponCode=YOUTUBE10 I will show you how to debug an upload script and demonstrate it with a tool that can make requests encoded as "multipart/form-data" so that you can send also a file. After this, we will go even further and write tests and begin automating the process. Here is the Git repository containing the files used for this tutorial: https://github.com/vdespa/postman-testing-file-uploads
要遵循的步驟:
從YouTube獲取視頻URL。
使用Haar級聯的人臉檢測
CNN的性別識別
CNN的年齡識別
1.從YouTube獲取視頻網址:
獲取Youtube視頻URL并嘗試使用pafy獲取視頻的屬性,如上所述。
2. 使用Haar級聯人臉檢測:
這是我們大多數人至少聽說過的一部分。OpenCV/JavaCV提供了直接的方法來導入Haar級聯并使用它們來檢測人臉。我不會深入解釋這一部分。你們可以參考我之前的文章來了解更多關于使用OpenCV進行人臉檢測的信息。
文章地址:https://medium.com/analytics-vidhya/how-to-build-a-face-detection-model-in-python-8dc9cecadfe9
3. CNN的性別識別:
使用OpenCV的fisherfaces實現的性別識別非常流行,你們中的一些人可能也嘗試過或閱讀過它。但是,在這個例子中,我將使用不同的方法來識別性別。2015年,以色列兩名研究人員Gil Levi和Tal Hassner引入了這種方法。我在這個例子中使用了他們訓練的CNN模型。我們將使用OpenCV的dnn包,它代表“深度神經網絡”。
在dnn包中,OpenCV提供了一個名為Net的類,可以用來填充神經網絡。此外,這些軟件包還支持從知名的深度學習框架(如caffe、tensorflow和torch)導入神經網絡模型。我前面提到的研究人員已經將他們的CNN模型發布為caffe模型。因此,我們將使用CaffeImporter將該模型導入到我們的應用程序中。
4. CNN的年齡識別 這與性別識別部分很相似,只是對應的prototxt文件和caffe模型文件是"deploy_agenet.prototxt"和”age_net.caffemodel”. 此外,CNN在該CNN中的輸出層(概率層)由8個年齡層的8個值組成(“0-2”、“4-6”、“8-13”、“15-20”、“25-32”、“38-43”、“48-53”和“60-”)
Caffe模型具有2個相關文件,
1. prototxt: 這里是CNN的定義。這個文件定義了神經網絡的各個層,每個層的輸入、輸出和函數。
2. caffemodel: 包含訓練神經網絡(訓練模型)的信息。
從這里(https://talhassner.github.io/home/publication/2015_CVPR) 下載.prtoxt和.caffemodel。
從這里(https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml) 下載用于人臉檢測的haar級聯。
讓我們開始編碼我們的模型吧。
源代碼:
import cv2
import numpy as np
import pafy
#url of the video to predict Age and gender
url = 'https://www.youtube.com/watch?v=c07IsbSNqfI&feature=youtu.be'
vPafy = pafy.new(url)
play = vPafy.getbest(preftype="mp4")
cap = cv2.VideoCapture(play.url)
cap.set(3, 480) #set width of the frame
cap.set(4, 640) #set height of the frame
MODEL_MEAN_VALUES = (78.4263377603, 87.7689143744, 114.895847746)
age_list = ['(0, 2)', '(4, 6)', '(8, 12)', '(15, 20)', '(25, 32)', '(38, 43)', '(48, 53)', '(60, 100)']
gender_list = ['Male', 'Female']
def load_caffe_models():
age_net = cv2.dnn.readNetFromCaffe('deploy_age.prototxt', 'age_net.caffemodel')
gender_net = cv2.dnn.readNetFromCaffe('deploy_gender.prototxt', 'gender_net.caffemodel')
return(age_net, gender_net)
def video_detector(age_net, gender_net):
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
ret, image = cap.read()
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
if(len(faces)>0):
print("Found {} faces".format(str(len(faces))))
for (x, y, w, h )in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 255, 0), 2)
#Get Face
face_img = image[y:y+h, h:h+w].copy()
blob = cv2.dnn.blobFromImage(face_img, 1, (227, 227), MODEL_MEAN_VALUES, swapRB=False)
#Predict Gender
gender_net.setInput(blob)
gender_preds = gender_net.forward()
gender = gender_list[gender_preds[0].argmax()]
print("Gender : " + gender)
#Predict Age
age_net.setInput(blob)
age_preds = age_net.forward()
age = age_list[age_preds[0].argmax()]
print("Age Range: " + age)
overlay_text = "%s %s" % (gender, age)
cv2.putText(image, overlay_text, (x, y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('frame', image)
#0xFF is a hexadecimal constant which is 11111111 in binary.
