溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Pandas函數的應用方式”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Pandas函數的應用方式”吧!
不管是為Pandas對象應用自定義函數,還是應用第三方函數,都離不開以下幾種方法。用哪種方法取決于操作的對象是DataFrame,還是Series;是行、列,還是元素。
1.表現級函數應用:pipe()
2.行列級函數應用:apply()
3.聚合API:agg()與transform()
4.元素級函數應用:applymap()
雖然可以把DataFrame與Series傳遞給函數,不過鏈式調用函數時,最好使用pipe()方法。對比以下兩種方式:

下列代碼與上述代碼是等效的:

Pandas建議使用第二種方式,即鏈式方法。在鏈式方法中調用自定義函數或第三方支持庫函數時,用pipe更容易,與用Pandas自身方法一樣。
上述示例中,f、g與h這幾個函數都把DataFrame當作首位參數。要是想把數據作為第二個參數,我們可以怎么做呢?本例中,pipe為元組(callable,data_keyword)形式。.pipe把DataFrame作為元組里指定的參數。
下面示例用statmodels擬合回歸,該API先接收一個公示,DataFrame是第二個參數,data。要傳遞函數,則要用pipe接收關鍵詞對(sm.ols,’data’)。
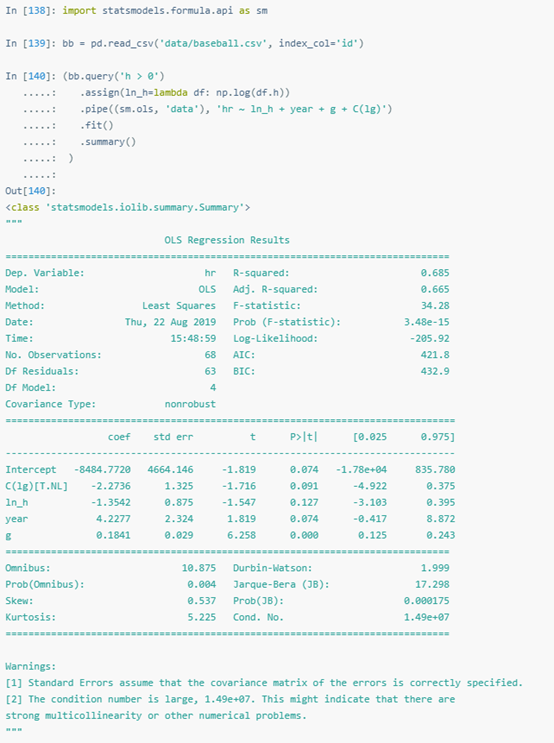
unix的pipe與后來出現的dplyr及magrittr帶動了pipe方法,在此,引入了R語言里用于讀取pipe的操作符(%>%)。pipe的實現思路非常清晰,仿佛跟Python源生的一樣。
apply()方法沿著DataFrame的軸應用函數,比如,描述性統計方法,該方法支持axis參數。

apply()方法還支持通過函數名字符串調用函數。

默認情況下,apply()調用的函數返回的類型會影響DataFrame輸出結構的類型。
函數返回的是Series時,最終輸出結果是DataFrame。輸出的列與函數返回的Series索引相匹配。
函數返回其它任意類型時,輸出結果是Series。
result_type會覆蓋默認行為,該參數有三個選項:reduce、broadcast、expand。
這些選項決定了列表型返回值是否擴展為DataFrame。
我們用好了apply()的話,可以了解數據集的很多信息。比如可以提取每列的最大值對應的日期:
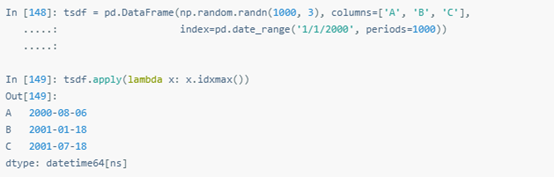
還可以向apply()方法傳遞額外的參數與關鍵字參數。比如下面示例中要應用的這個函數:

可以用以下方式應用該函數:

為每行或每例執行Series方法的功能也非常的實用:

apply()有一個參數raw,默認值為False,再應用函數前,使用該參數可以將每行或列轉換為Series。該參數為True時,傳遞的函數接收ndarray對象,若不需要索引功能,這樣操作能夠顯著的提高性能。
聚合API可以快速、簡潔地執行多個聚合操作。Pandas對象支持多個類似地API,如groupby API、window functions API、resample API。聚合函數為DataFrame.aggregate(),也可以叫做Dataframe.agg()。
在這里我們用與上例類似的DataFrame:
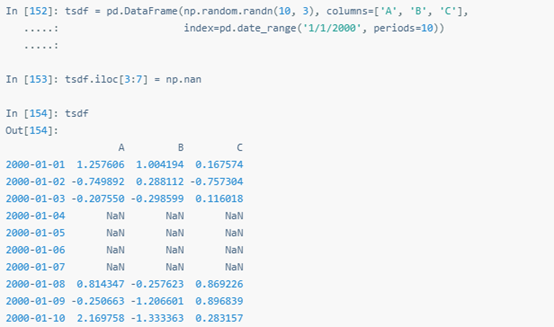
應用單個函數時,該操作與apply()等效,這里也可以用字符串表示聚合函數名。下面的聚合函數輸出的結果為Series:

Series單個聚合操作返回標量值:

還可以用列表形式傳遞多個聚合函數。每個函數在輸出結果DataFrame里以行的形式顯示,行名是每個聚合函數的函數名。

多個函數輸出多行:

