溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么理解并掌握ConcurrentHashMap”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么理解并掌握ConcurrentHashMap”吧!
現在我們知道了,在實際項目中,我們是把HashMap作為容器來使用的。既然是容器,那就需要考慮這么幾個問題:
容器的容量大小,能夠支持存放多少個元素,一開始給多少合適呢?(初始容量問題)
指定了容器初始容量大小后,萬一元素太多,容器放不下了如何處理呢?(容器擴容、裝載因子問題)
針對上面的問題,我們來分析一下:
在HashMap中,默認的初始容量大小是16, 在實際項目中,我們可以考慮預估要存入的元素個數,根據元素個數設置合適的初始容量。減少HashMap動態擴容,減少重建哈希表,從而提升性能
/** * The default initial capacity - MUST be a power of two. * 默認初始容量,HashMap的容量最好是保持 2的n次方 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
HashMap裝載因子,默認是0.75。表示在HashMap中,當元素的個數超過:capacity * 0.75的時候,就會啟動動態擴容,每次擴容后容量大小都是之前的兩倍
裝載因子越大,表示空閑空間越小,對應的HashMap沖突的概率就會越大。在實際項目中,我們可以設置合適的裝載因子,提升HashMap性能
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
現在你已經知道了在項目中用好HashMap,需要考慮的一些問題:初始容量、裝載因子等。
接下來我們一起來看另外一個問題:如何解決hash沖突。關于hash沖突,單從應用HashMap來說,我們并不需要關心,畢竟大多數時候,我們都僅僅是使用HashMap,并不會考慮從0到1寫一個HashMap。但是我還是想建議你了解一下,關于整個世界的認知,我們都應該知其然,且知其所以然。
上一篇我們提到關于hash沖突,主要有兩種解決方案:開放尋址法,拉連法。但是當時我并沒有詳細說明,我們跳過了,現在我們一起來看一下,什么是開放尋址法?什么是拉鏈法?
