溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
使用Python怎么對時間序列進行分解和預測?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
什么是時間序列?
顧名思義,時間序列是按照固定時間間隔記錄的數據集。換句話說,以時間為索引的一組數據是一個時間序列。請注意,此處的固定時間間隔(例如每小時,每天,每周,每月,每季度)是至關重要的,意味著時間單位不應改變。別把它與序列中的缺失值混為一談。我們有相應的方法來填充時間序列中的缺失值。
在開始使用時間序列數據預測未來值之前,思考一下我們需要提前多久給出預測是尤其重要的。你是否應該提前一天,一周,六個月或十年來預測(我們用“界限”來表述這個技術術語)?需要進行預測的頻率是什么?在開始預測未來值的詳細工作之前,與將要使用你的預測結果的人談一談也不失為一個好主意。
可視化時間序列數據是數據科學家了解數據模式,時變性,異常值,離群值以及查看不同變量之間的關系所要做的第一件事。從繪圖查看中獲得的分析和見解不僅將有助于建立更好的預測,而且還將引導我們找到最合適的建模方法。這里我們將首先繪制折線圖。折線圖也許是時間序列數據可視化最通用的工具。
這里我們用到的是AirPassengers數據集。該數據集是從1949年到1960年之間的每月航空旅客人數的集合。下面是一個示例數據,以便你對數據信息有個大概了解。
#Reading Time Series Data
Airpassenger = pd.read_csv("AirPassengers.csv")
Airpassenger.head(3)現在,我們使用折線圖繪制數據。在下面的示例中,我們使用set_index()將date列轉換為索引。這樣就會自動在x軸上顯示時間。接下來,我們使用rcParams設置圖形大小,最后使用plot()函數繪制圖表。
Airpassenger = Airpassenger.set_index('date')
pyplot.rcParams["figure.figsize"] = (12,6)
Airpassenger.plot()
pyplot.show()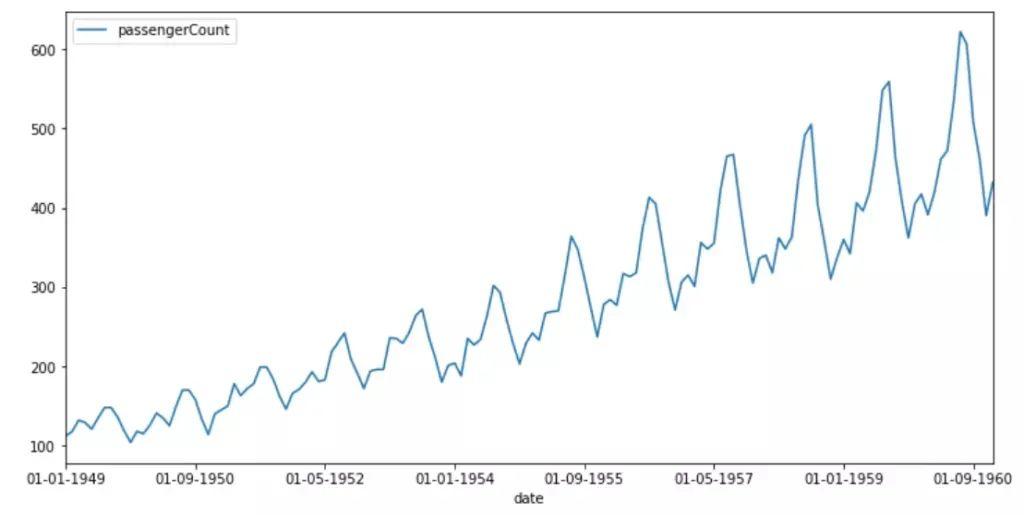
1949-1960年間,乘飛機旅行的乘客人數穩定增長。規律性間隔的峰值表明增長似乎在有規律的時間間隔內重復。
讓我們看看每個季度的趨勢是怎樣的。為了便于理解,從不同的維度觀察信息是個好主意。為此,我們需要使用Python中的datetime包從date變量中得出季度和年份。在進行繪圖之前,我們將連接年份和季度信息,以了解旅客數量在季節維度上如何變化。
