溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何理解并掌握HashMap”,在日常操作中,相信很多人在如何理解并掌握HashMap問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何理解并掌握HashMap”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
數據結構
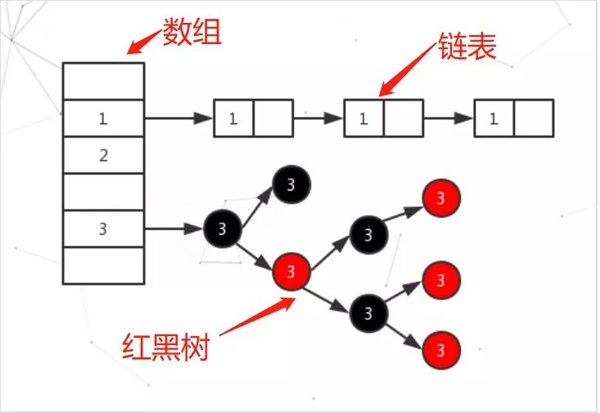
在 JDK1.8 中,HashMap 是由 數組+鏈表+紅黑樹構成(1.7版本是數組+鏈表)
當一個值中要存儲到HashMap中的時候會根據Key的值來計算出他的hash,通過hash值來確認存放到數組中的位置,如果發生hash沖突就以鏈表的形式存儲,當鏈表過長的話,HashMap會把這個鏈表轉換成紅黑樹來存儲,如圖所示:
在看源碼之前我們需要先看看一些基本屬性
//默認初始容量為16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默認負載因子為0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; //Hash數組(在resize()中初始化) transient Node<K,V>[] table; //元素個數 transient int size; //容量閾值(元素個數超過該值會自動擴容) int threshold;
table數組里面存放的是Node對象,Node是HashMap的一個內部類,用來表示一個key-value,源碼如下:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value);//^表示相同返回0,不同返回1 //Objects.hashCode(o)————>return o != null ? o.hashCode() : 0; } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; //Objects.equals(1,b)————> return (a == b) || (a != null && a.equals(b)); if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }總結
默認初始容量為16,默認負載因子為0.75
threshold = 數組長度 * loadFactor,當元素個數超過threshold(容量閾值)時,HashMap會進行擴容操作
table數組中存放指向鏈表的引用
這里需要注意的一點是table數組并不是在構造方法里面初始化的,它是在resize(擴容)方法里進行初始化的。
table數組長度永遠為2的冪次方
總所周知,HashMap數組長度永遠為2的冪次方(指的是table數組的大小),那你有想過為什么嗎?
首先我們需要知道HashMap是通過一個名為tableSizeFor的方法來確保HashMap數組長度永遠為2的冪次方的,源碼如下:
/*找到大于或等于 cap 的最小2的冪,用來做容量閾值*/ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }tableSizeFor的功能(不考慮大于最大容量的情況)是返回大于等于輸入參數且最近的2的整數次冪的數。比如10,則返回16。
該算法讓最高位的1后面的位全變為1。最后再讓結果n+1,即得到了2的整數次冪的值了。
讓cap-1再賦值給n的目的是另找到的目標值大于或等于原值。例如二進制1000,十進制數值為8。如果不對它減1而直接操作,將得到答案10000,即16。顯然不是結果。減1后二進制為111,再進行操作則會得到原來的數值1000,即8。通過一系列位運算大大提高效率。
那在什么地方會用到tableSizeFor方法呢?
答案就是在構造方法里面調用該方法來設置threshold,也就是容量閾值。
這里你可能又會有一個疑問:為什么要設置為threshold呢?
因為在擴容方法里第一次初始化table數組時會將threshold設置數組的長度,后續在講擴容方法時再介紹。
/*傳入初始容量和負載因子*/ public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " +loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }那么為什么要把數組長度設計為2的冪次方呢?