我們知道HashMap的底層數據結構是數組,數組的容量是有限的(我們暫時不考慮擴容,因為擴容后容量也還是有限的,只是比起擴容前大一倍)。
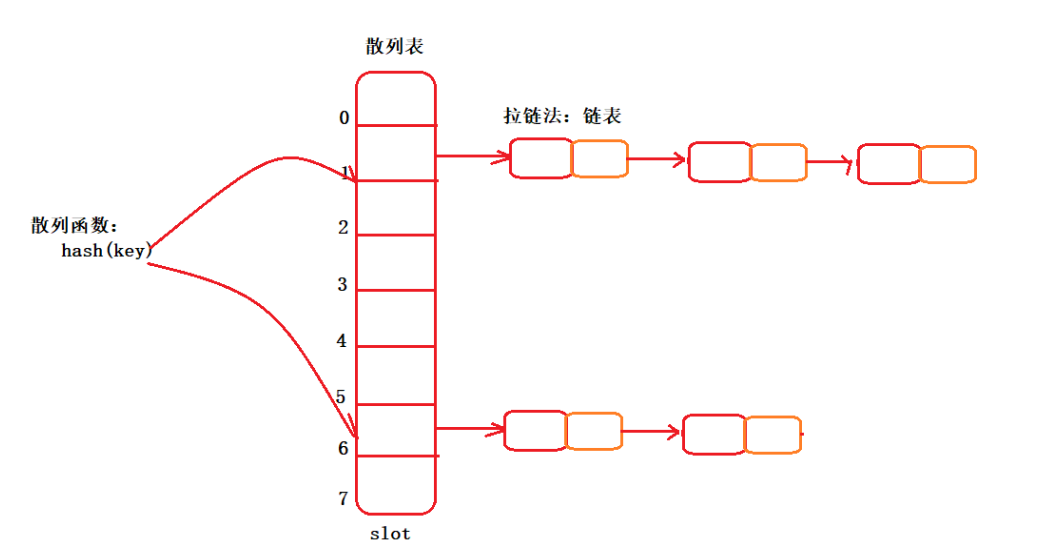
我們也知道HashMap的存儲是key/value鍵值對,需要將任意類型的key,通過散列函數hash(key),轉換成數組下標,與數組聯系起來,實現在O(1)時間復雜度下,查找目標元素。我們直觀的看一個圖:
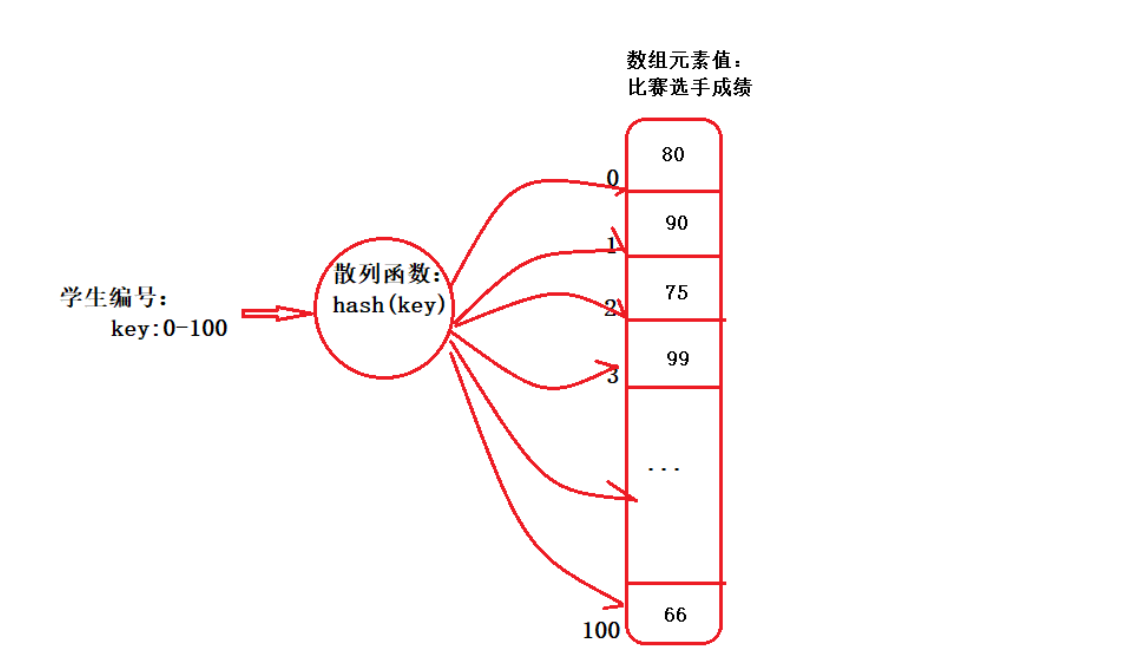
另外你還記得我們上一篇舉的示例嗎?hash(0+5)=5,hash(1+4)=5,hash(2+3)=5。假設當前目標數組下標是:5,那你也看到了,左右key:0+5,1+4,2+3并不相同,但是通過hash函數后,卻都指向了數組下標:5的位置。這就是hash沖突的由來。
好了,我又帶著你回顧了一遍hash沖突,現在我們重新回到解決hash沖突:開放尋址法、拉鏈法。
開放尋址法,是指當發生hash沖突后,比如說某個key,通過哈希函數hash(key),指向了數組下標5的位置。此時不巧下標5的位置已經存放了元素,即發生了hash沖突。
那么開放尋址法的做法,是從數組下標5的位置開始向后搜索,尋找到第一個空的,還未存放任何元素的下標位置,比如:8,作為當前key元素存放的位置。
我們來直觀的看一個圖:
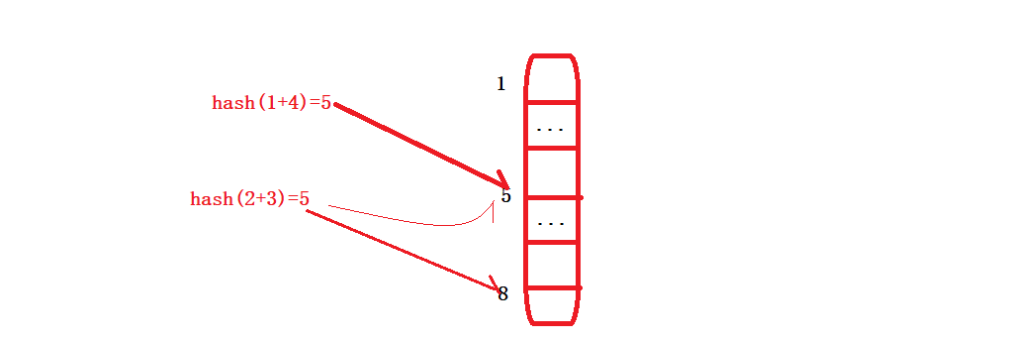
前一個元素hash(1+4)=5,占用了數組下標5的位置;
后一個元素hash(2+3)=5,雖然指向了數組下標5位置,但是此時下標5的位置已經被hash(1+4)元素占用,所以hash(2+3)元素只能繼續向后搜索,直到搜索到下標8的位置,發現下標8位置未使用,即作為元素hash(2+3)的位置。
你看,這就是開放尋址法。
拉鏈法,是指當發生hash沖突后,比如說某個key,通過哈希函數hash(key),指向了數組下標5的位置。此時不巧下標5的位置已經存放了元素,即發生了hash沖突。
那么拉鏈法的做法,不同于開放尋址法。它不需要從下標5的位置向后搜索,它是直接定位到下標5的位置,在此處通過鏈表,將發生hash沖突的多個元素連接起來,形成一個鏈表。
我們直觀的看一個圖:
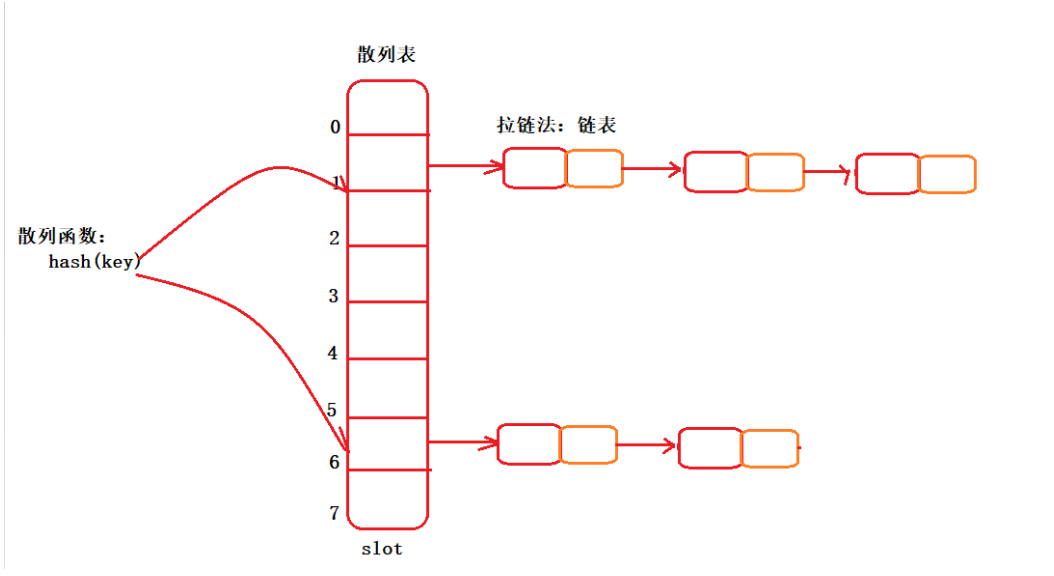
你看,這就是拉鏈法。