from datetime import datetime # Airpassenger["date"] = Airpassenger["date"].apply(lambda x: datetime.strptime(x, "%d-%m-%Y")) Airpassenger["year"] = Airpassenger["date"].apply(lambda x: x.year) Airpassenger["qtr"] = Airpassenger["date"].apply(lambda x: x.quarter) Airpassenger["yearQtr"]=Airpassenger['year'].astype(str)+'_'+Airpassenger['qtr'].astype(str) airPassengerByQtr=Airpassenger[["passengerCount", "yearQtr"]].groupby(["yearQtr"]).sum()
準備好繪制數據后,我們繪制折線圖,并確保將所有時間標簽都放到x軸。x軸的標簽數量非常多,因此我們決定將標簽旋轉呈現。
pyplot.rcParams["figure.figsize"] = (14,6) pyplot.plot(airPassengerByQtr) pyplot.xticks(airPassengerByQtr.index, rotation='vertical')
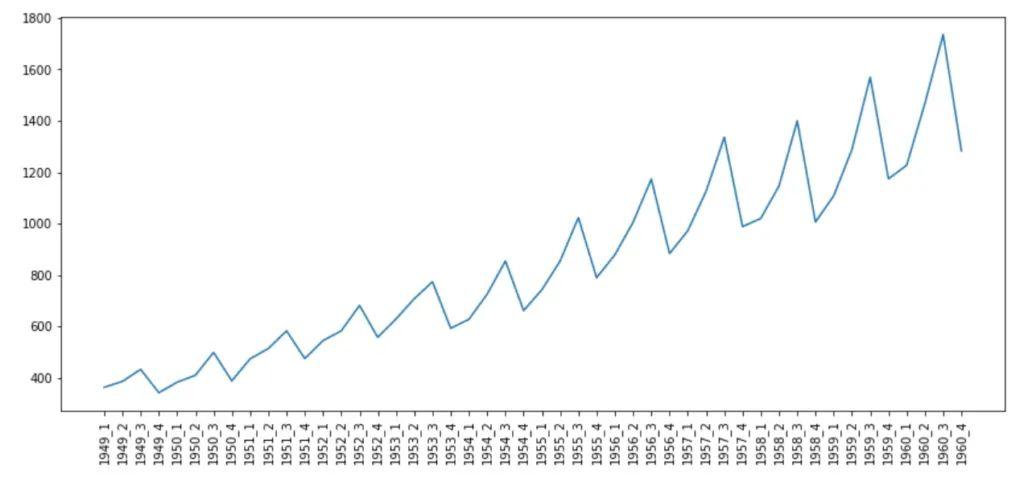
這幅圖非常有趣,它清晰地表明,在1949-1960年之間的所有年份中,航空旅客人數每季度都在顯著增加。
時間序列數據包含4個主要元素:
1.趨勢性–趨勢性表示數據隨時間增加或減少的一般趨勢。這很容易理解。例如,1949年至1960年之間航空旅客數量呈增加趨勢,或者可以說呈上升趨勢。
2.季節性–如同一年四季,數據模式出現在有規律的間隔之后,代表了時間序列的季節性組成部分。它們在特定的時間間隔(例如日,周,月,年等)之后重復。有時我們很容易弄清楚季節性,有時則未必。通常,我們可以繪制圖表并直觀檢驗季節性元素的存在。但是有時,我們可能不得不依靠統計方法來檢驗季節性。
3.周期性–可被視為類似季節性,但唯一的區別是周期性不會定期出現。這個屬性使得它很難被辨識。例如,地震可以在我們知道將要發生的任何時間發生,但是我們其實不知道何時何地發生。
4.隨機噪聲–不屬于上述三類情況的時間序列數據中的突然變化,而且也很難被解釋,因此被稱為隨機波動或隨機噪聲。
有兩種技術可以獲取時間序列要素。在進行深入研究和查看相關Python抽取函數之前,必須了解以下兩點:
時間序列不必具有所有要素。
弄清該時間序列是可加的還是可乘的。
那么什么是可加和可乘時間序列模型呢?
