溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么理解ConcurrentHashMap”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么理解ConcurrentHashMap”吧!
HashMap雖然很高效,使用起來也很方便,但很遺憾它卻不是線程安全的(比如各種++操作就不是線程安全的),閱讀源碼可知道HashMap并沒有對并發做控制。但是無妨,Doug Lea大神為我們提供了ConcurrentHashMap這個工具類,一個并發版本的HashMap。相比于Hashtable只是簡單地在方法上加上synchronized關鍵字來控制并發(所有方法共用一個鎖資源,同一時刻只能有一個線程在調用),ConcurrentHashMap做到了真正的并發調用。
和HashMap一樣,ConcurrentHashMap在Java 7和Java 8中也發生了變化:在Java 7中是使用了一個繼承ReentrantLock的分段鎖Segment來實現并發的(我之前也寫過對ReentrantLock進行源碼分析的文章AQS源碼深入分析之獨占模式-ReentrantLock鎖特性詳解),每個Segment里面保存著一個類似于HashMap的結構(HashEntry)。所以說一個Segment里面的操作和另一個Segment里面是互不干擾的,同時也就是在說ConcurrentHashMap的并發程度取決于Segment的數量(默認為16)。但是這樣使用起來未免還是覺得并發粒度太粗了,所以在Java 8中做了改進。
Java 8中的ConcurrentHashMap完全摒棄了之前的數據結構,而是采用了和HashMap一樣數組+鏈表+紅黑樹的結構,整體變得更加輕便。并發控制是通過**CAS + synchronized + Unsafe類直接操作地址(volatile語義)**的方式來實現,而且并發粒度也縮減到了桶上(即并發粒度是數組的長度。注意,說并發粒度是在Node節點上的這個說法是錯誤的。因為不可能存在一個線程修改鏈表上的一個節點,而另外一個線程同時修改這個鏈表上的另一個節點。源碼中鎖住了鏈表上的第一個節點,這只是表面上的含義,真正的含義是鎖住整個桶(鏈表))。其源碼結構也是和HashMap類似的,只不過是在一些會出現并發問題的關鍵代碼處改為了對并發的支持(在多線程計數和利用多線程來做擴容這兩個方法中做了較大的改動)。兩者結構類似也更方便我們來查看二者在實現并發上的差異,學習大師是如何處理并發的。所以從某種意義上來說,Java 8中的ConcurrentHashMap是對HashMap在并發方面所做的改進版本。但是這并不意味著取代,因為在一些不需要考慮并發的場景中(比如局部變量),HashMap比ConcurrentHashMap有著更高的性能(CAS和synchronized多多少少會有點兒開銷,而且還有其他需要考慮并發的代碼)。
ReentrantLock源碼也是Doug Lea寫的。ConcurrentHashMap源碼從Java 7中用ReentrantLock(Segment)來實現并發控制,到Java 8中改用CAS + synchronized + Unsafe類直接操作地址(volatile語義)的方式,可以看出在Java 8這個版本中synchronized的性能已經優化地很好了(偏向鎖+輕量級鎖+重量級鎖)。其實synchronized可以不斷地去優化它的性能,因為它是屬于底層的實現。而ReentrantLock繼承于AQS,還是屬于代碼層次上的阻塞與喚醒(依賴于底層操作系統的線程庫),優化幅度不高。
還有一點需要提的是:在HashMap中是允許key和value為null的,而在ConcurrentHashMap中則是不允許的,會拋出空指針異常。這是為什么呢?首先來說明一下value不能為null的原因。其實我在分析HashMap中的get方法中就已經說過,通過get方法來獲取鍵所對應的值,結果為null的話是具有二義性的。我分不清到底是因為存進去的就是map.put("key", null);,還是這個鍵值對本身就在HashMap中不存在,從而返回的null。但是在HashMap中,我可以通過containsKey方法來查看到底是屬于上面哪種情況,因為HashMap本身就是假定在單線程中能正確執行,所以這樣來做不會有問題。但是在ConcurrentHashMap中,假如說也是允許value為null的話,那么我也按照上面的方式來進行判斷,可能會寫出下面的代碼:
1 if (map.containsKey("key")) {
2 return map.get("key");
3 } else {
4 //做一些其他的處理,比如說拋出一個沒有key的異常
5 }假定當前ConcurrentHashMap中就有一個"key"->null的鍵值對。而就在第一個線程執行完containsKey方法,返回true,而此時準備要執行get方法的時候,第二個線程將這個鍵值對刪掉了,此時第一個線程get方法返回null就產生了二義性:我以為是當前有"key"->null這個鍵值對,get方法才返回的null,而實際上是因為這個鍵值對已經被刪掉了才返回的null。
再來說說key不能為null的原因。其實說實話,我沒能找到一種場景下能很好地解釋出key不能為null的原因(就如同上面解釋value不能為null那樣),而下面是Doug Lea對于這個問題的解釋:

他也只是解釋了value不能為null的原因(就如同上面我說的那樣),但是在倒數第二段中,他說到了一點就是檢查key和value是null,這個是很困難的。其實看完他說的這段話,我有理由相信,key不能為null就是Doug Lea提前設定好的代碼規范(既然你value已經不能為null了,key也別為null了),以此來避免沒必要出現的麻煩(二義性或其他)。上面還說到了Doug Lea認為HashMap中的key和value也不能為null,同時給出了一種在多線程使用HashMap時,用一種包裝NULL為空對象的方式,以此來區分出這兩種差異(用Java 8中的Optional類應該也能做到)。有意思的是,這和Josh Bloch(另一位Java界大佬,HashMap的主要作者之一(Doug Lea也是)。可以認為HashMap主要是Josh Bloch寫的,而ConcurrentHashMap是Doug Lea寫的)之前的想法是相左的,但是后來,Josh Bloch似乎改口了:


他同意了key為null可能會造成錯誤,但不確定value是否應該不能為null。并且認為如果在Java源碼中加入這種包裝NULL空對象的方式是需要慎重考慮的。這些問答發布于06年,但直到如今的Java 8u261,我在源碼中還是沒有找到類似的修改點。但不管怎樣,我們知道有這么回事兒就行了。
1 /**
2 * ConcurrentHashMap:
3 * 無參構造器
4 * 空實現,所有參數都是走默認的
5 */
6 public ConcurrentHashMap() {
7 }
8
9 /**
10 * 有參構造器
11 */
12 public ConcurrentHashMap(int initialCapacity) {
13 //initialCapacity非負校驗
14 if (initialCapacity < 0)
15 throw new IllegalArgumentException();
16 /*
17 與HashMap不同的是,這里initialCapacity如果大于等于2的29次方的時候(HashMap這里為超過2的30次方),
18 就重置為2的30次方
19
20 tableSizeFor方法是用來求出大于等于指定值的最小2次冪的(我在HashMap源碼分析中詳細解釋了該方法的執行過程),
21 有意思的是,注意在第26行代碼處,在HashMap中僅僅就是對設定的數組容量取最小2次冪,而這里首先對設定值*1.5+1后,
22 再取最小2次冪,后面會解釋為什么會這么做
23 */
24 int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
25 MAXIMUM_CAPACITY :
26 tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
27 /*
28 sizeCtl是用來記錄當前數組的狀態的(類似于HashMap中的threshold):
29 1.如果為-1,代表當前數組正在被初始化
30 2.如果為其他負數,代表當前數組正在被擴容。取該負數的低16位,即(1 + n),n代表正在執行擴容操作的線程數量
31 (這里+1是為了錯開-1這個值)
32 3.在調用有參構造器的時候存放的是需要初始化的容量
33 4.調用無參構造器的時候為0
34 5.當前數組已經不為空,此時存放的是下次需要擴容時的閾值
35 */
36 this.sizeCtl = cap;
37 }在上面的第26行代碼處,首先會對設定值1.5+1后(+1是對應1.5后如果結果有小數的情況。因為最后是要取整的(傳進tableSizeFor方法中的參數必須是int),也就是將所有小數部分都截掉,所以+1是為了彌補這種差異),然后再取最小2次冪,這和HashMap中的實現有所不同(HashMap中是tableSizeFor(initialCapacity)),那么這到底是為什么呢?其實傳進來的容量實際上并不是存進去的桶的個數,而是需要擴容時的個數**。**舉個例子就明白了:16 * 0.75 = 12,在HashMap中,我們傳進來的其實是16,需要乘負載因子后才是實際需要擴容時的閾值點;而在ConcurrentHashMap中,傳進來的值其實相當于12,也就是說我們傳進來的就是需要擴容的閾值。所以在構造器階段需要除以負載因子,以此來求出真正的桶的個數。所以在上面的第26行代碼處,實際上就是在做自適應容量的工作。那么可能又會在想:不對啊,即使是在做自適應,那也應該是數組容量 / 默認值的0.75啊?1.5是什么鬼?我猜測可能是為了提高執行速度,其實/0.75就相當于1.333333...,這樣和1.5來對比的話似乎差別也不太大,但是/0.75的方式畢竟是除法,又帶小數,而1.5可以優化為右移操作。但是這么做的話可能會使計算出的結果導向為另一個不同的值,下面來舉個例子:比方說現在傳進來的容量是22,那么/ 0.75的方式結果是29.3,+1后再tableSizeFor結果是:32;而*1.5的方式結果是33,+1后再tableSizeFor結果是:64。可以看到,*1.5方式最后計算出來的容量明顯是不對的,相當于多擴容了一倍(負載因子相當于默認的0.75,所以22 / 0.75后+1再取2的冪,結果肯定是32而不是64)。而實際上的結果也確實如此,這里實際上是個bug。在OpenJDK的bug提交記錄上可以看到如下的JDK-8202422:
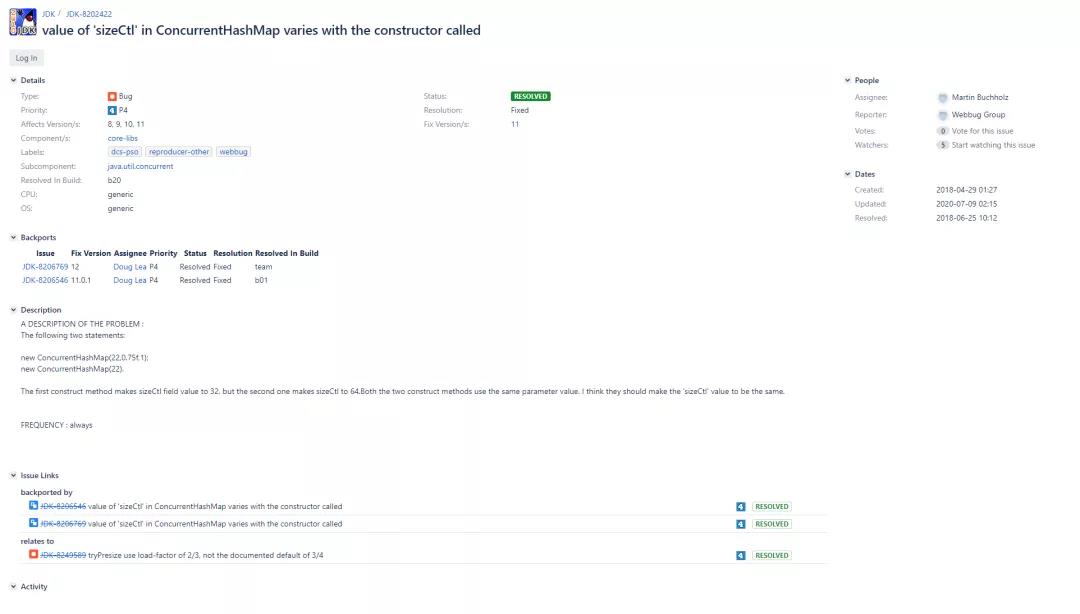
從上面可以抓取到幾個信息:這個bug從Java 8開始就已經有了,已經在Java 11.0.1中修復了。既然如此,我們就來看看這塊改成了什么。以下是Java 14.0.2中的ConcurrentHashMap單參數構造器的源碼:
1 public ConcurrentHashMap(int initialCapacity) {
2 this(initialCapacity, LOAD_FACTOR, 1);
3 }
4
5 public ConcurrentHashMap(int initialCapacity,
6 float loadFactor, int concurrencyLevel) {
7 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
8 throw new IllegalArgumentException();
9 if (initialCapacity < concurrencyLevel) // Use at least as many bins
10 initialCapacity = concurrencyLevel; // as estimated threads
11 long size = (long) (1.0 + (long) initialCapacity / loadFactor);
12 int cap = (size >= (long) MAXIMUM_CAPACITY) ?