現在你已經知道了什么是hash沖突,以及hash沖突的兩種主要解決方案:開放尋址法、拉鏈法。
我們再來探討一個問題,什么場景下適合用開放尋址法?什么場景下適合用拉鏈法呢?
我們知道開放尋址法,最大的特點就是當發生hash沖突的時候,有向后搜索的操作。那么假設在存放大量目標元素對象的場景下,發生沖突的概率會非常大,每次發生沖突,都要向后搜索操作,會比較影響性能。
因此,開放尋址法適合在容器容量需求不大(即目標元素不多),hash沖突發生概率小的場景下,我建議你可以看一下ThreadLocalMap源碼,ThreadLocalMap即使用了開放尋址法解決hash沖突。
知道了開放尋址法的適用場景后,我們通過反向思考,即不難理解拉鏈法的使用場景了。拉鏈法適合在目標元素多,容器容量需求大、hash沖突發生概率大的業務場景。不用說,你已經知道了,我們一直的主角HashMap,ConcurrentHashMap都使用了拉鏈法解決hash沖突。
為了方便你理解ConcurrentHashMap,我們前面做了非常長的鋪墊,上一篇文章以及這篇文章的上半部分。
現在相信你已經理解了HashMap,那我們就開始進入ConcurrentHashMap的內容了。關于ConcurrentHashMap,大方向上你先有一個印象:ConcurrentHashMap它是HashMap的線程安全版本,它與HashMap一脈相傳,是師兄弟關系,只不過它是關門弟子,得了師傅的真傳,能力要更加強大一些。
上面這段話的意思,大致是想要告訴你,ConcurrentHashMap的底層實現原理,用了什么數據結構,如何解決hash沖突等都與HashMap一樣。我們只需要關心它是如何實現線程安全的就可以了。
那就讓我們開始吧,你需要注意一下,ConcurrentHashMap線程安全的實現,在jdk8版本,與jdk8以前的版本區別比較大,我們分開來說。
我們先來看ConcurrentHashMap在jdk8以前版本的實現,以下我的分析,和涉及到的源碼都是參考jdk7,你先留意一下。
談到線程安全,你肯定想到了,除了加鎖沒有別的手段,并且你還進一步想到了我們在鎖小節分享的:synchronized、或者Lock對象。
這里我們初步的想法是沒有任何問題的,想要實現線程安全:加鎖。但是我們還需要稍微往前思考一個問題:如果只是簡單的加鎖,那不就是Hashtable了嗎?java設計者的大神們,你們是不是閑著沒事干,順便多寫了一個ConcurrentHashMap呢?