Series聚合多函數返回結果還是Series,索引為函數名:

傳遞lambda函數時,輸出名為<lambda>的行:

應用自定義函數時,該函數名為輸出結果的行名:

指定為哪些列應用哪些聚合函數時,需要把包含列名與標量(或標量列表)的字典傳遞給DataFrame.agg。
但我們要注意,這里輸出結果的順序不是固定的,要想讓輸出順序與輸入順序一致,我們可以使用OrderedDict。

輸出的參數是列表時,輸出的結果為DataFrame,并以矩陣形式顯示所有聚合函數的計算結果,且輸出結果有所有唯一函數組成。未執行聚合操作的列輸出結果為NaN值:

與groupby的.agg操作類似,DataFrame含不能執行聚合的數據類型時,.agg只計算可聚合的列:


.agg()可以創建類似于內置describe函數的自定義describe函數。
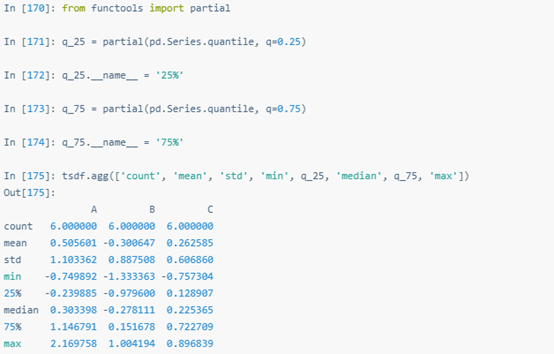
transform方法的返回結果與原始數據的索引相同,大小相同。與.agg API類似,該API支持同時處理多種操作,不用一個一個操作。
首先,創建一個DataFrame:
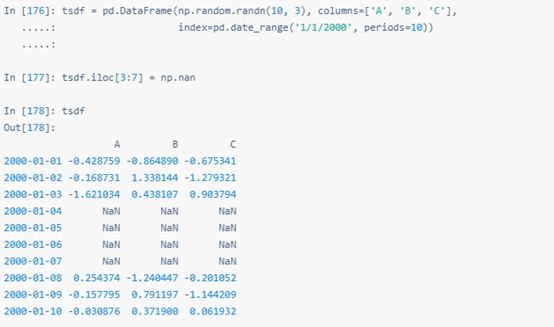
這里轉換的是整個DataFrame。.transform()支持NumPy函數、字符串函數及自定義函數。

這里的transform()接收單個函數;與ufunc等效。
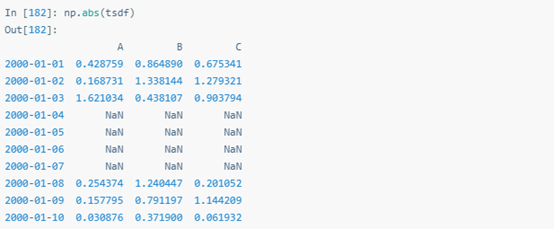
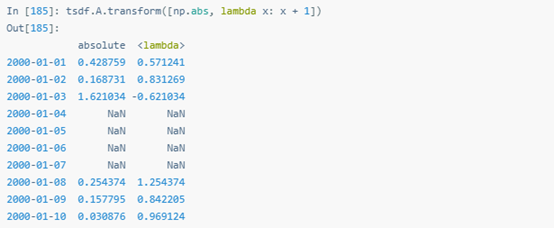
.transform向Series傳遞單個函數時,返回的結果也是單個Series。
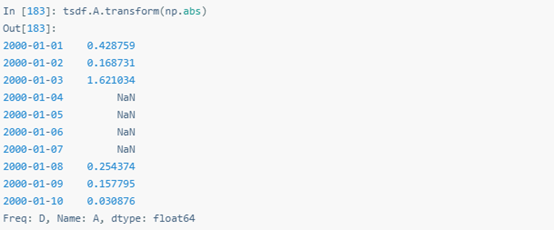
transform()調用多個函數時,生成多層索引DataFrame。第一層是原始數據集的列名;第二層是transform()調用的函數名。
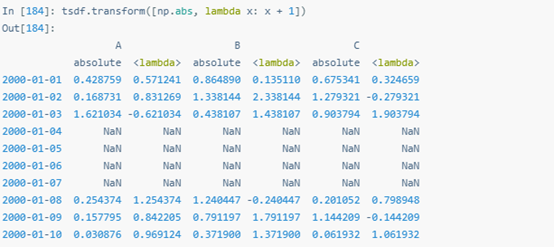
為Series應用多個函數時,輸出結果是DataFrame,列名是transform()調用的函數名。
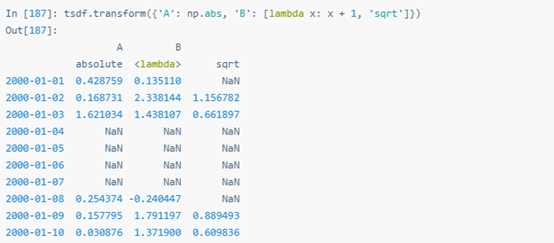
函數字典可以為每列執行指定transform()操作。

transform()的參數是列表字典時,生成的是以transform()調用的函數名為多層索引的DataFrame。
并非所有函數都能矢量化,即接受NumPy數組,返回另一個數組或值,DataFrame的applymap()及Series的map(),支持任何接收單個值并返回單個值的Python函數。

Series.map()還有個功能,可以“連接”或“映射”第二個Series定義的值。這與merging/joining功能聯系非常緊密:

到此,相信大家對“Pandas函數的應用方式”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