可加性模型–在可加性模型中,要素之間是累加的關系。y(t)=季節+趨勢+周期+噪音
可乘性模型–在可乘性模型中,要素之間是相乘的關系。y(t)=季節趨勢周期*噪音
你想知道為什么我們還要分解時間序列嗎?你看,分解背后的目的之一是估計季節性影響并提供經過季節性調整的值。去除季節性的值就可以輕松查看趨勢。例如,在美國,由于農業領域需求的增加,夏季的失業率有所下降。從經濟學角度來講,這也意味著6月份的失業率與5月份相比有所下降。現在,如果你已經知道了邏輯,這并不代表真實的情況,我們必須調整這一事實,即6月份的失業率始終低于5月份。
這里的挑戰在于,在現實世界中,時間序列可能是可加性和可乘性的組合。這意味著我們可能并不總是能夠將時間序列完全分解為可加的或可乘的。
現在你已經了解了不同的模型,下面讓我們研究一些提取時間序列要素的常用方法。
該方法起源于1920年,是諸多方法的鼻祖。經典分解法有兩種形式:加法和乘法。Python中的statsmodels庫中的函數season_decompose()提供了經典分解法的實現。在經典分解法中,需要你指出時間序列是可加的還是可乘的。你可以在此處(https://otexts.com/fpp2/classical-decomposition.html)了解有關加法和乘法分解的更多信息。
在下面的代碼中,要獲得時間序列的分解,只需賦值model=additive。
import numpy as np from pandas import read_csv import matplotlib.pyplot as plt from statsmodels.tsa.seasonal import seasonal_decompose from pylab import rcParams elecequip = read_csv(r"C:/Users/datas/python/data/elecequip.csv") result = seasonal_decompose(np.array(elecequip), model='multiplicative', freq=4) rcParams['figure.figsize'] = 10, 5 result.plot() pyplot.figure(figsize=(40,10)) pyplot.show()
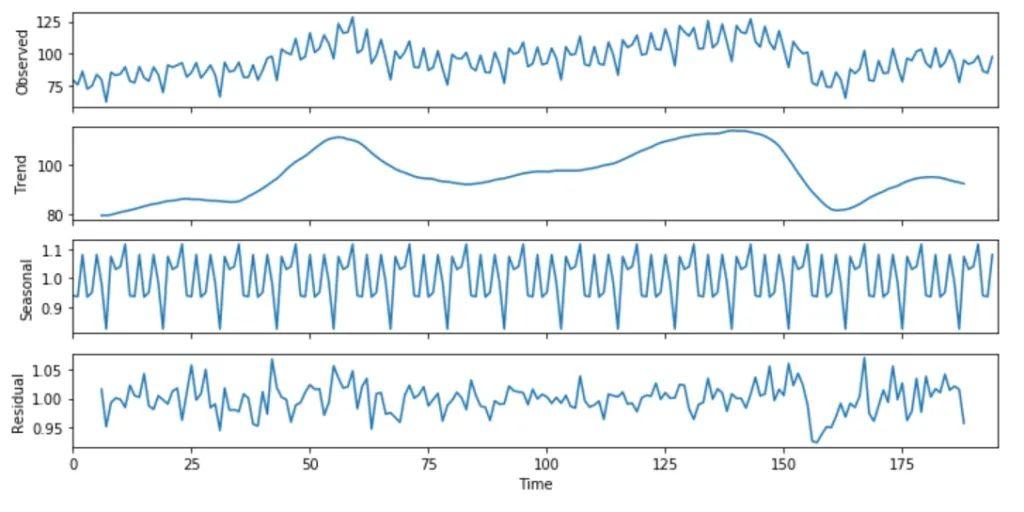
上圖的第一行代表實際數據,底部的三行顯示了三個要素。這三個要素累加之后即可以獲得原始數據。第二個樣本集代表趨勢性,第三個樣本集代表季節性。如果我們考慮完整的時間范圍,你會看到趨勢一直在變化,并且在波動。對于季節性,很明顯,在規律的時間間隔之后可以看到峰值。
對于可加性模型,可以通過y(t)– s(t)獲得季節性調整后的值,對于乘法數據,可以使用y(t)/ s(t)來調整值。
如果你正想問為什么我們需要季節性調整后的數據,讓我們回顧一下剛才討論過的有關美國失業率的示例。因此,如果季節性本身不是我們的主要關注點,那么季節性調整后的數據將更有用。盡管經典方法很常見,但由于以下原因,不太建議使用它們:
該技術對異常值不可靠。
它傾向于使時間序列數據中的突然上升和下降過度平滑。
假設季節性因素每年只重復一次。
對于前幾次和最后幾次觀察,該方法都不會產生趨勢周期估計。
其他可用于分解的更好方法是X11分解,SEAT分解或STL分解。現在,我們將看到如何在Python中生成它們。
與經典法,X11和SEAT分解法相比,STL具有許多優點。接下來,讓我們探討STL分解法。
STL代表使用局部加權回歸(Loess)進行季節性和趨勢性分解。該方法對異常值具有魯棒性,可以處理任何類型的季節性。這個特性還使其成為一種通用的分解方法。使用STL時,你控制的幾件事是:
趨勢周期平滑度
季節性變化率
可以控制對用戶異常值或異常值的魯棒性。這樣你就可以控制離群值對季節性和趨勢性的影響。
同任何其他方法一樣,STL也有其缺點。例如,它不能自動處理日歷的變動。而且,它僅提供對可加性模型的分解。但是你可以得到乘法分解。你可以首先獲取數據日志,然后通過反向傳播要素來獲取結果。但是,這超出了本文討論的范圍。
Import pandas as pd Import seaborn as sns Import matplotlib.pyplot as plt From statsmodels.tsa.seasonal import STL elecequip =read_csv(r"C:/Users/datas/python/data/elecequip.csv") stl = STL(elecequip, period=12, robust=True) res_robust = stl.fit() fig = res_robust.plot()

盡管有許多統計技術可用于預測時間序列數據,我們這里僅介紹可用于有效的時間序列預測的最直接、最簡單的方法。這些方法還將用作其他方法的基礎。
