溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中怎么實現一個Kmeans均值聚類算法,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
第一步.隨機生成質心
由于這是一個無監督學習的算法,因此我們首先在一個二維的坐標軸下隨機給定一堆點,并隨即給定兩個質心,我們這個算法的目的就是將這一堆點根據它們自身的坐標特征分為兩類,因此選取了兩個質心,什么時候這一堆點能夠根據這兩個質心分為兩堆就對了。如下圖所示: 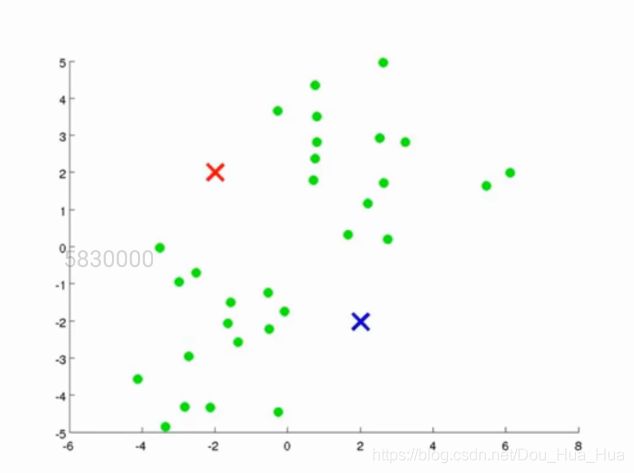
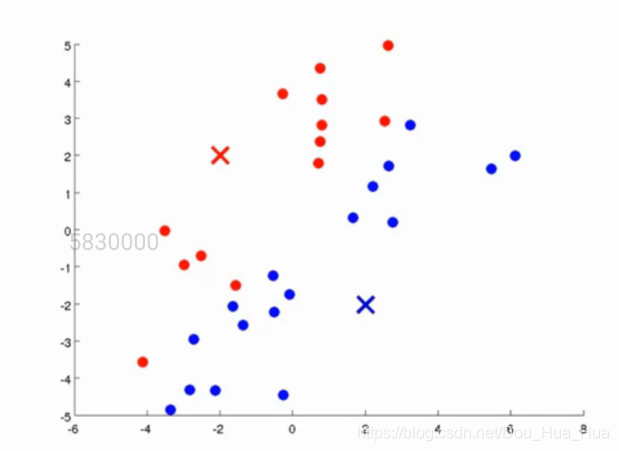
第二步.根據距離進行分類
紅色和藍色的點代表了我們隨機選取的質心。既然我們要讓這一堆點的分為兩堆,且讓分好的每一堆點離其質心最近的話,我們首先先求出每一個點離質心的距離。假如說有一個點離紅色的質心比例藍色的質心更近,那么我們則將這個點歸類為紅色質心這一類,反之則歸于藍色質心這一類,如圖所示:
第三步.求出同一類點的均值,更新質心位置 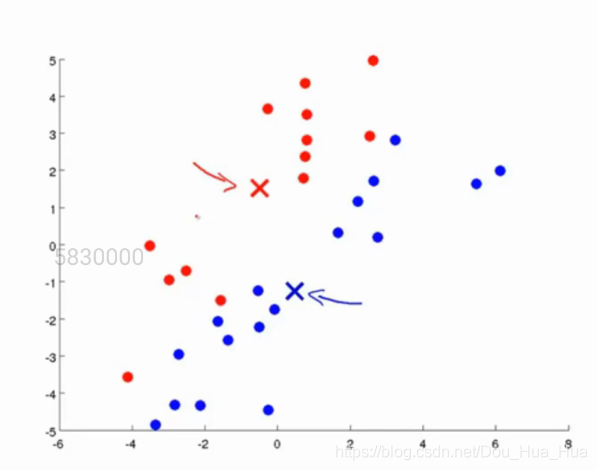
在這一步當中,我們將同一類點的x\y的值進行平均,求出所有點之和的平均值,這個值(x,y)則是我們新的質心的位置,如圖所示:
我們可以看到,質心的位置已經發生了改變。
第四步.重復第二步,第三步
我們重復第二步和第三部的操作,不斷求出點對質心的最小值之后進行分類,分類之后再更新質心的位置,直到得到迭代次數的上限(這個迭代次數是可以我們自己設定的,比如10000次),或者在做了n次迭代之后,最后兩次迭代質心的位置已經保持不變,如下圖所示: 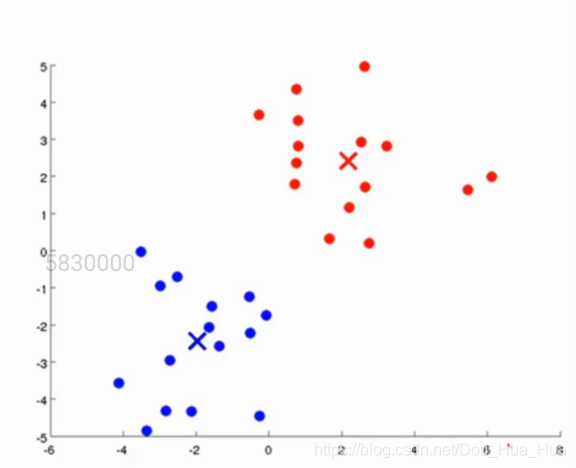
這個時候我們就將這一堆點按照它們的特征在沒有監督的條件下,分成了兩類了!!