我個人覺得這樣設計有以下幾個好處:
1、當數組長度為2的冪次方時,可以使用位運算來計算元素在數組中的下標
HashMap是通過index=hash&(table.length-1)這條公式來計算元素在table數組中存放的下標,就是把元素的hash值和數組長度減1的值做一個與運算,即可求出該元素在數組中的下標,這條公式其實等價于hash%length,也就是對數組長度求模取余,只不過只有當數組長度為2的冪次方時,hash&(length-1)才等價于hash%length,使用位運算可以提高效率。
2、 增加hash值的隨機性,減少hash沖突
如果 length 為 2 的冪次方,則 length-1 轉化為二進制必定是 11111……的形式,這樣的話可以使所有位置都能和元素hash值做與運算,如果是如果 length 不是2的次冪,比如length為15,則length-1為14,對應的二進制為1110,在和hash 做與運算時,最后一位永遠都為0 ,浪費空間。
擴容
HashMap每次擴容都是建立一個新的table數組,長度和容量閾值都變為原來的兩倍,然后把原數組元素重新映射到新數組上,具體步驟如下:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
首先會判斷table數組長度,如果大于0說明已被初始化過,那么按當前table數組長度的2倍進行擴容,閾值也變為原來的2倍
若table數組未被初始化過,且threshold(閾值)大于0說明調用了HashMap(initialCapacity, loadFactor)構造方法,那么就把數組大小設為threshold
若table數組未被初始化,且threshold為0說明調用HashMap()構造方法,那么就把數組大小設為16,threshold設為16*0.75
接著需要判斷如果不是第一次初始化,那么擴容之后,要重新計算鍵值對的位置,并把它們移動到合適的位置上去,如果節點是紅黑樹類型的話則需要進行紅黑樹的拆分。
這里有一個需要注意的點就是在JDK1.8 HashMap擴容階段重新映射元素時不需要像1.7版本那樣重新去一個個計算元素的hash值,而是通過hash & oldCap的值來判斷,若為0則索引位置不變,不為0則新索引=原索引+舊數組長度,為什么呢?具體原因如下:
因為我們使用的是2次冪的擴展(指長度擴為原來2倍),所以,元素的位置要么是在原位置,要么是在原位置再移動2次冪的位置。因此,我們在擴充HashMap的時候,不需要像JDK1.7的實現那樣重新計算hash,只需要看看原來的hash值新增的那個bit是1還是0就好了,是0的話索引沒變,是1的話索引變成“原索引+oldCap

這點其實也可以看做長度為2的冪次方的一個好處,也是HashMap 1.7和1.8之間的一個區別,具體源碼如下:
/*擴容*/ final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; //1、若oldCap>0 說明hash數組table已被初始化 if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; }//按當前table數組長度的2倍進行擴容,閾值也變為原來的2倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; }//2、若數組未被初始化,而threshold>0說明調用了HashMap(initialCapacity)和HashMap(initialCapacity, loadFactor)構造器 else if (oldThr > 0) newCap = oldThr;//新容量設為數組閾值 else { //3、若table數組未被初始化,且threshold為0說明調用HashMap()構造方法 newCap = DEFAULT_INITIAL_CAPACITY;//默認為16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//16*0.75 } //若計算過程中,閾值溢出歸零,則按閾值公式重新計算 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; //創建新的hash數組,hash數組的初始化也是在這里完成的 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; //如果舊的hash數組不為空,則遍歷舊數組并映射到新的hash數組 if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null;//GC if (e.next == null)//如果只鏈接一個節點,重新計算并放入新數組 newTab[e.hash & (newCap - 1)] = e; //若是紅黑樹,則需要進行拆分 else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { //rehash————>重新映射到新數組 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; /*注意這里使用的是:e.hash & oldCap,若為0則索引位置不變,不為0則新索引=原索引+舊數組長度*/ if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }在擴容方法里面還涉及到有關紅黑樹的幾個知識點:
鏈表樹化
指的就是把鏈表轉換成紅黑樹,樹化需要滿足以下兩個條件:
鏈表長度大于等于8
table數組長度大于等于64
為什么table數組容量大于等于64才樹化?