簡單移動平均是可以用來預測的所有技術中最簡單的一種。通過取最后N個值的平均值來計算移動平均值。我們獲得的平均值被視為下一個時期的預測。
移動平均有助于我們快速識別數據趨勢。你可以使用移動平均值確定數據是遵循上升趨勢還是下降趨勢。它可以消除波峰波谷等不規則現象。這種計算移動平均值的方法稱為尾隨移動平均值。在下面的示例中,我們使用rolling()函數來獲取電氣設備銷售數據的移動平均線。
Import pandas as pd from matplotlib import pyplot elecequip = pd.read_csv(r"C:/Users/datas/python/data/elecequip.csv") # Taking moving average of last 6 obs rolling = elecequip.rolling(window=6) rolling_mean = rolling.mean() # plot the two series pyplot.plot(elecequip) pyplot.plot(rolling_mean, color='red') pyplot.show()
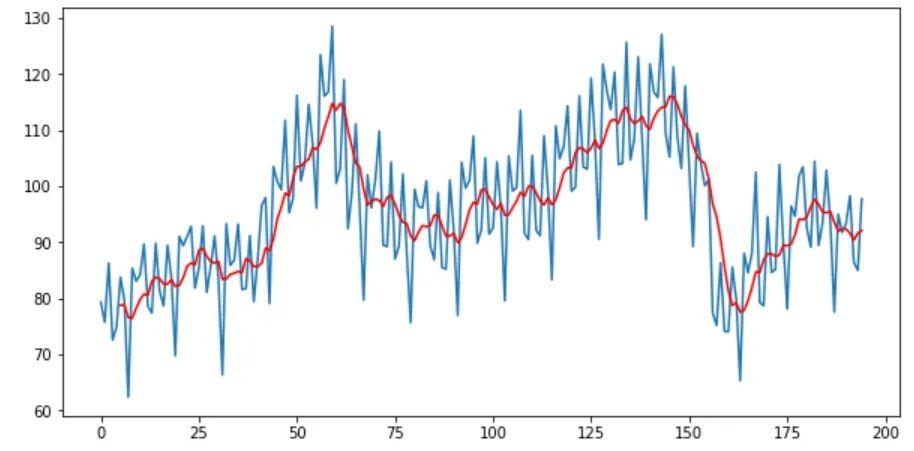
另一種方法是“中心移動平均”。在這里將任意給定時間(t)的值計算為當前,之前和之后的平均值。啟用center = True將提供中心移動平均值。
elecequip["x"].rolling(window=3, center=True).mean()
簡單移動平均非常樸素,因為它對過去的所有值給予同等的權重。但是當假設最新數據與實際值密切相關,則對最新值賦予更多權重可能更有意義。
要計算WMA,我們要做的就是將過去的每個觀察值乘以一定的權重。例如,在6周的滾動窗口中,我們可以將6個權重賦給最近值,將1個權重賦給最后一個值。
import random
rand = [random.randint(1, i) for i in range(100,110)]
data = {}
data["Sales"] = rand
df = pd.DataFrame(data)
weights = np.array([0.5, 0.25, 0.10])
sum_weights = np.sum(weights)
df['WMA']=(df['Sales']
.rolling(window=3, center=True)
.apply(lambda x: np.sum(weights*x)/sum_weights, raw=False)
)
print(df['WMA'])在“指數移動平均”中,隨著觀察值的增加,權重將按指數遞減。該方法通常是一種出色的平滑技術,可以從數據中消除很多噪聲,從而獲得更好的預測。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.api import ExponentialSmoothing
EMA_fit = ExponentialSmoothing(elecequip, seasonal_periods=12, trend='add', seasonal='add').fit(use_boxcox=True)
fcast3 = EMA_fit.forecast(12)
ax = elecequip.plot(figsize=(10,6), marker='o', color='black', title="Forecasts from Exponential Smoothing" )
ax.set_ylabel("Electrical Equipment")
ax.set_xlabel("Index")
# For plotting fitted values
# EMA_fit.fittedvalues.plot(ax=ax, style='--', color='red')
EMA_fit.forecast(12).rename('EMS Forecast').plot(ax=ax, style='--',
marker='o', color='blue', legend=True)該方法具有以下兩種變體:
1.簡單指數平滑–如果時間序列數據是具有恒定方差且沒有季節性的可加性模型,則可以使用簡單指數平滑來進行短期預測。
2.Holt指數平滑法–如果時間序列是趨勢增加或減少且沒有季節性的可加性模型,則可以使用Holt指數平滑法進行短期預測。
以下是從python中的statsmodels包導入兩個模型的代碼。現在,你可以在練習中運行上述模型。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from statsmodels.tsa.api import SimpleExpSmoothing, Holt
關于使用Python怎么對時間序列進行分解和預測問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