答案肯定不是的,大神之所以稱之為大神,其中有一個區別于常人的特質,就是從來不做無用功!
那要這么說,我們就需要搞清楚有了Hashtable,為什么還需要一個ConcurrentHashMap?
我們先回顧一下,Hashtable是如何實現線程安全的,以及它存在什么問題?你還記得嗎,前面我們在高級并發編程系列十四(并發集合基礎)一篇,分享了Hashtable實現線程安全的方式,它是直接在每個操作方法上加了synchronized關鍵字。比如下圖,是我們熟悉的get方法:
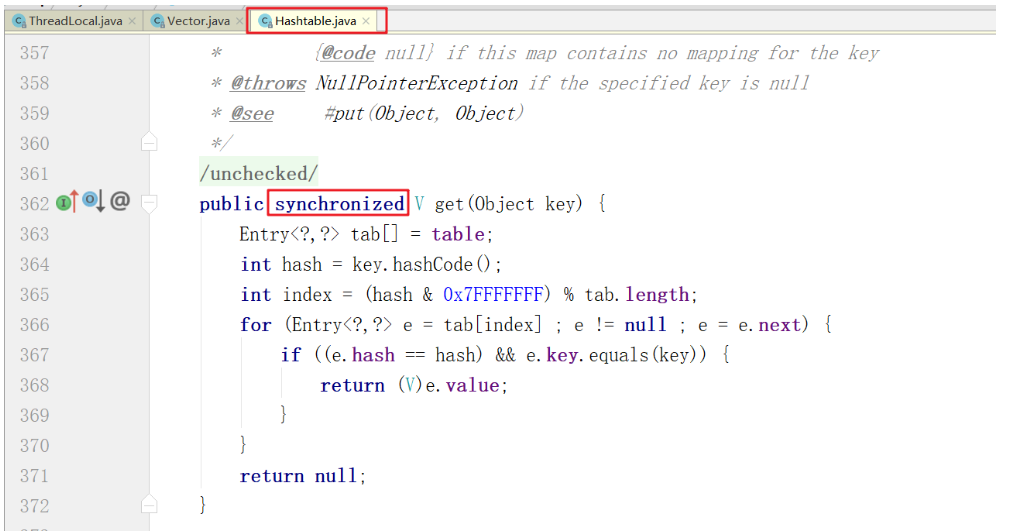
我們說直接在方法上加synchronized關鍵字,實現線程安全有什么問題呢?最大的問題就是鎖粒度太大,導致并發性能低,不足以應用在高并發業務場景。這也是為什么Hashtable出身以來,從未受寵的原因,你也不喜歡它對吧!千萬別說喜歡,非要喜歡的話怎么不見在你的項目中使用Hashtable呢?
說了這么多別人的不是,其目的都是為了襯托ConcurrentHashMap的主角光環。那你說說看吧,ConcurrentHashMap到底是如何實現線程安全,又是如何支持高并發的?我們從兩個方面來看。
既然要線程安全,那么鎖,肯定是要鎖的,基礎原理不變
另外要支持高并發業務場景,都加鎖了,還怎么實現高并發呢?這個地方你需要特別留意了,這里我將給你分享一個解決大、且復雜問題的通用思想,我們說:面對大的,復雜的業務問題,要想實現化繁為簡,唯一的手段即是拆分。今天我們說分布式,微服務化其核心都是拆字決!