13 MAXIMUM_CAPACITY : tableSizeFor((int) size);
14 this.sizeCtl = cap;
15 }可以看到在第11行代碼處,已經改為了initialCapacity / loadFactor的方式,解決了這個bug點(Java 8中沒有修復這個bug其實也無妨,畢竟多擴容一倍少擴容一倍并不是什么嚴重的邏輯bug)。
至于為什么要這么做?為什么要和HashMap的實現有所差異?我覺得是因為要淡化自定義負載因子的功能。如果細心的話可以看到,在ConcurrentHashMap的源碼中,this.loadFactor的使用幾乎沒有(僅有的一次使用也是遺留代碼),似乎Doug Lea已經不建議我們來自己修改負載因子的值了。雖然仍然可以在構造器階段傳入自定義的loadFactor(向后兼容),但是也僅僅是在該構造器內部中才會有所影響,在后續的初始化以及擴容階段使用的還是默認的0.75(后面會看到這點),所以說如果傳入的自定義負載因子不是0.75的話就顯得很雞肋了。在源碼中對此也有所注釋:
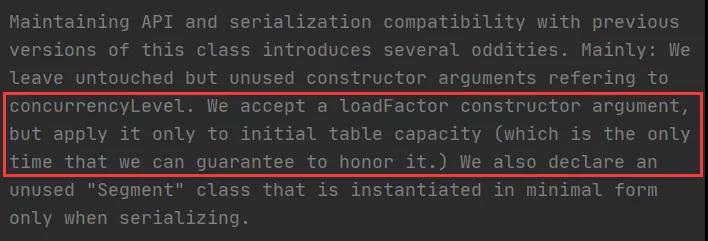
還有一點需要明確:sizeCtl在為負數表示擴容的時候(不包括-1),嚴格的定義為取該負數的低16位,即(1 + n),n代表正在執行擴容操作的線程數量(這里+1是為了錯開-1這個值)。低16位表示的才是擴容線程數量+1,而高16位為一個生成數組長度所對應的標志位(詳見后面的示意圖)。而在源碼中的注釋是這樣寫的:

可以看到并不準確。
1 /**
2 * ConcurrentHashMap:
3 */
4 public V put(K key, V value) {
5 return putVal(key, value, false);
6 }
7
8 final V putVal(K key, V value, boolean onlyIfAbsent) {
9 //注意,ConcurrentHashMap中的key和value是不允許為null的,但在HashMap中卻可以
10 if (key == null || value == null) throw new NullPointerException();
11 //計算key的hash,注意,這里必須是一個非負數,詳見spread方法中的注釋
12 int hash = spread(key.hashCode());
13 //binCount表示添加當前節點前,這個桶上面的節點數
14 int binCount = 0;
15 //注意這里是個死循環
16 for (Node<K, V>[] tab = table; ; ) {
17 Node<K, V> f;
18 int n, i, fh;
19 if (tab == null || (n = tab.length) == 0)
20 //如果當前數組還沒有初始化的話,就進行初始化的工作(延遲初始化至該方法中)。然后會跳到下一次循環,添加節點
21 tab = initTable();
22 /*
23 tabAt方法是Unsafe類中通過volatile方式獲得指定地址所對應的值,方式是通過(n - 1) & hash
24 也就是通過(n - 1) & hash的方式來找到這個數據插入的桶位置,和HashMap是一樣的
25 */
26 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
27 /*
28 casTabAt方法是Unsafe類中通過CAS的方式設置值,這里的意思是如果這個桶上還沒有數據存在的話,
29 就直接創建一個新的Node節點插入進這個桶就可以了,也就是快速判斷。當然如果CAS失敗了,會進入
30 到下一次循環中繼續判斷
31 */
32 if (casTabAt(tab, i, null,
33 new Node<K, V>(hash, key, value, null)))
34 break;
35 } else if ((fh = f.hash) == MOVED)
36 /*
37 如果當前桶的第一個節點是ForwardingNode節點的時候(ForwardingNode節點的hash值為MOVED),
38 也就是說當前桶正在被遷移中,就去幫助一起去擴容。等擴容完成后,就更新一下tab,下次循環還是會去插入節點的
39 */
40 tab = helpTransfer(tab, f);
41 else {
42 //走到這里說明當前這個桶上有節點
43 V oldVal = null;
44 /*
45 注意這里使用了synchronized來鎖住了當前桶上的第一個節點,同時也就證明了在Java 8的
46 ConcurrentHashMap中,鎖的粒度是在桶(鎖住第一個節點也就是在鎖住這個桶)這個級別
47 */
48 synchronized (f) {
49 /*
50 雙重檢查,可能的一種情況是(我的個人猜測):如果此時有兩個線程走到了第48行代碼處。第一個線程進入到了
51 synchronized同步語句塊中,并插入了新節點,最后觸發了擴容操作,此時table已經是一個newTable了
52 然后第二個線程進來,下面的判斷條件發現不等(tabAt方法是Unsafe類中直接拿的主內存值,而此時table
53 已經擴容成newTable了。所以此時會找到newTable中i位置處的第一個節點,以此和舊table中i位置處的
54 第一個節點對比(f是局部變量),發現不是同一個位置),于是就會退出同步語句塊,進入到下一次循環中
55 不管最終是不是這種解釋,在synchronized同步語句塊中加上雙重檢查本身就是一個好的編程習慣
56 */
57 if (tabAt(tab, i) == f) {
58 /*
59 如果節點是普通的Node節點的話(在spread方法中提到過,如果節點hash值>=0的話,
60 就是一個普通的Node節點)
61 */
62 if (fh >= 0) {
63 //設置binCount=1
64 binCount = 1;
65 /*
66 其實從下面的循環可以看出,ConcurrentHashMap中去掉了HashMap中的快速判斷模式
67
68 注意,在鏈表上每循環一個節點,binCount就+1(for循環運行機制:第一個節點不加)
69 */
70 for (Node<K, V> e = f; ; ++binCount) {
71 K ek;
72 //如果桶上當前節點的hash值和要插入的hash值相同,并且key也是相同的話
73 if (e.hash == hash &&
74 ((ek = e.key) == key ||
75 (ek != null && key.equals(ek)))) {
76 oldVal = e.val;
77 if (!onlyIfAbsent)
78 //如果onlyIfAbsent為false,就新值覆蓋舊值
79 e.val = value;
80 break;
81 }
82 Node<K, V> pred = e;
83 /*
84 e指向下一個節點,如果下一個節點為null,意味著已經循環到最后一個節點
85 還沒有找到一樣的,此時將要插入的新節點插到最后(pred指針指向當前節點的
86 上一個節點,因為e此時已經變成當前節點的下一個節點了)
87 */
88 if ((e = e.next) == null) {
89 pred.next = new Node<K, V>(hash, key,
90 value, null);
91 break;
92 }
93 }
94 } else if (f instanceof TreeBin) {
95 //如果節點是紅黑樹的話
96 Node<K, V> p;
97 //設置binCount=2,后面會解釋這里設置為2的意義
98 binCount = 2;
99 //執行紅黑樹的插入節點邏輯(紅黑樹的分析本文不做展開)
100 if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
101 value)) != null) {
102 oldVal = p.val;
103 if (!onlyIfAbsent)
104 p.val = value;
105 }
106 }
107 }
108 }
109 //binCount != 0說明要么已經在鏈表上添加了一個新節點,要么在紅黑樹中插入了一個節點
110 if (binCount != 0) {
111 //如果鏈表的數量已經達到了轉成紅黑樹的閾值的時候,就進行轉換
112 if (binCount >= TREEIFY_THRESHOLD)
113 /*
114 我在之前的HashMap源碼分析中已經說過,是否真正會轉成紅黑樹,
115 需要看當前數組的桶的個數是否大于等于MIN_TREEIFY_CAPACITY,小于就只是擴容
116 */
117 treeifyBin(tab, i);
118 if (oldVal != null)
119 //返回舊值
120 return oldVal;
121 //如果上面是在鏈表尾新添加了一個節點的話,就跳出死循環,進入到下面的addCount方法中
122 break;
123 }
124 }
125 }
126 //添加節點后,計數器+1(在該方法中,同時會有多個線程進行擴容遷移的邏輯)
127 addCount(1L, binCount);
128 return null;
129 }
130
131 /**
132 * 第12行代碼處:
133 */
134 static final int spread(int h) {
135 return (h ^ (h >>> 16)) & HASH_BITS;
136 }重點看一下上面的spread方法:我在HashMap源碼分析中已經解釋了這里用高16位和低16位進行異或來作為最終hash的原因了。但是在HashMap源碼中這里是(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16),因為之前已經判斷過key不能為null,所以這里不用再判斷了。所以實際上這里和HashMap中計算的差異點僅僅在于最后多了個“& HASH_BITS”的條件。
HASH_BITS是一個有31個1的二進制數,也就是Integer.MAX_VALUE。那么按位與之后的結果是如何呢?如果是正數(包括0)的話,這樣做不會有任何作用,但是如果h是一個負數呢?要知道如果是負數的話,最高位是1(最高位是符號位),這樣和HASH_BITS按位與之后就變成了一個正數。也就是說“& HASH_BITS”這個條件的添加是為了確保計算出來的hash值是非負的。但是為什么在HashMap源碼中不需要添加呢?因為在之后的判斷桶的位置使用的是(table.length - 1) & hash,之前在HashMap構造器中分析過,table.length不可能為0,最小就是1(調用構造器時table.length確實為0。但是請注意,(table.length - 1) & hash這個條件是在數組擴容(初始化)方法的后面調用的,此時數組已經有容量了),所以這里table.length - 1最小就是0,是非負的。所以和hash按位與之后就能把最高位符號位1改成0,當然如果hash本身就是大于等于0的話,就無所謂了。也就是在說,在HashMap中,將hash值非負數化處理是延遲到了(table.length - 1) & hash這個操作上。但是其實在ConcurrentHashMap中計算桶位置也是用的“(table.length - 1) & hash”這種方式,所以說在這里使用“& HASH_BITS”這個條件,以此來將hash值提前非負數化處理是有原因的。原因就在于:在ConcurrentHashMap中,hash值為負數是有特殊含義的:
-1(MOVED):代表當前節點正在遷移
-2(TREEBIN):代表當前節點是紅黑樹節點
