溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“高效的Pandas函數有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
介紹這些函數之前,第一步先要導入pandas和numpy。
import numpy as np import pandas as pd
1. Query
Query是pandas的過濾查詢函數,使用布爾表達式來查詢DataFrame的列,就是說按照列的規則進行過濾操作。
用法:
pandas.DataFrame.query(self, expr, inplace = False, **kwargs)
參數作用:
expr:要評估的查詢字符串;
inplace=False:查詢是應該修改數據還是返回修改后的副本
kwargs:dict關鍵字參數
首先生成一段df:
values_1 = np.random.randint(10, size=10) values_2 = np.random.randint(10, size=10) years = np.arange(2010,2020) groups = ['A','A','B','A','B','B','C','A','C','C'] df = pd.DataFrame({'group':groups, 'year':years, 'value_1':values_1, 'value_2':values_2}) df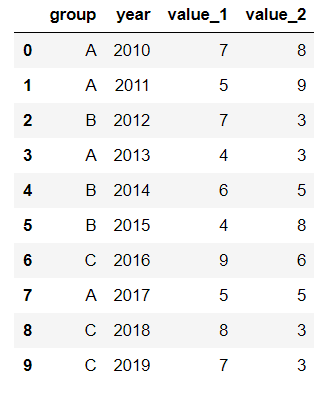
過濾查詢用起來比較簡單,比如要查列value_1<value_2的行記錄:
df.query('value_1 < value_2')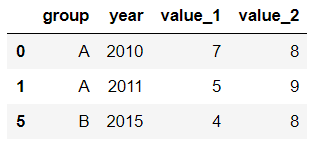
查詢列year>=2016的行記錄:
df.query('year >= 2016 ')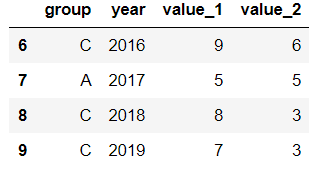
2. Insert
Insert用于在DataFrame的指定位置中插入新的數據列。默認情況下新列是添加到末尾的,但可以更改位置參數,將新列添加到任何位置。
用法:
Dataframe.insert(loc, column, value, allow_duplicates=False)
參數作用:
loc:int型,表示插入位置在第幾列;若在第一列插入數據,則 loc=0
column:給插入的列取名,如 column='新的一列'
value:新列的值,數字、array、series等都可以
allow_duplicates:是否允許列名重復,選擇Ture表示允許新的列名與已存在的列名重復
接著用前面的df:
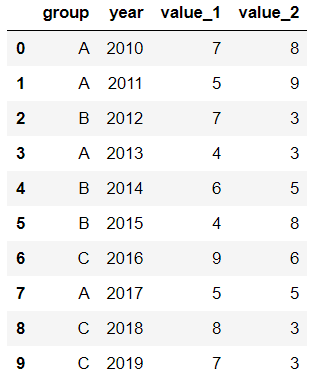
在第三列的位置插入新列:
#新列的值 new_col = np.random.randn(10) #在第三列位置插入新列,從0開始計算 df.insert(2, 'new_col', new_col) df
3. Cumsum
Cumsum是pandas的累加函數,用來求列的累加值。
用法:
DataFrame.cumsum(axis=None, skipna=True, args, kwargs)
參數作用:
axis:index或者軸的名字
skipna:排除NA/null值
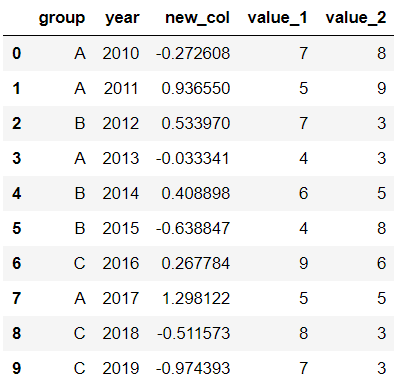
以前面的df為例,group列有A、B、C三組,year列有多個年份。我們只知道當年度的值value_1、value_2,現在求group分組下的累計值,比如A、2014之前的累計值,可以用cumsum函數來實現。
當然僅用cumsum函數沒辦法對groups (A, B, C)進行區分,所以需要結合分組函數groupby分別對(A, B, C)進行值的累加。
df['cumsum_2'] = df[['value_2','group']].groupby('group').cumsum() df
4. Sample
Sample用于從DataFrame中隨機選取若干個行或列。
用法:
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
參數作用:
(1) n:要抽取的行數
(2) frac:抽取行的比例
例如frac=0.8,就是抽取其中80%
(3) replace:是否為有放回抽樣,
True:有放回抽樣
False:未放回抽樣
(4) weights:字符索引或概率數組
(5) random_state :隨機數發生器種子
(6) axis:選擇抽取數據的行還是列
axis=0:抽取行
axis=1:抽取列
比如要從df中隨機抽取5行:
sample1 = df.sample(n=5) sample1

從df隨機抽取60%的行,并且設置隨機數種子,每次能抽取到一樣的樣本:
sample2 = df.sample(frac=0.6,random_state=2) sample2

5. Where
Where用來根據條件替換行或列中的值。如果滿足條件,保持原來的值,不滿足條件則替換為其他值。默認替換為NaN,也可以指定特殊值。
用法:
DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False, raise_on_error=None)
參數作用:
cond:布爾條件,如果 cond 為真,保持原來的值,否則替換為other
other:替換的特殊值
inplace:inplace為真則在原數據上操作,為False則在原數據的copy上操作
axis:行或列
將df中列value_1里小于5的值替換為0:
df['value_1'].where(df['value_1'] > 5 , 0)