那具體到ConcurrentHashMap中,它到底是如何拆的呢?它是這么拆的:通過分段鎖,即保障了線程安全,又提升了并發能力。
關于分段鎖,你可以這么去理解:原來是一個大鎖,限制了并發能力,因為只有一把鎖;現在我們把大鎖分成多把小鎖(ConcurrentHashMap默認是16個分段鎖),可以同時支持16個并發。
好了,文字分析我們差不多講明白了,接下來我通過源碼,以及畫一個圖,讓你更好的理解ConcurrentHashMap(你需要注意,我當前的jdk版本是7)。
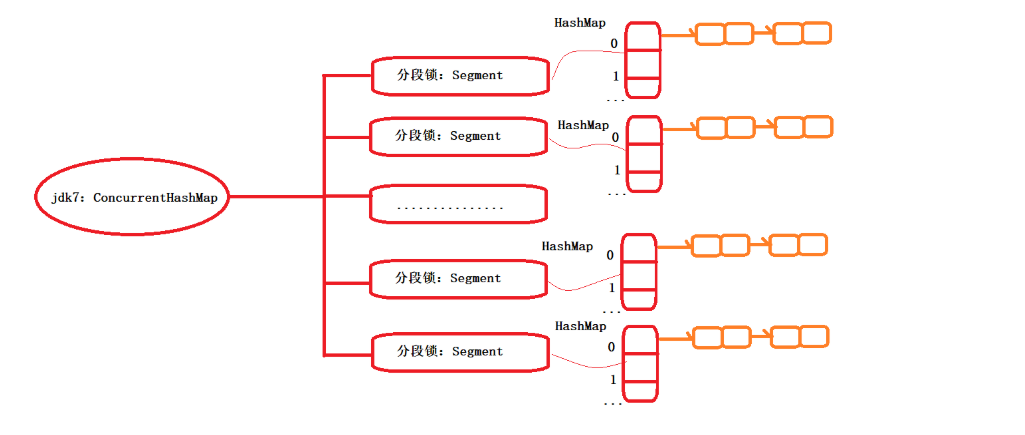
ConcurrentHashMap圖示:
ConcurrentHashMap源碼代表:
通過上圖我們直觀看到在jdk7中,ConcurrentHashMap它是通過分段鎖實現支持高并發,默認情況下,有16個分段鎖,其中每一個分段鎖中,即是一個HashMap。
接下來我們一起通過源碼,輔助理解上圖。
底層數據結構,數組
/** * The segments, each of which is a specialized hash table. */ final Segment<K,V>[] segments;
分段鎖Segment定義
/**
* Segments are specialized versions of hash tables. This
* subclasses from ReentrantLock opportunistically, just to
* simplify some locking and avoid separate construction.
* 每個Segment,原來就是一個ReentrantLock,好熟悉有沒有
*/
static final class Segment<K,V> extends ReentrantLock implements Serializable {
......
}分段鎖內部定義
/* *每個Segment,都是一個HashMap */ transient volatile HashEntry<K,V>[] table;
現在你已經知道了jdk7中的ConcurrentHashMap,我們說在jdk8中,它不再是分段鎖的設計思想了,它變了!
變成什么了呢?變成了cas + synchronized組合來保障線程安全,同時實現支持高并發。這里你還記得什么是cas嗎,如果不記得了,我推薦你看我這個系列的另外一篇文章:高級并發編程系列十二(一文搞懂cas)。
這里限于篇幅和側重關注點,我就不再詳細跟你說cas了,我只簡單帶你回顧一下cas的核心原理: cas本質上是不到黃河心不死,即不釋放cpu,循環操作,直到操作成功為止。
它的操作原理是三個值:內存值A、期望值B、更新值C。每次操作都會比較內存值A,是否等于期望值B、如果等于則將內存值更新成值C,操作成功;如果內存值A,不等于期望值B,則操作失敗,進行下一次循環操作 。
給你回顧完cas,我們主要再來關注為什么在jdk8中,ConcurrentHashMap會通過cas +synchronized組合,來替換jdk7中的分段鎖Segment呢?難道分段鎖它不香嗎?
我帶著你一起分享一下我的個人理解:
我們知道cas是一種無鎖化機制,大家都可以并行來搶占cpu(因為不加鎖嘛),自然是你可以搶,我也可以搶
那要這么說,cas就非常適合并發沖突小,加鎖臨界點(范圍)小的應用場景。
請說人話:什么是并發沖突小?簡單說就是讀多寫少的業務場景,即讀不需要加鎖,寫才需要加鎖
嗯,你這么說我就明白了,我們在項目中使用HashMap,正好都是讀多寫少,一次寫入,多次讀取的業務場景。比如本地緩存實現方案
因此cas+synchronized組合實現ConcurrentHashMap的方案,在實際應用中,會比分段鎖的實現方案,帶來更高的并發支持,性能會更好!
你看,這么說,你是不是也能理解jdk8中的ConcurrentHashMap了。最后我們還是看一個圖吧。
這個圖你見過了,就是我們上一篇中HashMap的圖。在jdk8中ConcurrentHashMap的底層數據結構上,與HashMap完全一樣,它只是增加了cas+synchronized操作。話不多說,我們看圖:
到此,相信大家對“怎么理解并掌握ConcurrentHashMap”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