-3(RESERVED):代表當前節點是用在computeIfAbsent和compute方法中的占位節點
而在后面的源碼中可以看到當判斷當前節點是否是普通Node節點時,是通過判斷節點的hash值是否>=0來實現的(如果<0則代表是紅黑樹節點,RESERVED只在computeIfAbsent和compute方法中有),如果現在計算出的hash值就有負數的話,那我就分不清到底是普通Node節點還是紅黑樹節點了。
在上面第21行代碼處調用了數組的初始化方法initTable,下面來看一下其實現:
1 /**
2 * 注意,該方法只是做初始化數組用的,不像HashMap中的resize方法除了用來初始化也用來做擴容
3 * ConcurrentHashMap中的擴容方法是transfer
4 */
5 private final Node<K, V>[] initTable() {
6 Node<K, V>[] tab;
7 int sc;
8 //如果當前數組已經不為空了,就可以退出了
9 while ((tab = table) == null || tab.length == 0) {
10 if ((sc = sizeCtl) < 0)
11 /*
12 前面說明過,如果sizeCtl為-1,代表當前數組正在被別的線程做初始化工作
13 這里的sizeCtl不用想都知道肯定是被volatile修飾的,以確保內存可見性
14 既然現在已經有別的線程在初始化了,那么當前這個線程就不用再做一遍了,
15 只需要不斷讓渡本線程資源,跳進下一次循環,直到初始化工作完成就行了
16 */
17 Thread.yield();
18 /*
19 這里利用Unsafe的CAS操作,將sizeCtl改為-1,代表著當前線程要去進行初始化數組的工作了,
20 其他線程只能在上面的if條件中讓渡資源。當然如果CAS競爭失敗,繼續去循環就行了
21 */
22 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
23 //走到這里,說明搶到了資源,準備開始做初始化工作
24 try {
25 /*
26 這里會再判斷一次當前數組是否為空,避免重復的數組初始化工作。如果第一個線程已經走到第10行代碼處,
27 然后此時被切出資源,注意此時sc還沒有被賦值。這時候第二個線程進來了,完成了初始化工作后退出了
28 此時sizeCtl被賦值成*負載因子后的結果。而現在第一個線程又拿到資源,將sc賦值成第二個線程剛才已經
29 改過后的值,然后CAS成功了,那么此時又會開始進行初始化工作(之前已經初始化過了)。所以這里的再次判斷
30 就是為了避免在高并發下,數組會被重復初始化的情況出現。這里的設計思路其實類似于單例的雙重加鎖模式
31 */
32 if ((tab = table) == null || tab.length == 0) {
33 /*
34 前面分析過,如果sizeCtl=0說明當前調用的是無參構造器,那么此時改成初始值16
35 n此時就代表著數組應該要創建的容量(也就是桶的個數)
36 */
37 int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
38 //用上一行得出的n的容量來創建一個新的Node數組
39 @SuppressWarnings("unchecked")
40 Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
41 table = tab = nt;
42 /*
43 初始化工作完成后,此時計算實際的閾值:n*0.75(負載因子),然后在finally
44 子句中賦值給sizeCtl。注意這里是n - (n >>> 2),實際上也就相當于n*0.75,
45 也就是之前說過的這里的負載因子會用默認的0.75,而不是自定義的值
46 */
47 sc = n - (n >>> 2);
48 }
49 } finally {
50 /*
51 之所以要把下面這行代碼放在finally子句中,是因為在上面第39行代碼處,使用了@SuppressWarnings注解來
52 抑制異常,也就是說,這里可能會拋出異常(又或者是可能發生OOM)。如果拋出異常的話,sizeCtl就一直是-1了,
53 這樣別的線程也不能完成初始化工作,就成為死循環了。所以sizeCtl賦值這行代碼放在finally子句的意義就是:
54 確保即使發生異常的話,也要將sizeCtl賦成初始值sc,然后再讓其他的線程完成初始化工作
55 */
56 sizeCtl = sc;
57 }
58 break;
59 }
60 }
61 return tab;
62 }在上面第3小節put方法中的第127行代碼處調用了計數方法addCount(addCount方法的執行邏輯分為兩部分,前半部分是做計數的,而后半部分是用來做擴容的。擴容留在下一小節進行分析)。在HashMap中,對size計數+1是很簡單的,直接加就行了(注意,在HashMap中,size表示的是桶的個數,而在這里,需要計數的是所有節點的個數,兩者不是同一個維度);但在ConcurrentHashMap中卻是一件很難做到的事,因為要涉及到多線程的操作。在Java 7中,是等待獲取到所有Segment的鎖之后再進行統計的。也就是說會把當前所有線程都停止,然后去計算現在所有的節點數。這樣雖然能精確計算出來結果,但效率卻非常低。
下面來說一下在Java 8中的計數過程:
在沒有并發或者低并發的場景下:baseCount是用來記錄當前節點個數的;
如果CAS設置baseCount+1失敗,就代表著這里有多個線程在搶著計數,那么此時就會轉而使用CounterCell數組來進行計數。每個線程都會通過隨機探測(ThreadLocalRandom.getProbe() & m)的方式來找到屬于它的CounterCell數組中的那個CounterCell槽位置(ThreadLocalRandom在并發的場景下性能更好),在這個CounterCell上進行計數。最后計算出baseCount與counterCells數組中所有非空值的和就是最后的結果。
也就是說,第一個線程會在baseCount上計數,而剩下的線程,會在CounterCell數組中計數。比如說現在baseCount為16,第一個線程做完了加節點后,將baseCount+1變為了17,而剩下的三個線程CAS失敗,會在CounterCell數組的第1、3、7個位置處賦值為1(這個索引位置是我隨便舉的),此時數組中所有的節點數就是17+1+1+1=20個節點(這里的設計思想其實和Doug Lea開發的LongAdder類是一致的)。
這里來說一下為什么采用隨機探測槽,最后將所有結果匯總的方式來進行計數,而不是采用CAS搶占的方式?在高并發下,相比于所有線程都在同一位置CAS來進行嘗試,失敗的話就繼續嘗試的行為;分成多個數組位置來分別計算,最后匯總的方式顯然要更加高明(但與之帶來的是更復雜的邏輯),避免了失敗后的自旋過程,同時也能在同一時刻讓所有的線程都在做計數工作。
1 /**
2 * ConcurrentHashMap:
3 */
4 private final void addCount(long x, int check) {
5 CounterCell[] as;
6 long b, s;
7 /*
8 如上面注釋所說:在基本上沒什么并發的場景下,baseCount是用來做計數用的,只要CAS設置+1成功就完事了
9 但是如果CounterCell數組不為空,說明現在是有多個線程在同時計數。抑或是CAS設置失敗,就進入到下面
10 的if條件中
11 */
12 if ((as = counterCells) != null ||
13 !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
14 CounterCell a;
15 long v;
16 int m;
17 //uncontended表示沒有發生競爭的標志位
18 boolean uncontended = true;
19 /*
20 如果CounterCell數組為空,或者隨機探測的槽位置處為空,又或者嘗試將其中探測到的CounterCell
21 槽位置處的值+1的時候也失敗了(快速嘗試),就會進入到fullAddCount方法中,以此來完成+1的操作
22 */
23 if (as == null || (m = as.length - 1) < 0 ||
24 (a = as[ThreadLocalRandom.getProbe() & m]) == null ||
25 !(uncontended =
26 U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
27 //在該方法中會完成最終的計數工作
28 fullAddCount(x, uncontended);
29 /*
30 可以看到在計完數后,這里就退出了,沒有走到下面的幫助擴容的邏輯中。為什么?可以想想走到
31 這里的時候,上面經歷了兩次CAS失敗,說明當前是在一個高并發的場景下。如果此時我還去幫助
32 擴容的話,多個線程之間的鎖競爭、上下文切換的開銷,都會被放大
33 */
34 return;
35 }
36 /*
37 走到這里說明上面的CAS CounterCell操作成功了,check<=1(也就是傳進來的binCount),
38 要么是桶里當前是空的,新加了一個節點,要么就是桶里面只有一個節點,在后面新加了一個節點
39 這兩種情況下也不會走幫助擴容的邏輯,直接返回(我猜測是因為在這種情況下,節點數量并不多,
40 于是就不用幫著擴容了)。這里也揭示了在上面put方法中的第98行代碼處,為什么之前在插入紅黑樹
41 節點的時候,會設置binCount=2,如果設置一個小于2的數,那后面就不會走幫忙擴容的邏輯了
42 (不走也無妨,走了更好)
43 */
44 if (check <= 1)
45 return;
46 //走到這里說明check > 1,計算一下此時實際的所有節點的值,賦值給局部變量s,以便下面擴容時用到
47 s = sumCount();
48 }
49 //...
50 }
51
52 /**
53 * 第28行代碼處:
54 * 在該方法中完成最終的+1計數操作
55 */
56 private final void fullAddCount(long x, boolean wasUncontended) {
57 int h;
58 //如果ThreadLocalRandom還沒有被初始化,就執行初始化的工作
59 if ((h = ThreadLocalRandom.getProbe()) == 0) {
60 //在初始化的過程中當前線程會被分配一個隨機數probe(threadLocalRandomProbe)
61 ThreadLocalRandom.localInit();
62 h = ThreadLocalRandom.getProbe();
63 //未發生競爭標志位重置為true
64 wasUncontended = true;
65 }
66 //沖突標志位,當其值為true,說明此時CounterCell數組該擴容了
67 boolean collide = false;
68 for (; ; ) {
69 CounterCell[] as;
70 CounterCell a;
71 int n;
72 long v;
73 if ((as = counterCells) != null && (n = as.length) > 0) {
74 /*
75 CounterCell數組已經初始化了的時候,找到隨機探測的槽如果為null,那么此時就
76 新創建一個CounterCell
77 */
78 if ((a = as[(n - 1) & h]) == null) {
79 /*
80 cellsBusy用來表示一個鎖資源,0是無鎖狀態,1是上鎖狀態
81 當前為0表示此時沒有線程在做數組放入CounterCell的過程,也沒有正在擴容