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if __name__ == "__main__":
age_net, gender_net = load_caffe_models()
video_detector(age_net, gender_net)現在讓我們一起來理解代碼:
步驟1:導入所有必需的庫。
import cv2 import numpy as np import pafy
步驟2:獲取Youtube視頻URL并創建一個對象“play”,該對象包含webm/mp4格式的視頻的最佳分辨率。
url = 'https://www.youtube.com/watch?v=c07IsbSNqfI&feature=youtu.be' vPafy = pafy.new(url) play = vPafy.getbest(preftype="mp4")
第三步:通常,我們必須用相機捕捉現場的視頻流。OpenCV提供了一個非常簡單的接口。我們可以從相機中捕捉視頻,將其轉換成灰度視頻并顯示出來。只是一個簡單的開始。
要捕獲視頻,需要創建視頻捕獲對象。它的參數可以是設備索引或視頻文件的名稱。設備索引只是指定哪個攝像機的數字。通常會連接一個攝像頭(如我的情況)。所以我只傳遞0(或-1)。可以通過傳遞1等來選擇第二個攝影機。之后,你可以逐幀捕獲。
cap = cv2.VideoCapture(0) #if you are using webcam
但在我的例子中,我正在讀取一個在線視頻URL,為此,我將把“play”對象傳遞給VideoCapture()。
cap = cv2.VideoCapture(play.url)
步驟4:使用set()設置視頻幀的高度和寬度。cap.set(propId, value),這里3是寬度的propertyId,4是高度的propertyId。
cap.set(3, 480) #set width of the frame cap.set(4, 640) #set height of the frame
步驟5:創建3個單獨的列表,用于存儲Model_Mean_值、年齡和性別。
MODEL_MEAN_VALUES = (78.4263377603, 87.7689143744, 114.895847746) age_list = ['(0, 2)', '(4, 6)', '(8, 12)', '(15, 20)', '(25, 32)', '(38, 43)', '(48, 53)', '(60, 100)'] gender_list = ['Male', 'Female']
第六步:我定義了一個函數來加載caffemodel和prototxt的年齡和性別檢測器,這些基本上都是預先訓練好的CNN模型來進行檢測。
def load_caffe_models():
age_net = cv2.dnn.readNetFromCaffe('deploy_age.prototxt', 'age_net.caffemodel')
gender_net = cv2.dnn.readNetFromCaffe('deploy_gender.prototxt', 'gender_net.caffemodel')
return(age_net, gender_net)步驟7:現在我們將執行人臉檢測、年齡檢測和性別檢測,并為此在你的主函數內創建一個函數video_detector(age_net,gender_net),并將age_net和gender_net作為其參數。
if __name__ == "__main__": age_net, gender_net = load_caffe_models() video_detector(age_net, gender_net)
步驟8:讀取步驟3中從VideoCapture()創建的cap對象。 cap.read()返回布爾值(True / False)。如果正確讀取框架,則它將為True。
所以你可以通過檢查這個返回值來檢查視頻的結尾。
有時,cap可能尚未初始化捕獲。在這種情況下,此代碼顯示錯誤。
你可以通過cap.isOpened()方法檢查它是否已初始化. 如果是真的就繼續。否則,請使用cap.open()打開它.
ret, image = cap.read()
步驟9:將圖像轉換為灰度圖像,因為OpenCV人臉檢測器需要灰度圖像。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
步驟10:加載用于人臉檢測的預構建模型。
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')步驟11:現在,我們如何使用級聯分類器從圖像中檢測人臉?