五.如果面對多個特征確定的一個點的情況,又該如何實現聚類呢? 首先我們引入一個概念,那就是歐式距離,歐式距離是這樣定義的,很容易理解: 
很顯然,歐式距離d(xi,xj)等于我們每一個點的特征去減去另一個點在該維度下的距離的平方和再開根號,十分容易理解。 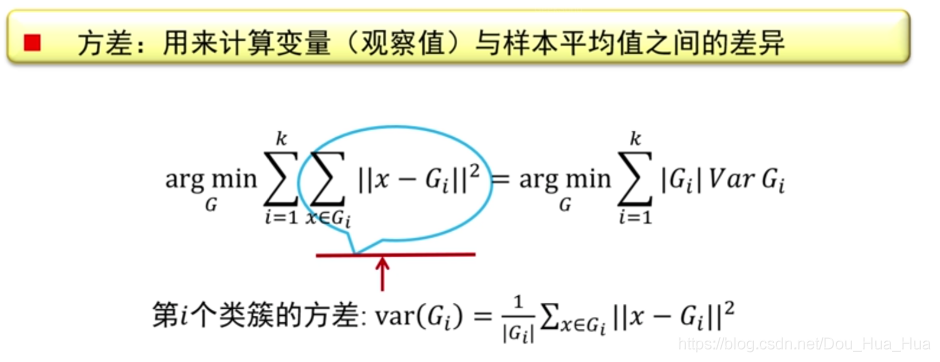
我們也可以用另一種方式來理解kmeans算法,那就是使某一個點的和另一些點的方差做到最小則實現了聚類,如下圖所示:
得解!
六:代碼實現
我們現在使用Python語言來實現這個kmeans均值算法,首先我們先導入一個名叫make_blobs的數據集datasets,然后分別使用兩個變量X,和y進行接收。X表示我們得到的數據,y表示這個數據應該被分類到的是哪一個類別當中,當然在我們實際的數據當中不會告訴我們哪個數據分在了哪一個類別當中,只會有X當中數據。在這里寫代碼的時候比較特殊,make_blobs庫要求我們必須接受這兩個參數,不能夠只接受X這個數據參數,代碼如下
plt.figure(figsize=(15,15))#規定我們繪圖的大小為12*12
X, y=make_blobs(n_samples=1600,random_state=170)#一共取用1600個sample,同時狀態設定為隨機
#不知道這個狀態隨機是什么意思,只能查有關這個庫的官方文檔,同時這個數據集規定了是具備三個數據中心,也就是三個簇
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(X)
plt.subplot(221)#表示四個方格當中的第一格
plt.scatter(X[:,0],X[:,1],c=y_pred)#表示數據的第0個和第1個維度,同時數據的colour與predict的結果有關
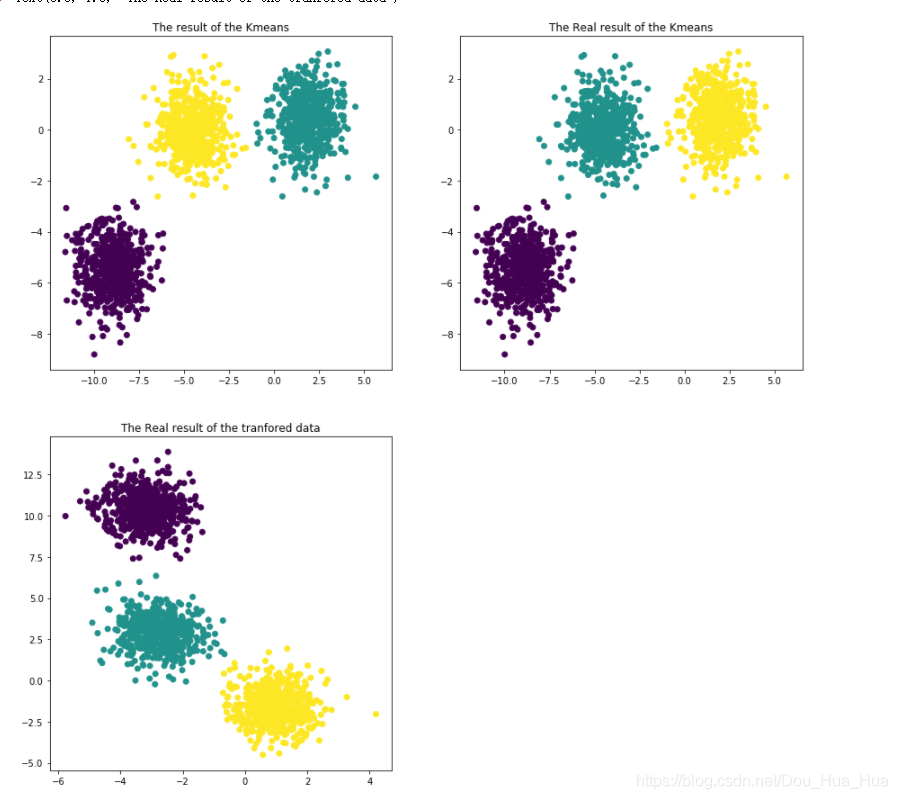
plt.title("The result of the Kmeans")