82 */
83 if (cellsBusy == 0) {
84 //創建一個新的CounterCell,將1傳進去
85 CounterCell r = new CounterCell(x);
86 //CAS上鎖,失敗了后面會將沖突標志位collide置為true
87 if (cellsBusy == 0 &&
88 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
89 boolean created = false;
90 try {
91 CounterCell[] rs;
92 int m, j;
93 //雙重檢查(之前見過很多次了)
94 if ((rs = counterCells) != null &&
95 (m = rs.length) > 0 &&
96 rs[j = (m - 1) & h] == null) {
97 //上面新創建的CounterCell放在數組中
98 rs[j] = r;
99 created = true;
100 }
101 } finally {
102 /*
103 釋放鎖(放在finally子句中的意義在上面的initTable方法中
104 已經解釋過了)
105 */
106 cellsBusy = 0;
107 }
108 //如果創建成功了,就跳出死循環(也就是該方法結束了)
109 if (created)
110 break;
111 /*
112 走到這里說明該槽已經被別的線程設置進去了(注意上面的雙重檢查),
113 那么此時就重新循環,找下一個位置就行了
114 */
115 continue;
116 }
117 }
118 //沖突標志位collide復位為false,避免之后可能會走到擴容邏輯中,而是繼續下一次嘗試
119 collide = false;
120 } else if (!wasUncontended)
121 /*
122 走到這里說明槽位置不為null,并且已經知道了上一次的CAS已經失敗了(第26行代碼處)
123 此時將wasUncontended重置為true,走下一遍循環即可
124 */
125 wasUncontended = true;
126 else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
127 //此時會再嘗試一次將新值插入進去,插入成功就退出了,插入失敗的話也無妨,找下一個位置
128 break;
129 else if (counterCells != as || n >= NCPU)
130 /*
131 counterCells != as說明此時CounterCell數組正在擴容中,n >= NCPU說明當前數組容量已經
132 達到或超過了當前JVM可用的最大線程數,就讓collide置為false,避免走到下面的擴容邏輯中,
133 而是繼續下一次嘗試(從這里也說明了,CounterCell數組的長度不可能無限制增大,最多為
134 當前JVM可用的最大線程數(如果再繼續增大的話,剩下的線程也是多余的,徒增消耗))
135 */
136 collide = false;
137 else if (!collide)
138 /*
139 走到這里,說明上面條件都不滿足。此時將沖突標志位collide由原來的false重新置為true,
140 等下次循環的時候如果前面還是不滿足的話就會走到下面的擴容邏輯中去了
141 */
142 collide = true;
143 else if (cellsBusy == 0 &&
144 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
145 //走到這里,說明上面條件都不滿足。上鎖,此時要進行CounterCell數組擴容的邏輯了
146 try {
147 //如果此時數組正在被別的線程擴容中,就不用本線程再擴容了
148 if (counterCells == as) {
149 //創建一個2倍容量的新數組
150 CounterCell[] rs = new CounterCell[n << 1];
151 /*
152 遍歷的方式來進行數據遷移(畢竟數組的最大長度是當前JVM可用的最大線程數,不會
153 特別大,普通遍歷足矣)
154 */
155 for (int i = 0; i < n; ++i)
156 rs[i] = as[i];
157 counterCells = rs;
158 }
159 } finally {
160 //釋放鎖(在finally子句中釋放鎖的寫法,之前見過很多次了)
161 cellsBusy = 0;
162 }
163 //沖突標志位collide復位為false
164 collide = false;
165 //擴容后重新循環,嘗試添加數據(當然,如果上面條件還是都不滿足的話,還是會走到這里擴容的)
166 continue;
167 }
168 //走到這里,會生成一個新的隨機數probe,進行下一次嘗試
169 h = ThreadLocalRandom.advanceProbe(h);
170 } else if (cellsBusy == 0 && counterCells == as &&
171 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
172 /*
173 此時CounterCell數組沒有初始化,如果cellsBusy沒有上鎖,當前沒有處于擴容中,那現在就CAS上鎖
174 以此來執行CounterCell數組初始化的工作
175 */
176 boolean init = false;
177 try {
178 //雙重檢查
179 if (counterCells == as) {
180 //創建一個初始容量為2的CounterCell數組
181 CounterCell[] rs = new CounterCell[2];
182 //在槽位置處創建一個新的CounterCell
183 rs[h & 1] = new CounterCell(x);
184 counterCells = rs;
185 init = true;
186 }
187 } finally {
188 //釋放鎖
189 cellsBusy = 0;
190 }
191 //如果創建CounterCell數組成功,就可以退出了(此時數據也放進去了),否則繼續循環
192 if (init)
193 break;
194 } else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
195 /*
196 如果當前cellsBusy鎖正在被上鎖,就退而求其次,嘗試對baseCount做更新
197 當然,如果也失敗了,也還是會繼續循環
198 */
199 break;
200 }
201 }
202
203 /**
204 * 第47行代碼處:
205 * 計算baseCount與counterCells數組中所有非空值的和,
206 * 即當前ConcurrentHashMap中所有的節點數
207 * <p>
208 * 注意這里只是計算出一個近似值,如果該方法計算出結果后,
209 * 此時又有一個線程進來添加了節點,那么之前計算出來的
210 * 結果就不準了。這個是沒有辦法避免的,只能在后續的代碼
211 * 中去考慮這種情況
212 */
213 final long sumCount() {
214 CounterCell[] as = counterCells;
215 CounterCell a;
216 long sum = baseCount;
217 if (as != null) {
218 for (int i = 0; i < as.length; ++i) {
219 if ((a = as[i]) != null)
220 sum += a.value;
221 }
222 }
223 return sum;
224 }在上面第3小節put方法中的第40行代碼處調用了幫助擴容方法helpTransfer,同時在上面的addCount方法中的后半部分也是做擴容的。在我看來,ConcurrentHashMap的源碼中,多線程擴容的邏輯是最為復雜的,也是最為精妙的,面試并不一定會問到,但是仍然值得好好研究。雖然你我可能沒有太多機會實現這樣的邏輯,但是了解大師的設計思路,對于自己的能力來說也是一種提升。
可以思考一下:如果讓你實現在多線程場景下的擴容邏輯,你會怎么做?我想絕大多數人想到的都是讓一個線程去做擴容的邏輯,其他的線程被阻塞住。就如同上面初始化數組的邏輯一樣。這樣雖然相對來說可能實現起來更容易一些,但是效率卻并不高。如果一個線程在執行擴容的時候會花費很長時間,那么其他的線程都會在此被阻塞住。所以Doug Lea在ConcurrentHashMap中的實現是:其他的線程并不會被阻塞住,而是幫助一起去做擴容,每個線程都會執行一小部分的擴容工作(擁抱多線程,而不是拒絕多線程)。這樣可以最大程度地發揮多線程的優勢,但是相對的,代碼的邏輯會變得異常復雜。需要去調配好各個線程的分工,同時也要考慮到所有可能發生的情況。
至于為什么初始化數組的邏輯沒有采用多線程來實現,我猜想是因為初始化的操作很簡單,執行速度也很快。也就不需要多個線程之間幫助初始化了,如果這么做的話只會徒增復雜度,但收益肯定不會很明顯的。
在了解ConcurrentHashMap中擴容的實現之前,首先需要知道一些前置知識:
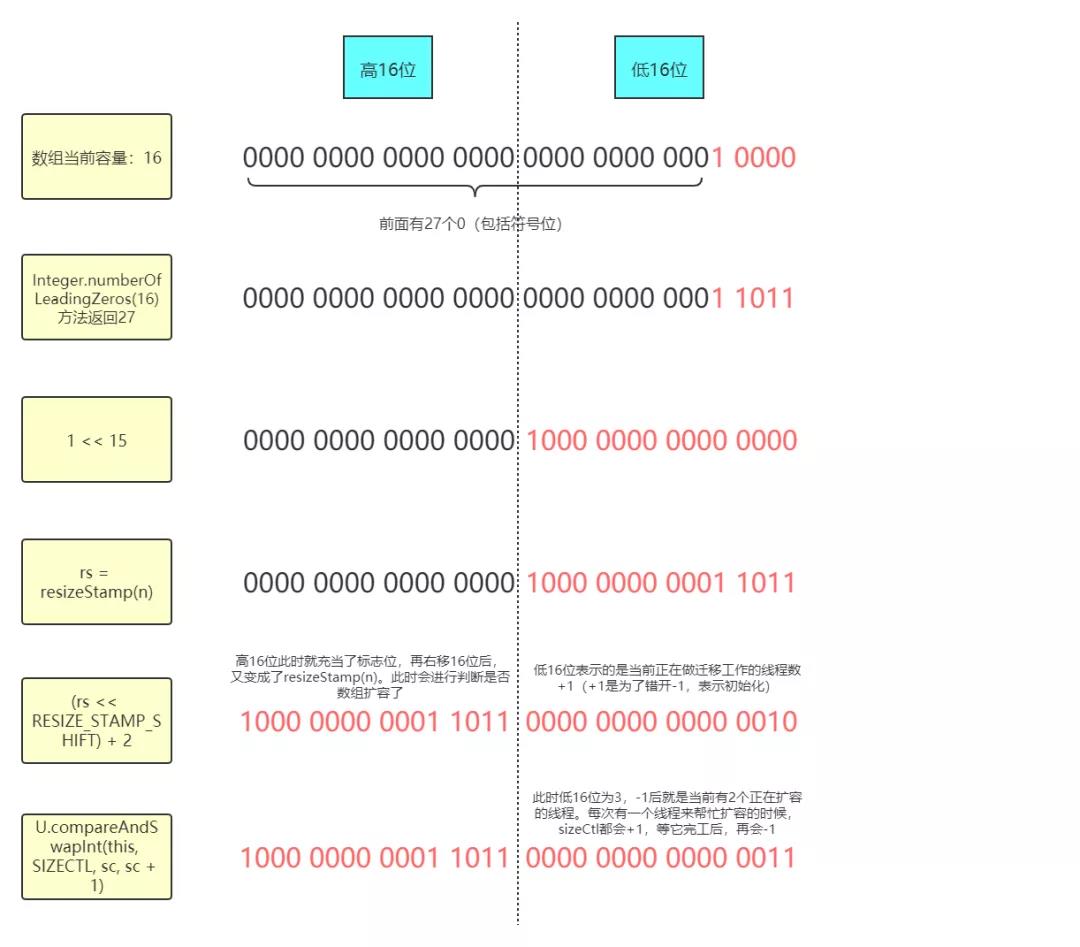
每個線程對于當前的數組長度都會生成一個擴容戳,具體是在resizeStamp方法中生成的:
1 /**
2 * ConcurrentHashMap:
3 * 該方法其實并沒有什么實際意義,只是為了根據數組長度生成一個標記位,后續會拿這個標記位進行判斷
4 */
5 static final int resizeStamp(int n) {
6 /*
7 Integer.numberOfLeadingZeros方法是用來計算最高位為1之前的0的個數(包括符號位),而RESIZE_STAMP_BITS
8 是16,這里也就是說,將數組長度取最高位為1之前的0的個數和2的15次方做按位或的操作,得出來的數據
9 在低16位的最高位為1(后續再左移16位后符號位就為1了),剩下的就是0的個數了(后面會舉示意圖)
10 這里之所以會用Integer.numberOfLeadingZeros這個方法是為了確保最后計算出的結果只能在低16位上有值,
11 高16位上不能有值,后面會說明原因
12 */
13 return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
14 }這樣每個線程都會有自己計算出來的擴容戳,如果兩個線程進行擴容戳比對的時候發現相等,就說明這兩個線程是在同一次擴容操作中;如果不等,則說明不在同一次擴容操作中。這是因為擴容戳是由當前數組長度決定的,如果擴容戳不等,那么這兩個線程在當時獲取到的數組長度就不等,也就說明這兩個線程不在同一次擴容中。而判斷擴容戳的相等于否也是后面判斷擴容是否停止的條件之一。
這個擴容戳會在擴容時左移16位,也就是跑到了高16位上。而低16位此時表示的是正在做擴容遷移時的線程數量+1。比如說在擴容的時候有4個線程在同時做擴容的工作,那么低16位就是101(4+1=5,5的二進制是101)。每來一個線程幫助做擴容,低16位就會+1;而每一個線程幫完忙了,低16位就會-1。而擴容戳會賦值到sizeCtl上,這樣低16位永遠表示的是當前正在進行擴容的線程數量+1。
那么現在就來看一下addCount方法的后半部分和helpTransfer方法的實現:
1 /**
2 * ConcurrentHashMap:
3 */
4 private final void addCount(long x, int check) {
5 //...
