溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解R語言做正態性檢驗的分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
R語言里做做正態性檢驗通常用到的函數是shaporo.test(),這個是叫Shapiro-Wilk(夏皮羅-威爾克)正態性性檢驗。
對應的原假設是 樣本X來自的總體具有正態性分布
比如代碼
> x<-rnorm(100)
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.99187, p-value = 0.8117
p值大于0.05接受原假設
今天一位同學提出 shaporo.test() 這個函數輸出數據的范圍是 3~5000,超出5000該如何做呢? 我自己之前還沒有注意到過樣本量超出5000的情況。
第一個想到的是 在大于5000的樣本里再隨機選一個小于5000的樣本就可以了
示例代碼
x<-rnorm(6000)
x1<-sample(x,3000,replace = F)
shapiro.test(x1)
但這種情況好像不太穩定,我試了一下有時候算出來的p值是小于0.05的。那我們就可以多抽幾次,看p值小于0.05出現次數的多少
還找到一種方法是 直接可視化數據來觀察
可以選密度分布圖和qq圖
參考鏈接是 http://www.sthda.com/english/wiki/normality-test-in-r
示例代碼
x<-rnorm(6000)
library(ggpubr)
p1<-ggdensity(x)
p2<-ggqqplot(x)
library(cowplot)
plot_grid(p1,p2,ncol=2)
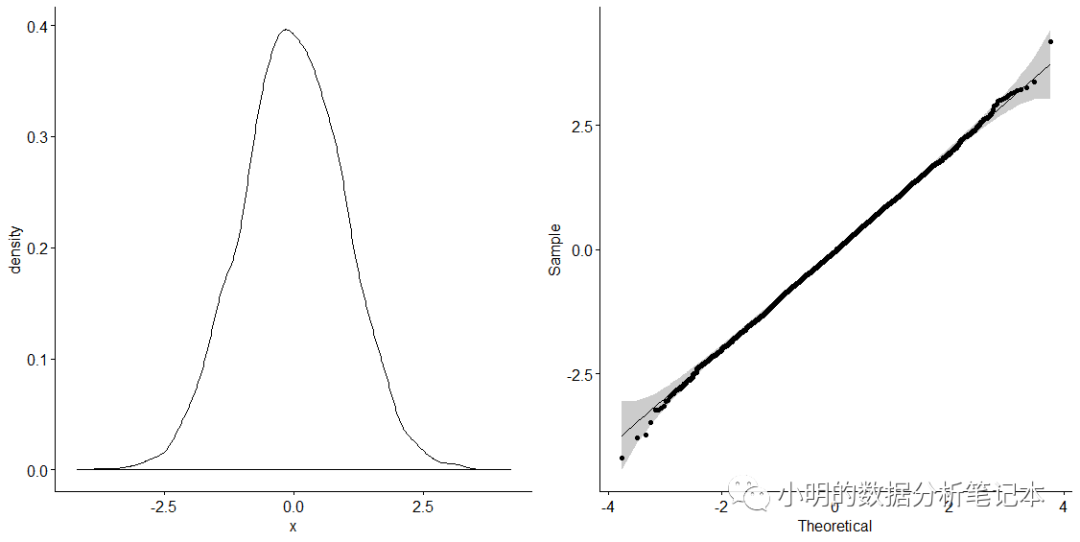
密度分布圖是山形,qq圖所有的點基本都分布在直線的周圍,那就可以判定數據符合正態分布了。
另外還找到一個函數 ad.test()
這個函數對應的R包 nortest
找到這個函數的鏈接是 https://github.com/jamovi/jmv/issues/160
這個函數對應的是 Anderson-Darling test for normality 這個對應的中文名是啥暫時還不知道。
示例代碼
library(nortest)
ad.test(rnorm(100, mean = 5, sd = 3))
Anderson-Darling normality test
data: rnorm(100, mean = 5, sd = 3)
A = 0.3425, p-value = 0.485
這個函數對應的零假設應該也是 樣本來自正態總體
比如試一下
ad.test(1:100)
Anderson-Darling normality test
data: 1:100
A = 1.0837, p-value = 0.007308
很明顯1:100不符合正態分布
這里得到p值小于0.05,拒絕原假設,最終的結論就是數據總體不符合正態分布。
看完上述內容,你們掌握如何理解R語言做正態性檢驗的分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