plt.subplot(222)#表示四個方格當中的第一格
plt.scatter(X[:,0],X[:,1],c=y)
plt.title("The Real result of the Kmeans")
array=np.array([[0.60834549,-0.63667341],[-0.40887178,-0.85253229]])
lashen=np.dot(X,array)
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(lashen)
plt.subplot(223)#表示四個方格當中的第一格
plt.scatter(lashen[:,0],lashen[:,1],c=y_pred)#表示數據的第0個和第1個維度,同時數據的colour與predict的結果有關
plt.title("The Real result of the tranfored data")我們在使用scatter函數進行繪圖的時候會根據我們數據結的形狀來編寫相應的代碼,這里我們所拿到的X數據集的行數是我們所指定的1600行,因為我們一共拿到了1600個數據,每一個數據僅有兩個特征,也就是在XY軸當中的坐標,因此X是一個二維的ndarray對象(X是numpy當中的ndarray對象),我們可以打印出來看看這個數據的構成,如下圖所示:
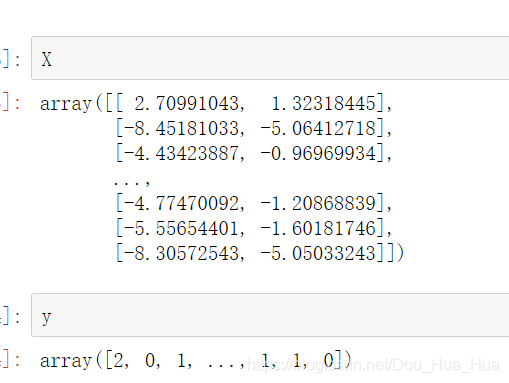
同時我們也可以看到y也是ndarray對象,由于我們在采集數據的時候僅僅接受了3個簇,make_blobs默認接受的是三個簇(或稱cluster)的緣故,因此最后y的值只有0,1,2這三種可能。我們通過matplotlib繪圖,繪制出我們分類的結果圖,也就是上述代碼的運行結果如下:
關于Python中怎么實現一個Kmeans均值聚類算法問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