6 //如果check不是負數,就進入到下面的幫助擴容邏輯中。在clear等方法中會傳入-1,也就是說這些方法不會去擴容
7 if (check >= 0) {
8 Node<K, V>[] tab, nt;
9 int n, sc;
10 /*
11 s記錄的是當前ConcurrentHashMap中所有的節點數量,如果其大于設置的閾值sizeCtl,并且數組不為空,
12 并且數組的長度小于最大長度2的30次方的話,就執行擴容操作。否則不擴容。while在此是保證一定要幫助擴容
13 */
14 while (s >= (long) (sc = sizeCtl) && (tab = table) != null &&
15 (n = tab.length) < MAXIMUM_CAPACITY) {
16 //此時會根據數組長度計算出一個標記位,詳見resizeStamp方法的注釋
17 int rs = resizeStamp(n);
18 /*
19 sc小于0說明此時有別的線程正在擴容(不可能為-1,因為此時初始化操作已經結束了,
20 并且上面已經判斷數組不為空了),那當前線程就來幫助一起做擴容
21 */
22 if (sc < 0) {
23 /*
24 退出擴容時的條件,也就意味著此時已經做完擴容了:
25 1.(sc >>> RESIZE_STAMP_SHIFT) != rs說明當前線程不在同一次擴容中(sc右移16位的結果理論上
26 應該和rs相同,但如果不同,說明此時的數組長度已經變了,可能是當前線程還在上一次擴容中,而其它
27 線程已經在下一次了(可能是sc和tab賦值的間隙中觸發了下一次擴容))
28 2.sc == rs + 1說明當前還有一個線程在做最后的檢查工作(第一個線程初始為+2,但是最后是每個擴容線程
29 都會-1,實際上就相當于多減了一次,也就是這里+1的意思。而如果連檢查也完成的話,sc會復位為一個正數
30 所以此時是最后一個線程正在做檢查的時刻),那么本線程也不用幫忙了,直接等那個線程檢查完就行了
31 (這里正確的判斷條件應該為sc == (rs << RESIZE_STAMP_SHIFT) + 1,這里實際上是個bug,后面會說明)
32 3.sc == rs + MAX_RESIZERS和上面是一樣的道理,MAX_RESIZERS表示最多可以幫助的線程數量+1(低16位
33 都為1,已經把低16位都占滿了,不能再大了),也就是說現在已經有MAX_RESIZERS - 1個線程在幫忙做遷移了,
34 本線程就不摻和了(這里正確的判斷條件應該為sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,
35 這里實際上是個bug,后面會說明)
36 4.nextTable已經為空了(nextTable只在擴容時才有值)
37 5.transferIndex <= 0說明bound區間已經都分配完了,那么本線程也不需要擴容了
38 */
39 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
40 sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
41 transferIndex <= 0)
42 break;
43 /*
44 此時sc<0,說明本線程當前是要幫助做遷移的。將sizeCtl+1(注意,sizeCtl此時是負數),然后進入
45 transfer方法幫忙做遷移。在transfer方法里面等該線程做完遷移工作后,會再將sizeCtl-1的。也就是說,
46 在上面我對構造器中sizeCtl所做的注釋中的第2條:cizeCtl中低16位為(1+n)(高16位為標記位),
47 這里n代表正在執行擴容操作的線程數量
48 */
49 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
50 transfer(tab, nt);
51 } else if (U.compareAndSwapInt(this, SIZECTL, sc,
52 (rs << RESIZE_STAMP_SHIFT) + 2))
53 /*
54 否則sc>=0,說明當前線程是第一個進來要進行擴容的線程,將sizeCtl初始為
55 (rs << RESIZE_STAMP_SHIFT) + 2,左移16位后,會將之前的標記位移動到高16位處,然后
56 低16位為10(+2),這里+2是為了錯開1這個值,因為它代表著初始化
57 */
58 transfer(tab, null);
59 //重新計算一下此時的最新節點數,以便下一次循環時進行判斷
60 s = sumCount();
61 }
62 }
63 }
64
65 /**
66 * 幫助做擴容工作
67 */
68 final Node<K, V>[] helpTransfer(Node<K, V>[] tab, Node<K, V> f) {
69 Node<K, V>[] nextTab;
70 int sc;
71 /*
72 如果此時數組不為空并且當前節點是ForwardingNode節點的時候(是ForwardingNode
73 節點就說明當前桶正在被遷移中)
74 */
75 if (tab != null && (f instanceof ForwardingNode) &&
76 (nextTab = ((ForwardingNode<K, V>) f).nextTable) != null) {
77 //此時會根據數組長度計算出一個標記位,詳見resizeStamp方法的注釋
78 int rs = resizeStamp(tab.length);
79 /*
80 nextTab == nextTable、table == tab和(sc = sizeCtl) < 0這三個條件都是在說如果當前
81 數組還沒擴容完(注意這里是短路與),也就是正在擴容中。while在此是保證一定要幫助擴容
82 */
83 while (nextTab == nextTable && table == tab &&
84 (sc = sizeCtl) < 0) {
85 /*
86 退出擴容時的條件,也就意味著此時已經做完擴容了:
87 1.(sc >>> RESIZE_STAMP_SHIFT) != rs說明當前線程不在同一次擴容中(sc右移16位的結果理論上
88 應該和rs相同,但如果不同,說明此時的數組長度已經變了,可能是當前線程還在上一次擴容中,而其它
89 線程已經在下一次了(可能是sc賦值前觸發了下一次擴容))
90 2.sc == rs + 1說明當前還有一個線程在做最后的檢查工作(第一個線程初始為+2,但是最后是每個擴容線程
91 都會-1,實際上就相當于多減了一次,也就是這里+1的意思。而如果連檢查也完成的話,sc會復位為一個正數
92 所以此時是最后一個線程正在做檢查的時刻),那么本線程也不用幫忙了,直接等那個線程檢查完就行了
93 (這里正確的判斷條件應該為sc == (rs << RESIZE_STAMP_SHIFT) + 1,這里實際上是個bug,后面會說明)
94 3.sc == rs + MAX_RESIZERS和上面是一樣的道理,MAX_RESIZERS表示最多可以幫助的線程數量+1(低16位
95 都為1,已經把低16位都占滿了,不能再大了),也就是說現在已經有MAX_RESIZERS - 1個線程在幫忙做遷移了,
96 本線程就不摻和了(這里正確的判斷條件應該為sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,
97 這里實際上是個bug,后面會說明)
98 4.transferIndex <= 0說明bound區間已經都分配完了,那么本線程也不需要擴容了
99 注意:相比于在addCount方法中的相同此處的判斷,該處代碼少了一個判斷,即判斷nextTable
100 是否為空,可以想想為什么?因為上面的while循環中已經判斷了nextTab == nextTable,
101 說明此時nextTable不為空
102 */
103 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
104 sc == rs + MAX_RESIZERS || transferIndex <= 0)
105 break;
106 /*
107 此時將sizeCtl+1(注意,sizeCtl此時是負數),然后進入transfer方法幫忙做遷移
108 在transfer方法里面等該線程做完遷移工作后,會再將sizeCtl-1的。也就是說,在上面我對構造器
109 中sizeCtl所做的注釋中的第2條:cizeCtl中低16位為(1+n)(高16位為標記位),這里n代表
110 正在執行擴容操作的線程數量
111 */
112 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
113 transfer(tab, nextTab);
114 break;
115 }
116 }
117 //擴容完返回局部變量nextTab就行了,反正它本身就代表著下一次新的2倍容量的新數組。setTabAt方法保證內存可見性
118 return nextTab;
119 }
120 return table;
121 }擴容時標記位的示意圖:
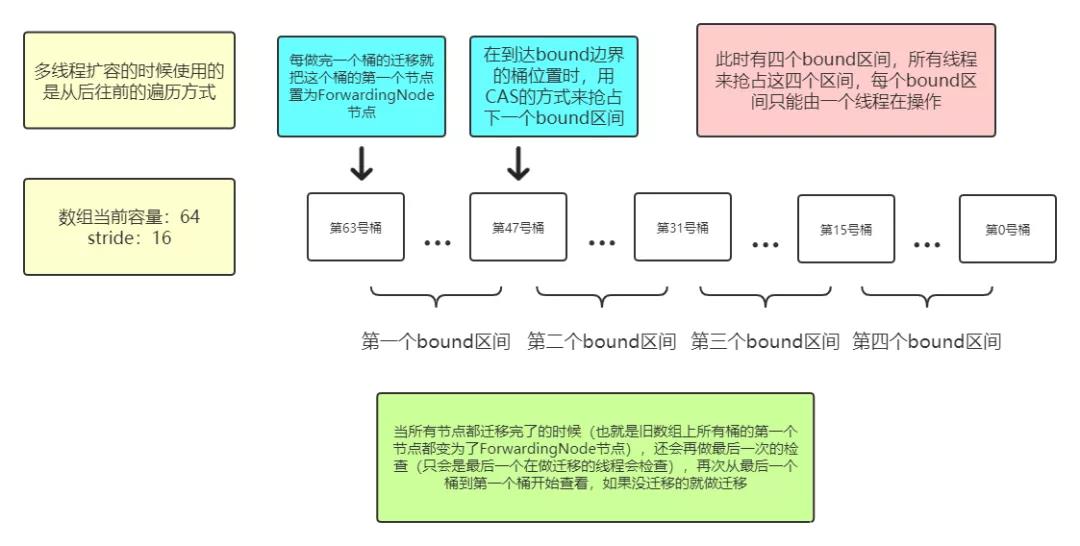
上面addCount方法的后半部分和helpTransfer方法都是在做擴容時的調控工作,而真正在擴容時做數據遷移是在transfer方法中,也就是上面第50行、第58行和第113行代碼處調用的:
1 /**
2 * ConcurrentHashMap:
3 * 該方法會利用多線程來分工執行擴容操作,會把遷移任務分成幾個bound區間,每個bound區間中會有幾個
4 * 桶,每個線程負責遷移本bound區間內的所有桶。因為只有在做完了本bound區間內的所有遷移工作后,才會
5 * 去CAS搶占下一次bound區間,在這期間不會有任何的CAS,所以多個線程之間可以并發地執行遷移工作
6 * 如果遷移工作都做完了的話,最后一個線程會再次檢查一下所有的桶是否完成了遷移(后面有示意圖)
7 * 當然了,如果只有一個線程,它就會完成全部的遷移工作(相當于每次都是它搶到資源)
8 * <p>
9 * (注:提前打下預防針,該方法的實現過程(尤其是前半部分)真的很不好理解,把它當作整個ConcurrentHashMap
10 * 源碼中最難理解的內容也不為過。我也是debug了好幾次才慢慢理解的,所以如果以下的注釋看不懂的話,自己多
11 * 調試幾次吧!)
12 */
13 private final void transfer(Node<K, V>[] tab, Node<K, V>[] nextTab) {
14 int n = tab.length, stride;
15 /*
16 定義bound區間的長度單位stride
17 1.stride=1:如果當前JVM最大可用線程數為1
18 2.stride=數組容量/(8*當前JVM最大可用線程數):當前JVM最大可用線程數大于1
19 3.stride=16:如果上面計算出來的值小于16,也就是說如果當前JVM最大可用線程數大于1的話,stride最小為16
20 該處計算是為了根據數組長度大小來計算出合適的stride
21 */
22 if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
23 stride = MIN_TRANSFER_STRIDE;
24 //如果nextTab是空的,意味著當前線程是第一個進來的擴容線程
25 if (nextTab == null) {
26 try {
27 //創建一個2倍舊容量的Node數組,最后舊數組上的數據會遷移到此數組中
28 @SuppressWarnings("unchecked")
29 Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n << 1];
30 //將上面創建出來的新數組賦值給nextTab
31 nextTab = nt;
32 } catch (Throwable ex) {
33 //如果上面拋出異常的話(可能是OOM),就將sizeCtl設置為int的最大值,停止擴容操作
34 sizeCtl = Integer.MAX_VALUE;
35 return;
36 }
37 nextTable = nextTab;
38 //transferIndex指針初始指向舊數組容量
39 transferIndex = n;
40 }
41 int nextn = nextTab.length;
42 /*
43 創建一個新的ForwardingNode節點,注意這里將nextTab賦值進去了,此時還是一個空數組,
44 但是后續的setTabAt操作可以保證內存的可見性
45 */
46 ForwardingNode<K, V> fwd = new ForwardingNode<K, V>(nextTab);
47 //advance表示是否完成了當前桶的遷移工作
48 boolean advance = true;
49 //finishing表示是否完成了所有的遷移工作(該參數是為了最后一次檢查用的)
50 boolean finishing = false;
51 //i指向當前桶的位置,bound指向當前線程所分配的區間邊界點
52 for (int i = 0, bound = 0; ; ) {
53 Node<K, V> f;
54 int fh;
55 //以下是在做分配bound區間,以及更新當前桶位置i的工作
56 while (advance) {
57 int nextIndex, nextBound;
58 if (--i >= bound || finishing)
59 /*
60 每次i都會減1,表示當前線程每遷移完一個桶就遷移下一個。--i >= bound表示當前線程分配過
61 bound區域,但是還沒有完成這個區域內所有桶的遷移工作;finishing為true這個條件的添加
62 是為了保證在所有遷移工作都做完后,最后的一次檢查也做完后,在此也能成功退出while循環
63 ,然后會跳到第96行代碼處(其實我感覺不加也可以,跳到下面if條件中也能退出,此時
64 transferIndex已經為0了。可能這樣做是省了一次讀取volatile變量的消耗(插入內存屏障))
65 */
66 advance = false;
67 else if ((nextIndex = transferIndex) <= 0) {
68 //小于等于0說明此時所有bound區間都被分配完了
69 i = -1;
70 advance = false;
71 } else if (U.compareAndSwapInt
72 (this, TRANSFERINDEX, nextIndex,
73 nextBound = (nextIndex > stride ?