Where是一種掩碼操作。
掩碼(英語:Mask)在計算機學科及數字邏輯中指的是一串二進制數字,通過與目標數字的按位操作,達到屏蔽指定位而實現需求。
6. Isin
Isin也是一種過濾方法,用于查看某列中是否包含某個字符串,返回值為布爾Series,來表明每一行的情況。
用法:
Series.isin(values) 或者 DataFrame.isin(values)
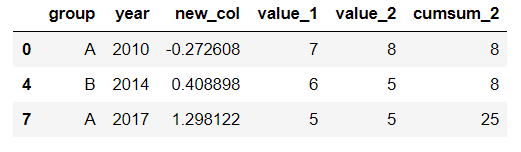
篩選df中year列值在['2010','2014','2017']里的行:
years = ['2010','2014','2017'] df[df.year.isin(years)]
7. Loc and iloc
Loc和iloc通常被用來選擇行和列,它們的功能相似,但用法是有區別的。
用法:
years = ['2010','2014','2017'] df[df.year.isin(years)]
loc:按標簽(column和index)選擇行和列
iloc:按索引位置選擇行和列
選擇df第1~3行、第1~2列的數據,使用iloc:
df.iloc[:3,:2]
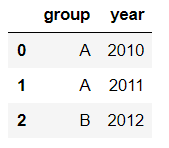
使用loc:
df.loc[:2,['group','year']]1
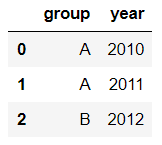
提示:使用loc時,索引是指index值,包括上邊界。iloc索引是指行的位置,不包括上邊界。
選擇第1、3、5行,year和value_1列:
df.loc[[1,3,5],['year','value_1']]
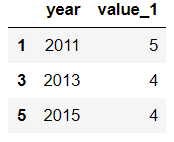
8. Pct_change
Pct_change是一個統計函數,用于表示當前元素與前面元素的相差百分比,兩元素的區間可以調整。
比如說給定三個元素[2,3,6],計算相差百分比后得到[NaN, 0.5, 1.0],從第一個元素到第二個元素增加50%,從第二個元素到第三個元素增加100%。
用法:
DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)
參數作用:
periods:間隔區間,即步長
fill_method:處理空值的方法
對df的value_1列進行增長率的計算:
df.value_1.pct_change()

9. Rank
Rank是一個排名函數,按照規則(從大到小,從小到大)給原序列的值進行排名,返回的是排名后的名次。
比如有一個序列[1,7,5,3],使用rank從小到大排名后,返回[1,4,3,2],這就是前面那個序列每個值的排名位置。
用法:
rank(axis=0, method: str = 'average', numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False)
參數作用:
(1) axis:行或者列
(2) method:返回名次的方式,可選{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}
method=average 默認設置: 相同的值占據前兩名,分不出誰是1誰是2,那么去中值即1.5,下面一名為第三名
method=max: 兩人并列第 2 名,下一個人是第 3 名
method=min: 兩人并列第 1 名,下一個人是第 3 名
method=dense: 兩人并列第1名,下一個人是第 2 名
method=first: 相同值會按照其在序列中的相對位置定值
(3) ascending:正序和倒序
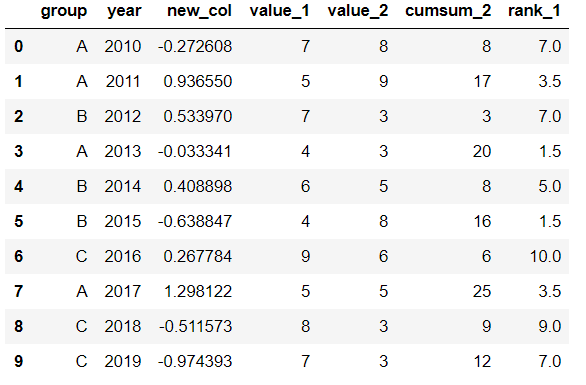
對df中列value_1進行排名:
df['rank_1'] = df['value_1'].rank() df
10. Melt
Melt用于將寬表變成窄表,是 pivot透視逆轉操作函數,將列名轉換為列數據(columns name → column values),重構DataFrame。
簡單說就是將指定的列放到鋪開放到行上變成兩列,類別是variable(可指定)列,值是value(可指定)列。

用法:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
參數作用:
frame:它是指DataFrame
id_vars [元組, 列表或ndarray, 可選]:不需要被轉換的列名,引用用作標識符變量的列
value_vars [元組, 列表或ndarray, 可選]:引用要取消透視的列。如果未指定, 請使用未設置為id_vars的所有列
var_name [scalar]:指代用于”變量”列的名稱。如果為None, 則使用- - frame.columns.name或’variable’
value_name [標量, 默認為’value’]:是指用于” value”列的名稱
col_level [int或string, 可選]:如果列為MultiIndex, 它將使用此級別來融化
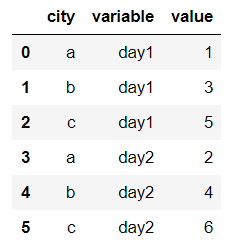
例如有一串數據,表示不同城市和每天的人口流動:
import pandas as pd df1 = pd.DataFrame({'city': {0: 'a', 1: 'b', 2: 'c'}, 'day1': {0: 1, 1: 3, 2: 5}, 'day2': {0: 2, 1: 4, 2: 6}}) df1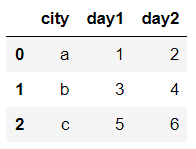
現在將day1、day2列變成變量列,再加一個值列:
pd.melt(df1, id_vars=['city'])
“高效的Pandas函數有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