因為當table數組容量比較小時,鍵值對節點 hash 的碰撞率可能會比較高,進而導致鏈表長度較長。這個時候應該優先擴容,而不是立馬樹化。
紅黑樹拆分
拆分就是指擴容后對元素重新映射時,紅黑樹可能會被拆分成兩條鏈表。
由于篇幅有限,有關紅黑樹這里就不展開了。
查找
HashMap的查找是非常快的,要查找一個元素首先得知道key的hash值,在HashMap中并不是直接通過key的hashcode方法獲取哈希值,而是通過內部自定義的hash方法計算哈希值,我們來看看其實現:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }(h = key.hashCode()) ^ (h >>> 16) 是為了讓高位數據與低位數據進行異或,變相的讓高位數據參與到計算中,int有 32 位,右移16位就能讓低16位和高16位進行異或,也是為了增加hash值的隨機性。
知道如何計算hash值后我們來看看get方法
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value;//hash(key)不等于key.hashCode } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; //指向hash數組 Node<K,V> first, e; //first指向hash數組鏈接的第一個節點,e指向下一個節點 int n;//hash數組長度 K k; /*(n - 1) & hash ————>根據hash值計算出在數組中的索引index(相當于對數組長度取模,這里用位運算進行了優化)*/ if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //基本類型用==比較,其它用euqals比較 if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { //如果first是TreeNode類型,則調用紅黑樹查找方法 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do {//向后遍歷 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((ee = e.next) != null); } } return null; }這里要注意的一點就是在HashMap中用 (n - 1) & hash 計算key所對應的索引index(相當于對數組長度取模,這里用位運算進行了優化),這點在上面已經說過了,就不再廢話了。
插入
我們先來看看插入元素的步驟:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
當table數組為空時,通過擴容的方式初始化table
通過計算鍵的hash值求出下標后,若該位置上沒有元素(沒有發生hash沖突),則新建Node節點插入
若發生了hash沖突,遍歷鏈表查找要插入的key是否已經存在,存在的話根據條件判斷是否用新值替換舊值
如果不存在,則將元素插入鏈表尾部,并根據鏈表長度決定是否將鏈表轉為紅黑樹
判斷鍵值對數量是否大于閾值,大于的話則進行擴容操作
先看完上面的流程,再來看源碼會簡單很多,源碼如下:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { Node<K,V>[] tab;//指向hash數組 Node<K,V> p;//初始化為table中第一個節點 int n, i;//n為數組長度,i為索引 //tab被延遲到插入新數據時再進行初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //如果數組中不包含Node引用,則新建Node節點存入數組中即可 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);//new Node<>(hash, key, value, next) else { Node<K,V> e; //如果要插入的key-value已存在,用e指向該節點 K k; //如果第一個節點就是要插入的key-value,則讓e指向第一個節點(p在這里指向第一個節點) if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //如果p是TreeNode類型,則調用紅黑樹的插入操作(注意:TreeNode是Node的子類) else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //對鏈表進行遍歷,并用binCount統計鏈表長度 for (int binCount = 0; ; ++binCount) { //如果鏈表中不包含要插入的key-value,則將其插入到鏈表尾部 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //如果鏈表長度大于或等于樹化閾值,則進行樹化操作 if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); break; } //如果要插入的key-value已存在則終止遍歷,否則向后遍歷 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //如果e不為null說明要插入的key-value已存在 if (e != null) { V oldValue = e.value; //根據傳入的onlyIfAbsent判斷是否要更新舊值 if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //鍵值對數量超過閾值時,則進行擴容 if (++size > threshold) resize(); afterNodeInsertion(evict);//也是空函數?回調?不知道干嘛的 return null; }從源碼也可以看出table數組是在第一次調用put方法后才進行初始化的。
這里還有一個知識點就是在JDK1.8版本HashMap是在鏈表尾部插入元素的,而在1.7版本里是插入鏈表頭部的,1.7版本這么設計的原因可能是作者認為新插入的元素使用到的頻率會比較高,插入頭部的話可以減少遍歷次數。
那為什么1.8改成尾插法了呢?主要是因為頭插法在多線程環境下可能會導致兩個節點互相引用,形成死循環,由于此文主要講解1.8版本,感興趣的小伙伴可以去看看1.7版本的源碼。
刪除
HashMap的刪除操作并不復雜,僅需三個步驟即可完成。
鴻蒙官方戰略合作共建——HarmonyOS技術社區
定位桶位置
遍歷鏈表找到相等的節點
第三步刪除節點
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; //1、定位元素桶位置 if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; // 如果鍵的值與鏈表第一個節點相等,則將 node 指向該節點 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { // 如果是 TreeNode 類型,調用紅黑樹的查找邏輯定位待刪除節點 if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { // 2、遍歷鏈表,找到待刪除節點 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((ee = e.next) != null); } } // 3、刪除節點,并修復鏈表或紅黑樹 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }注意:刪除節點后可能破壞了紅黑樹的平衡性質,removeTreeNode方法會對紅黑樹進行變色、旋轉等操作來保持紅黑樹的平衡結構,這部分比較復雜,感興趣的小伙伴可看下面這篇文章:紅黑樹詳解
遍歷
在工作中HashMap的遍歷操作也是非常常用的,也許有很多小伙伴喜歡用for-each來遍歷,但是你知道其中有哪些坑嗎?