74 nextIndex - stride : 0))) {
75 /*
76 為當前線程分配新的bound邊界,如果CAS失敗了,說明有其他的線程已經搶占到了本bound區間,
77 繼續循環去搶下個bound區間就可以了
78 */
79 bound = nextBound;
80 i = nextIndex - 1;
81 advance = false;
82 }
83 }
84 /*
85 走到這里advance復位為false,下面這個if條件是用來判斷當前線程是否遷移完了。i<0很好理解,表示所有
86 bound區間都被分配完了;i>=n我猜測是為了防止數據溢出(一個線程在上面的CAS操作中一直是失敗的,但是
87 每循環一次i就-1,等減到-2147483648后再-1就變成了2147483647(在這期間transferIndex一直大于0));
88 而i+n>=nextn這個條件看起來像是在判斷錯次擴容的場景(nextn和n已經不是2倍的關系了),但是在本方法外面
89 已經判斷過了,而且傳進來的tab和nextTab都是局部變量,所以我猜測這里只是個安全性檢查(這里也是我的
90 一個疑惑看不懂的點,我已經將該問題提交到StackOverFlow上,但截止到目前沒有收到有效答復:
91 https://stackoverflow.com/questions/63597067/in-concurrenthashmaps-transfer-method-i-dont-understand-the-meaning-of-these)
92 */
93 if (i < 0 || i >= n || i + n >= nextn) {
94 int sc;
95 //如果遷移工作都做完了的話(最后一次檢查也做完了)
96 if (finishing) {
97 //nextTable賦值為null,也就是說,nextTable只在擴容時候有值
98 nextTable = null;
99 //table此時指向兩倍容量,擴容后的數組
100 table = nextTab;
101 /*
102 設置新的sizeCtl閾值(遷移結束后該值將變為正數),n是原數組長度,這里的意思是sizeCtl=n*1.5,也就是
103 sizeCtl存放的是新數組長度*0.75(n*1.5=2*n*0.75)。之前說過,這里的負載因子會用默認的0.75,而不是
104 自定義的值
105 */
106 sizeCtl = (n << 1) - (n >>> 1);
107 return;
108 }
109 /*
110 注意:走到這里說明此時還沒有走最后一次檢查
111 每當一個線程做完遷移工作后,就將sizeCtl-1,注意在外面幫助線程調用本方法的時候,
112 是先+1的。也就是sizeCtl低16位(1 + n)的含義
113 */
114 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
115 /*
116 見addCount方法中的解釋,sc == (rs << RESIZE_STAMP_SHIFT) + 2表示
117 當前是第一個線程在執行擴容。而如果下面的if條件不等于,說明此時還有其他的線程
118 在進行擴容,而且此時所有的bound區間都分配完了,那么本線程就可以退出了(幫完忙了)
119 */
120 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
121 return;
122 /*
123 走到這里,說明上面的if條件是相等的,也就是說,當前線程是最后一個在執行著的遷移線程
124 注意,這里沒有return,說明此時還會再次循環一遍舊數組,看其中桶頭節點是否都變為了
125 FollowingNode節點。如果沒有,就繼續遷移。相當于最后會再做一遍檢查工作,做收尾
126 */
127 finishing = advance = true;
128 i = n;
129 }
130 } else if ((f = tabAt(tab, i)) == null)
131 /*
132 如果舊數組上該桶為null,也就是說該桶上沒有數據,那就說明當前這個桶不需要做遷移
133 此時只需要將頭節點設置為ForwardingNode節點就行了(ForwardingNode節點上的hash
134 值為MOVED,這樣別的線程在拿到這個桶的時候,就不會操作了)
135 */
136 advance = casTabAt(tab, i, null, fwd);
137 else if ((fh = f.hash) == MOVED)
138 /*
139 如果當前這個桶已經有別的線程在做遷移了(實際上是做完了遷移),就不需要本線程再做了,此時將
140 advance設置為true,進入下一次循環即可
141 */
142 advance = true;
143 else {
144 //synchronized鎖住當前鏈表上的第一個節點,也就是鎖住了這個桶,以防其他線程操作
145 synchronized (f) {
146 //雙重檢查,同putVal方法中synchronized同步語句塊中雙重檢查的解釋
147 if (tabAt(tab, i) == f) {
148 Node<K, V> ln, hn;
149 /*
150 如果節點是普通的Node節點的話(在spread方法中提到過,如果節點hash值>=0的話,
151 就是一個普通的Node節點)
152 */
153 if (fh >= 0) {
154 /*
155 其實下面的節點遷移的邏輯是和HashMap中是一樣的,即將原桶上這個鏈表上每個節點hash值在數組
156 容量二進制數為1的那個位置處去按位與判斷是0還是1,以此來拆分出兩個鏈表。然后根據結果
157 如果為0的話最后就會插入到新數組的原位置,為1就插入到原位置+舊數組容量的位置(我在之前對
158 HashMap的分析中講解了這里為什么是+舊數組容量)。但是在ConcurrentHashMap中做了進一步的
159 優化。可以試想一種情況:如果鏈表上所有節點計算出來的值都是0的話,那么如果還按照HashMap
160 中的方式來進行遷移,就還是會一個節點一個節點去遍歷判斷。其實這個時候我完全可以
161 不用去遍歷,直接將原來的這個鏈表的頭節點直接插入到新數組的原位置處就可以了,
162 在ConcurrentHashMap中就使用了這種優化思路
163 n是舊數組的容量,runBit記錄的是最后一次發生計算變動的值,比如一個鏈表上每個節點
164 按位與計算出的結果分別是1 0 1 1 0 0,那么runBit最終記錄的是倒數第二個節點的值:0
165 (因為最后一個是0,和前面這個0是一樣的)
166 */
167 int runBit = fh & n;
168 //如上面的解釋,lastRun最終會記錄到倒數第二個節點,現在記錄的都是初始位置第一個節點處
169 Node<K, V> lastRun = f;
170 /*
171 知道了上面runBit和lastRun代表了什么,那么下面的操作其實就很明朗了,就是在找最后一個
172 計算值發生變動的節點
173 */
174 for (Node<K, V> p = f.next; p != null; p = p.next) {
175 int b = p.hash & n;
176 if (b != runBit) {
177 runBit = b;
178 lastRun = p;
179 }
180 }
181 if (runBit == 0) {
182 //如果最后一個發生變動的節點是0(如果后面還有節點,就一定都為0),就將ln指針指向它
183 ln = lastRun;
184 hn = null;
185 } else {
186 //如果最后一個發生變動的節點是1(如果后面還有節點,就一定都為1),就將hn指針指向它
187 hn = lastRun;
188 ln = null;
189 }
190 /*
191 這里再次強調:ln或hn此時不一定代表的是原數組中最后一個節點,如果后面還有節點的話,
192 就跟lastRun節點的計算值是一樣的
193 下面就是從第一個節點遍歷到計算值發生變動的這個節點處(后面的節點不需要遍歷了,
194 因為計算值都是和lastRun是一樣的),逐漸去構建這兩個鏈表的過程
195 */
196 for (Node<K, V> p = f; p != lastRun; p = p.next) {
197 int ph = p.hash;
198 K pk = p.key;
199 V pv = p.val;
200 if ((ph & n) == 0)
201 /*
202 如果計算值是0,就插入到ln鏈表中。注意,這里使用的是頭插法,不同于HashMap
203 中的尾插法。原因就在于lastRun節點(ln指向lastRun)后面可能還有節點,如果
204 用尾插法,值就會被覆蓋了。同時也就意味著,HashMap中節點的遷移是穩定的算法,
205 而在ConcurrentHashMap中則是不穩定的,不是正序也不是逆序。而將創建結果
206 再賦值給ln也是為了更新一下ln指針的位置,使ln指針始終指向第一個節點處,這點
207 很重要,因為下面要用到它
208 */
209 ln = new Node<K, V>(ph, pk, pv, ln);
210 else
211 //如果計算值是1,就使用頭插法插入到hn鏈表中。
212 hn = new Node<K, V>(ph, pk, pv, hn);
213 }
214 /*
215 走到這里說明已經將原來的舊數組上的鏈表拆分完畢了,現在分成了兩個鏈表,ln和hn。接下來需要
216 做的工作就很清楚了:將這兩個鏈表分別插入到新數組的原位置和原位置+舊數組容量的位置就可以了
217 setTabAt方法是Unsafe類中通過volatile方式設置指定地址的值,這里將ln鏈表賦值在新數組
218 nextTab的i(原數組桶的位置)位置處
219 注意,這里不需要再像HashMap中將ln和hn鏈表中最后一個節點的next指針指向null了,可以想想
220 為什么?因為上面第196行代碼處是循環到lastRun節點為止的,也就是說我不用去管lastRun的next
221 指針了,因為后面如果沒有節點的話next指針肯定是null的,如果后面有節點,那next指針也都是指向
222 正確的
223 */
224 setTabAt(nextTab, i, ln);
225 //這里將hn鏈表賦值在新數組nextTab的i(原數組桶的位置)+舊數組容量位置處
226 setTabAt(nextTab, i + n, hn);
227 /*
228 將舊數組上這個桶的頭節點置為ForwardingNode節點,這樣該節點的hash值就變為了MOVED
229 也就是說,舊數組上這個桶的遷移工作,當前線程已經做完了,不再需要別的線程再做了
230 對應于第137行代碼處。需要注意的是,這里只是做完了舊數組上一個桶的遷移工作,
231 并沒有做完全部工作。在HashMap中,所有桶的遷移工作都是由一個線程完成的,而在
232 ConcurrentHashMap中則是由多線程來完成(要看是哪個線程搶到了資源。極端條件下,
233 由一個線程來全部完成(每次都是它搶到)),充分利用了多線程的優勢
234 */
235 setTabAt(tab, i, fwd);
236 //advance設置為true,代表當前桶的遷移工作完成了
237 advance = true;
238 } else if (f instanceof TreeBin) {
239 //如果是紅黑樹,就執行紅黑樹的遷移邏輯(紅黑樹的分析本文不做展開)
240 TreeBin<K, V> t = (TreeBin<K, V>) f;
241 TreeNode<K, V> lo = null, loTail = null;
242 TreeNode<K, V> hi = null, hiTail = null;
243 int lc = 0, hc = 0;
244 for (Node<K, V> e = t.first; e != null; e = e.next) {
245 int h = e.hash;
246 TreeNode<K, V> p = new TreeNode<K, V>
247 (h, e.key, e.val, null, null);
248 if ((h & n) == 0) {
249 if ((p.prev = loTail) == null)
250 lo = p;
251 else
252 loTail.next = p;
253 loTail = p;
254 ++lc;
255 } else {
256 if ((p.prev = hiTail) == null)
257 hi = p;
258 else
259 hiTail.next = p;
260 hiTail = p;
261 ++hc;
262 }
263 }
264 ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
265 (hc != 0) ? new TreeBin<K, V>(lo) : t;
266 hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
267 (lc != 0) ? new TreeBin<K, V>(hi) : t;
268 setTabAt(nextTab, i, ln);
269 setTabAt(nextTab, i + n, hn);
270 setTabAt(tab, i, fwd);
271 advance = true;
272 }
273 }
274 }
275 }
276 }
277 }擴容時數據遷移的示意圖:
上面在addCount方法和helpTransfer方法中,我注釋了兩個地方是存在bug的:在判斷擴容完成,準備跳出的這兩個條件:sc == rs + 1和sc == rs + MAX_RESIZERS,應該改為sc == (rs << RESIZE_STAMP_SHIFT) + 1和sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,這是為什么呢?可以想到,rs指向的是resizeStamp(n),也就是上面示意圖演示的一個大于0的數,而sc指向sizeCtl,程序走到這里肯定是小于0的(注意上面一行代碼:在addCount方法中是“sc < 0”,在helpTransfer方法中是“(sc = sizeCtl) < 0”,都是在sc小于0的前提下),那么如何才能做到一個大于0的數在+1或者+MAX_RESIZERS(65535)后,能變成一個負數呢?答案肯定是不可能的。數據溢出的情況也不可能出現,因為resizeStamp(n)方法保證數據只能放在低16位上(最大的情況也就是n為1的時候,此時前導0的個數也就是31而已,這也就是為什么在resizeStamp方法里面使用Integer.numberOfLeadingZeros方法的原因)。而上個判斷遷移結束的條件是(sc >>> RESIZE_STAMP_SHIFT) != rs:將siztCtl右移16位后和resizeStamp(n)進行判斷是否相等。能這么進行判斷的前提也是因為resizeStamp方法計算出來的數據只能在低16位上。那么既然rs的值只能在低16位上,又何談溢出一說呢?