OpenCV的CascadedClassifier再次使其變得簡單,detectMultiScale()可以準確地檢測你需要的內容。
detectMultiScale(image, scaleFactor, minNeighbors)
下面是應該傳遞給detectMultiScale()的參數。
這是一個檢測對象的通用函數,在這種情況下,它將檢測人臉,因為我們在人臉級聯中調用了此函數。如果找到一個人臉,則返回一個所述人臉的位置列表,格式為“Rect(x,y,w,h)”,如果沒有,則返回“None”。
Image:第一個輸入是灰度圖像。
scaleFactor:這個函數補償當一張臉看起來比另一張臉大時發生的大小錯誤感知,因為它更靠近相機。
minNeighbors:一種使用移動窗口檢測對象的檢測算法,它通過定義在當前窗口附近找到多少個對象,然后才能聲明找到的人臉。
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
第12步:循環瀏覽人臉列表并在視頻中的人臉上繪制矩形。在這里,我們基本上是尋找面孔,分解面孔,它們的大小,并繪制矩形。
for (x, y, w, h )in faces: cv2.rectangle(image, (x, y), (x+w, y+h), (255, 255, 0), 2) # Get Face face_img = image[y:y+h, h:h+w].copy()
步驟13:OpenCV提供了一個函數,可以幫助對圖像進行預處理,以便進行深度學習分類:blobFromImage()。它執行:
平均減法 縮放比例 和可選的通道交換
所以blobFromImage4維的blob是從圖像創建的。可選地調整圖像大小并從中心裁剪圖像,減去平均值,按比例因子縮放值,交換藍色和紅色通道
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size, mean, swapRB=True)
image:這是輸入圖像,我們要先對其進行預處理,然后再通過我們的深度神經網絡進行分類。
scale factor: 在我們執行平均值減法之后,我們可以選擇按某個因子縮放圖像。這個值默認為1.0(即沒有縮放),但我們也可以提供另一個值。還要注意的是,比例因子應該是1/σ,因為我們實際上是將輸入通道(在平均值減去之后)乘以比例因子。
size: 這里我們提供卷積神經網絡所期望的空間大小。對于大多數目前最先進的神經網絡來說,這可能是224×224、227×227或299×299。
mean:這些是我們的平均減法值。它們可以是RGB方法的3元組,也可以是單個值,在這種情況下,從圖像的每個通道中減去提供的值。如果要執行平均值減法,請確保按(R,G,B)順序提供3元組,特別是在使用swapRB=True的默認行為時。