看下面的例子,當我們在遍歷HashMap的時候,若使用remove方法刪除元素時會拋出ConcurrentModificationException異常
Map<String, Integer> map = new HashMap<>(); map.put("1", 1); map.put("2", 2); map.put("3", 3); for (String s : map.keySet()) { if (s.equals("2")) map.remove("2"); }這就是常說的fail-fast(快速失敗)機制,這個就需要從一個變量說起
transient int modCount;
在HashMap中有一個名為modCount的變量,它用來表示集合被修改的次數,修改指的是插入元素或刪除元素,可以回去看看上面插入刪除的源碼,在最后都會對modCount進行自增。
當我們在遍歷HashMap時,每次遍歷下一個元素前都會對modCount進行判斷,若和原來的不一致說明集合結果被修改過了,然后就會拋出異常,這是Java集合的一個特性,我們這里以keySet為例,看看部分相關源碼:
public Set<K> keySet() { Set<K> ks = keySet; if (ks == null) { ks = new KeySet(); keySet = ks; } return ks; } final class KeySet extends AbstractSet<K> { public final Iterator<K> iterator() { return new KeyIterator(); } // 省略部分代碼 } final class KeyIterator extends HashIterator implements Iterator<K> { public final K next() { return nextNode().key; } } /*HashMap迭代器基類,子類有KeyIterator、ValueIterator等*/ abstract class HashIterator { Node<K,V> next; //下一個節點 Node<K,V> current; //當前節點 int expectedModCount; //修改次數 int index; //當前索引 //無參構造 HashIterator() { expectedModCount = modCount; Node<K,V>[] t = table; current = next = null; index = 0; //找到第一個不為空的桶的索引 if (t != null && size > 0) { do {} while (index < t.length && (next = t[index++]) == null); } } //是否有下一個節點 public final boolean hasNext() { return next != null; } //返回下一個節點 final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException();//fail-fast if (e == null) throw new NoSuchElementException(); //當前的鏈表遍歷完了就開始遍歷下一個鏈表 if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } //刪除元素 public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false);//調用外部的removeNode expectedModCount = modCount; } }相關代碼如下,可以看到若modCount被修改了則會拋出ConcurrentModificationException異常。
if (modCount != expectedModCount) throw new ConcurrentModificationException();
那么如何在遍歷時刪除元素呢?
我們可以看看迭代器自帶的remove方法,其中最后兩行代碼如下:
removeNode(hash(key), key, null, false, false);//調用外部的removeNode expectedModCount = modCount;
意思就是會調用外部remove方法刪除元素后,把modCount賦值給expectedModCount,這樣的話兩者一致就不會拋出異常了,所以我們應該這樣寫:
Map<String, Integer> map = new HashMap<>(); map.put("1", 1); map.put("2", 2); map.put("3", 3); Iterator<String> iterator = map.keySet().iterator(); while (iterator.hasNext()){ if (iterator.next().equals("2")) iterator.remove(); }這里還有一個知識點就是在遍歷HashMap時,我們會發現遍歷的順序和插入的順序不一致,這是為什么?
在HashIterator源碼里面可以看出,它是先從桶數組中找到包含鏈表節點引用的桶。然后對這個桶指向的鏈表進行遍歷。遍歷完成后,再繼續尋找下一個包含鏈表節點引用的桶,找到繼續遍歷。找不到,則結束遍歷。這就解釋了為什么遍歷和插入的順序不一致
equasl和hashcode
為什么添加到HashMap中的對象需要重寫equals()和hashcode()方法?
簡單看個例子,這里以Person為例:
public class Person { Integer id; String name; public Person(Integer id, String name) { this.id = id; this.name = name; } @Override public boolean equals(Object obj) { if (obj == null) return false; if (obj == this) return true; if (obj instanceof Person) { Person person = (Person) obj; if (this.id == person.id) return true; } return false; } public static void main(String[] args) { Person p1 = new Person(1, "aaa"); Person p2 = new Person(1, "bbb"); HashMap<Person, String> map = new HashMap<>(); map.put(p1, "這是p1"); System.out.println(map.get(p2)); } }原生的equals方法是使用==來比較對象的
原生的hashCode值是根據內存地址換算出來的一個值
Person類重寫equals方法來根據id判斷是否相等,當沒有重寫hashcode方法時,插入p1后便無法用p2取出元素,這是因為p1和p2的哈希值不相等。
HashMap插入元素時是根據元素的哈希值來確定存放在數組中的位置,因此HashMap的key需要重寫equals和hashcode方法。
到此,關于“如何理解并掌握HashMap”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