所以現在造成的結果就是這兩個條件永遠都不會滿足,相當于是個廢條件,幫助線程的數量也就沒有了上下界,可能會造成遷移過程中一些本不需要幫忙做遷移的線程錯誤地進入到transfer方法中的情況出現。這里Doug Lea原本的意思是將rs左移16位后再和sc進行判斷,所以這里很明顯是筆誤了。在OpenJDK的bug提交記錄上可以看到如下的JDK-8214427:
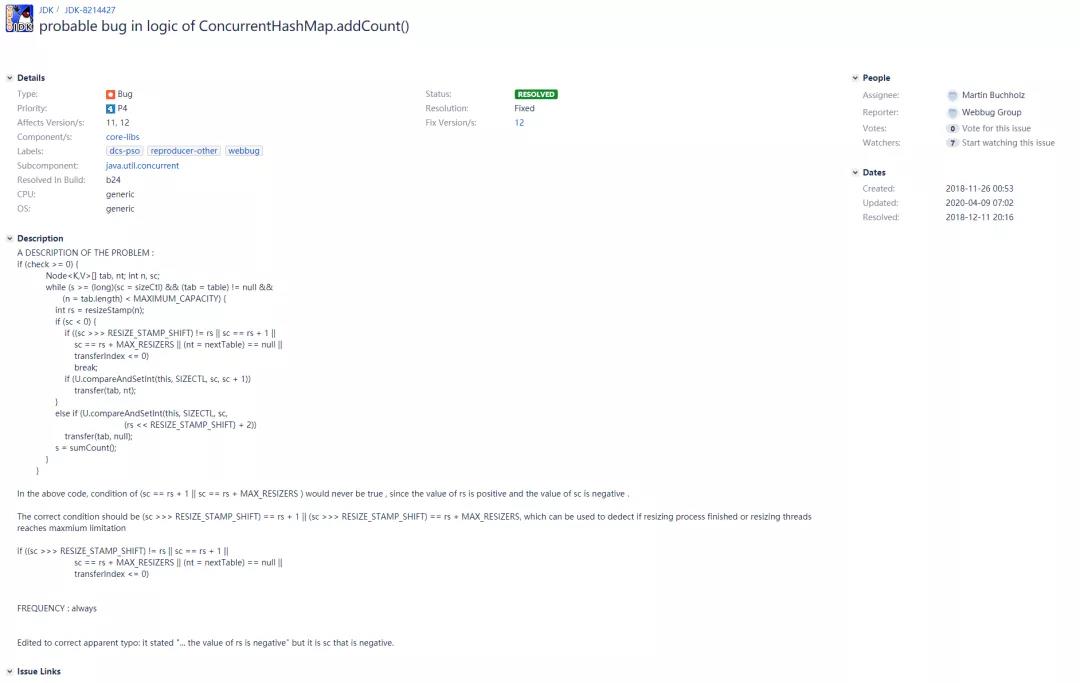
由上可以看到,這個bug在Java 12及之后的版本修復了,所以下面來看一下這塊改成了什么。以下是Java 14.0.2中的addCount方法的部分源碼:
1 private final void addCount(long x, int check) {
2 //...
3 if (check >= 0) {
4 Node<K,V>[] tab, nt;
5 int n, sc;
6 while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
7 (n = tab.length) < MAXIMUM_CAPACITY) {
8 int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;
9 if (sc < 0) {
10 if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||
11 (nt = nextTable) == null || transferIndex <= 0)
12 break;
13 if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1))
14 transfer(tab, nt);
15 } else if (U.compareAndSetInt(this, SIZECTL, sc, rs + 2))
16 transfer(tab, null);
17 s = sumCount();
18 }
19 }
20 }可以看到在上面第8行代碼處,rs已經改為了左移16位的結果(helpTransfer方法也一并改掉了,這里就不再看了)。但是令我不解的是:去掉了(sc >>> RESIZE_STAMP_SHIFT) != rs這個條件,該條件是為了確保當前線程和其他線程是在同一次擴容中,也就是判斷標記位是否相同。如果這個條件還有的話,按上面的寫法就應該變成了(sc >>> RESIZE_STAMP_SHIFT) != (rs >>> RESIZE_STAMP_SHIFT)。說實話我沒有搞懂Doug Lea把這個條件去掉的原因:

我注意到了在OpenJDK bug提交記錄上的另一個bug,JDK-8242464:
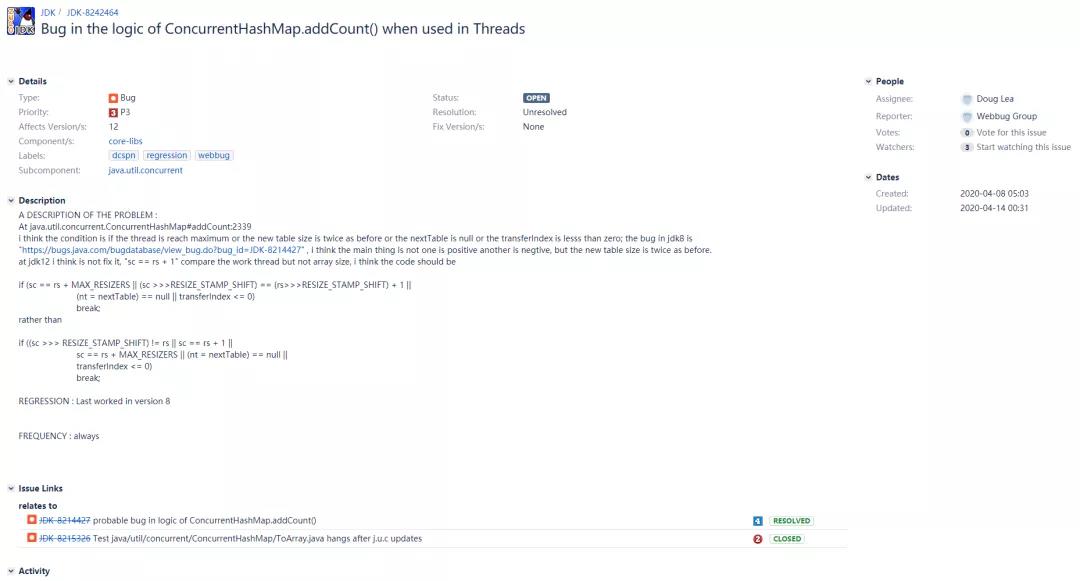
提交者的意思是說JDK-8214427最主要的問題是要考慮新數組容量變了的情況,而不是一個正數另一個負數的問題,Java 12中所做的更改并沒有解決問題。應該將sc == rs + 1改為(sc >>>RESIZE_STAMP_SHIFT) == (rs>>>RESIZE_STAMP_SHIFT) + 1(兩個標記位相差1,也就是說前導0差一位,也就意味著數組容量翻倍了,和我說的(sc >>> RESIZE_STAMP_SHIFT) != (rs >>> RESIZE_STAMP_SHIFT)這個條件的意思差不多),目前Doug Lea并沒有作出評論,該bug也是處于OPEN狀態(不好復現,且沒有提供完整報告,需要進一步評估)。其實要按照我的想法,在Java 12中應該改為(sc >>> RESIZE_STAMP_SHIFT) != (rs >>> RESIZE_STAMP_SHIFT) || sc == rs + 1,即把這兩種情況都寫上。
對多線程擴容邏輯的分析到這里就算是分析完了,后續只能一直跟進該bug的狀態和評論了(我已經將該問題提交到StackOverFlow上了,但截至到目前仍然沒有收到答復(https://stackoverflow.com/questions/63595464/why-has-this-condition-sc-resize-stamp-shift-rs-been-removed-in-jdk12))。
1 /**
2 * ConcurrentHashMap:
3 */
4 public V get(Object key) {
5 Node<K, V>[] tab;
6 Node<K, V> e, p;
7 int n, eh;
8 K ek;
9 /*
10 計算指定key的hash,注意,這里直接調用了key的hashCode方法,也就意味著如果傳進來的
11 key為null的話,會拋出空指針異常
12 */
13 int h = spread(key.hashCode());
14 //如果數組沒有初始化,或者計算出來的桶的位置為null(說明找不到這個key),就直接返回null
15 if ((tab = table) != null && (n = tab.length) > 0 &&
16 (e = tabAt(tab, (n - 1) & h)) != null) {
17 if ((eh = e.hash) == h) {
18 if ((ek = e.key) == key || (ek != null && key.equals(ek)))
19 /*
20 如果桶上第一個節點的hash值和要查找的hash值相同,并且key也是相同的話,
21 就直接返回(快速判斷模式)
22 */
23 return e.val;
24 } else if (eh < 0)
25 /*
26 eh < 0說明eh是一個特殊節點:正在遷移中的節點或樹節點,又或者是RESERVED節點,
27 此時會走find方法進行查找。而不同的節點會重寫find方法。也就是說,每種特殊節點
28 都有自己的尋找方式
29 */
30 return (p = e.find(h, key)) != null ? p.val : null;
31 /*
32 走到這里說明eh >= 0,即當前桶是一個正常的Node鏈表,那么遍歷鏈表上的每一個節點進行查找
33 (第一個節點不需要判斷了,因為在第17和18行代碼處已經判斷過了)
34 */
35 while ((e = e.next) != null) {
36 if (e.hash == h &&
37 ((ek = e.key) == key || (ek != null && key.equals(ek))))
38 return e.val;
39 }
40 }
41 return null;
42 }
43
44 /**
45 * 第30行代碼處:
46 * 最普通的Node節點的find方法,可以看出就是做個遍歷查找,判斷一下hash和key是否相同就行了
47 */
48 Node<K, V> find(int h, Object k) {
49 Node<K, V> e = this;
50 if (k != null) {
51 do {
52 K ek;
53 if (e.hash == h &&
54 ((ek = e.key) == k || (ek != null && k.equals(ek))))
55 return e;
56 } while ((e = e.next) != null);
57 }
58 return null;
59 }
60
61 /**
62 * 第30行代碼處:
63 * ForwardingNode節點的find方法
64 */
65 Node<K, V> find(int h, Object k) {
66 outer:
67 /*
68 注意,找遷移節點是在nextTable上找的,之所以沒有在當前數組中進行遍歷,
69 是因為當前就是要查找遷移中這種場景中的節點,而在遷移時setTabAt方法能保證
70 nextTable的內存可見性。如果nextTable上找不到也無所謂,再調一次get方法,
71 等擴容結束后就能找到了
72 */
73 for (Node<K, V>[] tab = nextTable; ; ) {
74 Node<K, V> e;
75 int n;
76 if (k == null || tab == null || (n = tab.length) == 0 ||
77 (e = tabAt(tab, (n - 1) & h)) == null)
78 /*
79 如果key為null,新數組為null或者計算出來的新數組桶的位置為null
80 (說明找不到這個key),就直接返回null(快速判斷模式)
81
82 注意:這里的tabAt取的是nextTable上的位置,所以說如果返回為null不代表著一定
83 就是找不到這個key,也可能是這個桶還沒有做遷移。但是無妨,下次再調用一次get方法,
84 等遷移做完了就能找到了
85
86 值得一提的是:跳進該方法時是ForwardingNode節點,說明此時正在遷移中
87 而走到該處nextTable卻可能為null,說明此時已經遷移完了,所以快速返回null
88 當然如果在下面的代碼執行中,遷移才做完,那么這個時候的快速判斷就不起作用了。但無妨,
89 后面會再次從頭往下進行判斷的
90 */
91 return null;
92 for (; ; ) {
93 int eh;
94 K ek;
95 if ((eh = e.hash) == h &&
96 ((ek = e.key) == k || (ek != null && k.equals(ek))))
97 //如果當前節點的hash和key都和要找的節點相同,就返回它
98 return e;
99 if (eh < 0) {
100 if (e instanceof ForwardingNode) {
101 /*
102 再次判斷一下是否是ForwardingNode節點,走到這里說明當前還在遷移中(可能還是
103 這次遷移也可能是下一次遷移了),那么就繼續從本方法的開頭處再次往下判斷(其實這里不去寫這個
104 分支也是沒問題的,直接走下面第128行代碼處的ForwardingNode節點的find方法
105 就行了。但是這樣就相當于遞歸了,后面會解釋為什么這里不用遞歸)
106
107 這里想去解釋一下上面說的下一次遷移的意思。如果此時正在遍歷鏈表上的節點,突然發現某一個節點由
108 普通的Node節點變為了ForwardingNode節點,這是怎么發生的呢?我所做的一種猜測是:
109 比如說一個鏈表上有4個節點:0,1,2,3。我判斷第一個節點的key和hash不是我想要的,
110 那么此時就會遍歷到第二個節點處也就是節點1。就在此刻,這個鏈表發生了擴容遷移,
111 遷移結束后,節點1可能被放在了2倍容量新數組的桶的第一個位置處。而不久后,又發生了一次擴容遷移,
112 即第二次遷移(注意這里的e是局部變量,所以能一直循環下去),那么它就會被包裝為ForwardingNode
113 節點(注意,雖然這里的e是局部變量,但是變成ForwardingNode節點的操作是通過Unsafe類中的
114 setTabAt方法來實現的(volatile語義,內存可見性),所以可以及時判斷出來這個節點已經變為了
115 ForwardingNode節點)
116
117 此時將tab更新一下,以便下次循環時候使用,也就是在說,tab此時會指向最新的nextTable,去進行查找
118 (對應于上面所說的情況,即下一次遷移時,這個tab更新的動作才有意義)
119 */
120 tab = ((ForwardingNode<K, V>) e).nextTable;
121 continue outer;
122 } else
123 /*
124 走到這里說明已經不是ForwardingNode節點了(本次遷移結束,
125 該節點已經變成其他的節點了),可能是紅黑樹節點也可能是
126 RESERVED節點,那么就調用它們各自的find方法進行查找
127 */
128 return e.find(h, k);
129 }
130 /*
131 走到這里eh >= 0,說明此時本次遷移結束(注意:如上面所說,可能還會發生下一次遷移)。當然如果在遍歷的過程中,