swapRB:OpenCV假設圖像是BGR通道順序的;但是,平均值假設我們使用的是RGB順序。為了解決這個差異,我們可以通過將這個值設置為True來交換圖像中的R和B通道。默認情況下,OpenCV為我們執行此通道交換。
blob = cv2.dnn.blobFromImage(face_img, 1, (227, 227), MODEL_MEAN_VALUES, swapRB=False)
第14步:預測性別。
#Predict Gender gender_net.setInput(blob) gender_preds = gender_net.forward() gender = gender_list[gender_preds[0].argmax()]
第15步:預測年齡。
#Predict Age age_net.setInput(blob) age_preds = age_net.forward() age = age_list[age_preds[0].argmax()]
第16步:現在我們必須使用openCV的put text()模塊將文本放到輸出框架上。
putText()的參數如下:
要寫入的文本數據
放置位置坐標(即數據開始的左下角)。
字體類型(請檢查cv2.putText()文檔以獲取支持的字體)
字體比例(指定字體大小)
常規的東西,如顏色,厚度,線型等。為了更好的外觀,線型=cv2.LINE_AA是推薦的。
overlay_text = "%s %s" % (gender, age) cv2.putText(image, overlay_text, (x, y), font, 1, (255, 255, 255), 2, cv2.LINE_AA)
第17步:最后打印你的最終輸出。
cv2.imshow('frame', image)最后我們有:
if cv2.waitKey(1) & 0xFF == ord('q'):
break我們的程序等待用戶按下一個鍵最多1毫秒。然后,它獲取讀取的鍵的值,并將其與0xFF進行比較,0xFF刪除底部8位以上的任何內容,并將結果與字母q的ASCII碼進行比較,這意味著用戶已決定通過按鍵盤上的q鍵退出。
輸出:視頻URL-1:https://www.youtube.com/watch?v=iH1ZJVqJO3Y
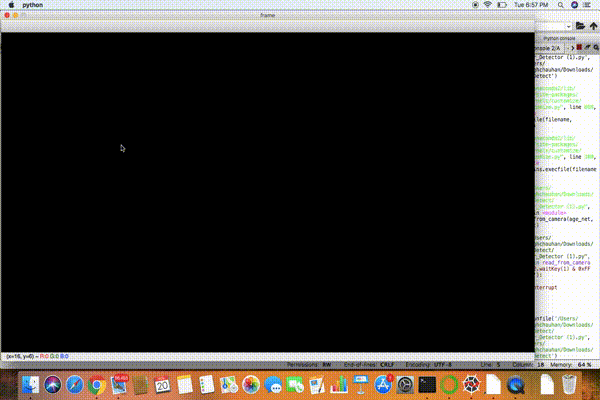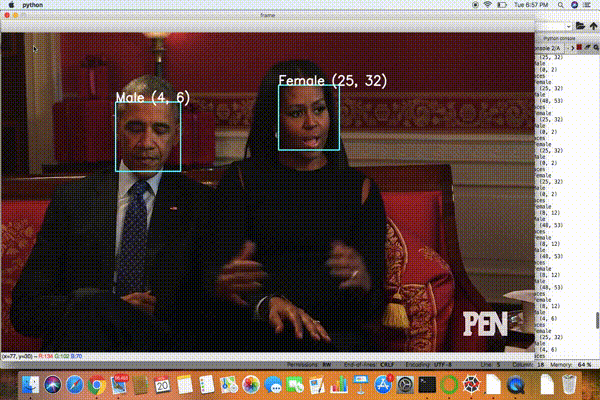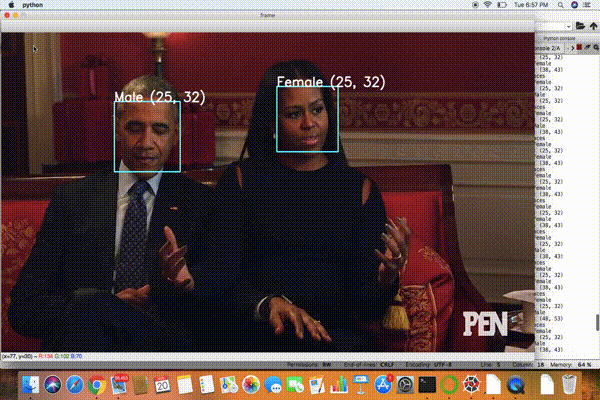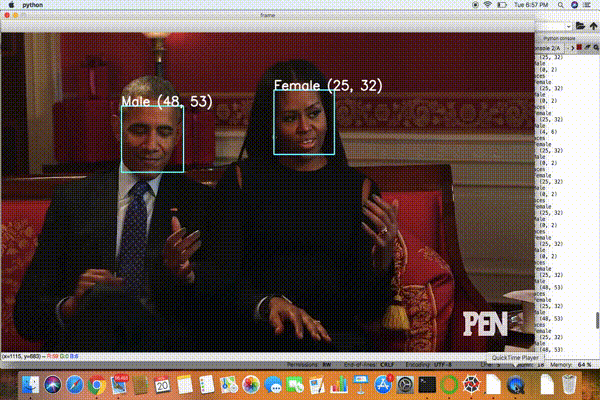
視頻URL-2:https://www.youtube.com/watch?v=qLNhVC296YI
很有趣,不是嗎?但不太準確。
關于怎么使用卷積神經網絡和openCV預測年齡和性別問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