132 某個節點又變成了紅黑樹節點(其他線程添加節點觸發轉紅黑樹閾值)或者ForwardingNode節點(下一次擴容做遷移),
133 就又會去它們自己覆寫的find方法中進行查找(ForwardingNode節點不會遞歸find查找)
134 這里就可以說明一下,為什么ForwardingNode節點不去走遞歸?其實這里更多的意義在于優化。如上面所說,如果擴容
135 非常頻繁,在遍歷鏈表上的節點的時候,就可能會有很多節點變為了ForwardingNode,如果用遞歸的話可能會造成
136 遞歸層次非常深的情況出現(這里也沒有使用尾遞歸)。可能會出現StackOverflow,即使不出現,遞歸層次非常深
137 的話也不利于維護。所以為了避免這種情況的出現,就改用了標簽的方式來重進
138 */
139 if ((e = e.next) == null)
140 //遍歷到底也沒有找到,就直接返回null
141 return null;
142 }
143 }
144 }由上可以看出,即使是get方法,在ConcurrentHashMap中也是很復雜的,尤其是ForwardingNode節點,需要考慮到各種情況。
在put方法中,我們會用到CAS + synchronized + Unsafe類直接操作地址(volatile語義)的方式來保證并發下的插入安全,但是在get方法中,卻沒有發現任何的鎖資源或CAS的代碼出現,那么它是如何保證線程安全的呢?其實上面也分析了,table屬性是volatile修飾的,取桶位置也是用的tabAt方法(Unsafe類中直接拿取指定地址的數據(volatile語義,內存可見性)),這樣的話是能保證拿取到的數據永遠是當前這個時刻最新的數據的。同時get方法不用加鎖或CAS自旋,提高了并發讀的性能。
這里我想再提一點:不是說put方法加上了synchronized鎖之后,get方法就會被阻塞了。只有get方法中也去synchronized這個節點,才會被阻塞。但是從上面的源碼中可以看出,get方法沒有使用任何的加鎖機制,所以get方法是不會被阻塞的(如果get方法受put影響,從而會阻塞,那我就會懷疑Doug Lea的水平了。而且也不是所有的put操作都會synchronized,如源碼所示:如果計算的桶的位置上沒有節點的話,直接就CAS插入節點了。只有計算的桶的位置上有節點的話,才會synchronized)。
1 /**
2 * ConcurrentHashMap:
3 */
4 public V remove(Object key) {
5 return replaceNode(key, null, null);
6 }
7
8 final V replaceNode(Object key, V value, Object cv) {
9 //計算key的hash
10 int hash = spread(key.hashCode());
11 for (Node<K, V>[] tab = table; ; ) {
12 Node<K, V> f;
13 int n, i, fh;
14 if (tab == null || (n = tab.length) == 0 ||
15 (f = tabAt(tab, i = (n - 1) & hash)) == null)
16 //如果數組沒有初始化,或者計算出來的桶的位置為null(說明找不到這個key),就直接返回null
17 break;
18 else if ((fh = f.hash) == MOVED)
19 /*
20 和putVal方法一樣,如果當前這個桶正在被遷移中,就去幫助一起去擴容。等擴容完成后,
21 就更新一下tab,繼續下一次的循環
22 */
23 tab = helpTransfer(tab, f);
24 else {
25 //走到這里說明當前這個桶上有節點
26 V oldVal = null;
27 boolean validated = false;
28 //synchronized鎖住當前鏈表上的第一個節點,也就是鎖住了這個桶,以防其他線程操作
29 synchronized (f) {
30 //雙重檢查
31 if (tabAt(tab, i) == f) {
32 if (fh >= 0) {
33 //如果節點是普通的Node節點的話
34 validated = true;
35 for (Node<K, V> e = f, pred = null; ; ) {
36 K ek;
37 if (e.hash == hash &&
38 ((ek = e.key) == key ||
39 (ek != null && key.equals(ek)))) {
40 /*
41 如果桶上當前節點的hash值和要查找的hash值相同,并且key也是相同的話,
42 就記錄一下該節點的value為ev
43 */
44 V ev = e.val;
45 if (cv == null || cv == ev ||
46 (ev != null && cv.equals(ev))) {
47 /*
48 如果cv為null,或者其有值并且與ev相等,就將oldVal置為ev(從這里可以看出:
49 如果傳進來的cv有值的話,代表僅在要刪除的節點的值是cv的時候,才能進行刪除)
50 */
51 oldVal = ev;
52 if (value != null)
53 /*
54 如果value不為null,就將e的值賦值為value(這里的意思是:
55 傳進來的value如果不為null,那么就需要將找到的節點值替換為value,
56 這也就是本方法名中“replace”的含義)
57 */
58 e.val = value;
59 else if (pred != null)
60 /*
61 上面的if條件不滿足,說明當前是在做刪除節點的操作。而pred節點
62 代表上一個節點,如果其值不為null,說明當前節點不是桶上第一個節點
63 (因為pred節點是在下面進行賦值的)所以此時就將前一個節點的next指向
64 下一個節點,也就是將e節點從鏈表中剔除掉,等待GC
65 */
66 pred.next = e.next;
67 else
68 /*
69 否則就是要刪除的節點是當前桶上的第一個節點,此時就通過setTabAt方法
70 來將下一個節點賦值在當前桶的位置處,也就是將e節點從鏈表中剔除掉,等待GC
71 */
72 setTabAt(tab, i, e.next);
73 }
74 /*
75 走到這里說明傳進來的cv和要刪除的節點值不相等,就會返回null(在下面第116行代碼處
76 發現不等,因為當前這種情況下的oldVal仍為null。然后會break跳出第11行代碼處的
77 for循環從而返回null)
78 */
79 break;
80 }
81 /*
82 如果當前節點不是要刪除的節點,此時pred記錄的是當前節點,而下面會將當前節點指向下一個,
83 此時的pred就變為了上一個節點
84 */
85 pred = e;
86 if ((e = e.next) == null)
87 /*
88 如果鏈表上沒有要刪除的節點的話,最終也會返回null
89 (和上面第79行代碼處括號內的解釋是一樣的)
90 */
91 break;
92 }
93 } else if (f instanceof TreeBin) {
94 //如果節點是紅黑樹的話,就執行紅黑樹的刪除節點邏輯(紅黑樹的分析本文不做展開)
95 validated = true;
96 TreeBin<K, V> t = (TreeBin<K, V>) f;
97 TreeNode<K, V> r, p;
98 if ((r = t.root) != null &&
99 (p = r.findTreeNode(hash, key, null)) != null) {
100 V pv = p.val;
101 if (cv == null || cv == pv ||
102 (pv != null && cv.equals(pv))) {
103 oldVal = pv;
104 if (value != null)
105 p.val = value;
106 else if (t.removeTreeNode(p))
107 setTabAt(tab, i, untreeify(t.first));
108 }
109 }
110 }
111 }
112 }
113 //如果是普通節點或者是紅黑樹節點的話
114 if (validated) {
115 //并且找到了要替換或刪除的節點
116 if (oldVal != null) {
117 /*
118 同時如果傳進來的value為null,就說明此時是在做刪除操作,而不是在做替換操作
119 此時調用addCount方法,傳進去的第一個參數是-1,也就是將節點計數-1。而第二個參數
120 也為-1,是為了不去幫助擴容,因為在上面已經幫助擴容完成了
121 */
122 if (value == null)
123 addCount(-1L, -1);
124 //最后將舊值返回即可
125 return oldVal;
126 }
127 //如果沒找到要刪除的節點,就會break最終返回null
128 break;
129 }
130 }
131 }
132 return null;
133 } 1 /**
2 * ConcurrentHashMap:
3 */
4 public void clear() {
5 long delta = 0L;
6 int i = 0;
7 Node<K, V>[] tab = table;
8 //循環ConcurrentHashMap中的每一個桶
9 while (tab != null && i < tab.length) {
10 int fh;
11 //如前所示,通過tabAt方法來找到桶的位置
12 Node<K, V> f = tabAt(tab, i);
13 if (f == null)
14 //如果當前這個桶上沒有數據存在的話,就將i+1,也就是繼續清除下一個桶
15 ++i;
16 else if ((fh = f.hash) == MOVED) {
17 //和putVal方法一樣,如果當前這個桶正在被遷移中,就去幫助一起去擴容。等擴容完成后,就更新一下tab
18 tab = helpTransfer(tab, f);
19 //因為遷移過后,桶上的數據就又都變了,所以重置i為0,重新開始清除每一個新桶上的數據
20 i = 0;
21 } else {
22 //synchronized鎖住當前鏈表上的第一個節點,也就是鎖住了這個桶,以防其他線程操作
23 synchronized (f) {
24 //雙重檢查
25 if (tabAt(tab, i) == f) {
26 /*
27 如果是普通的Node節點,p就為f;
28 否則如果是紅黑樹節點,就進行強轉;
29 否則就為null
30 */
31 Node<K, V> p = (fh >= 0 ? f :
32 (f instanceof TreeBin) ?
33 ((TreeBin<K, V>) f).first : null);
34 //這里會遍歷桶上的所有鏈表或紅黑樹節點,并記錄數量在delta上
35 while (p != null) {
36 --delta;
37 p = p.next;
38 }
39 //通過setTabAt方法來將當前這個桶置為null(注意這里是i++),也就是在清除數據
40 setTabAt(tab, i++, null);
41 }
42 }
43 }
44 }
45 /*
46 清除完了數據之后,最后就是要更新一下計數了。這里會調用addCount方法,只不過這里傳進去的delta為負數,
47 比如說如果當前有16個節點,delta就是-16,有32個節點,delta就是-32。這樣最后計算出的節點個數就為初始值0了
48 至于這里傳進去的-1,也是為了不去幫助擴容,因為在上面已經幫助擴容完成了
49 */
50 if (delta != 0L)
51 addCount(delta, -1);
52 }到此,相信大家對“怎么理解ConcurrentHashMap”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





