溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了云原生數據庫設計的方法是什么的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇云原生數據庫設計的方法是什么文章都會有所收獲,下面我們一起來看看吧。
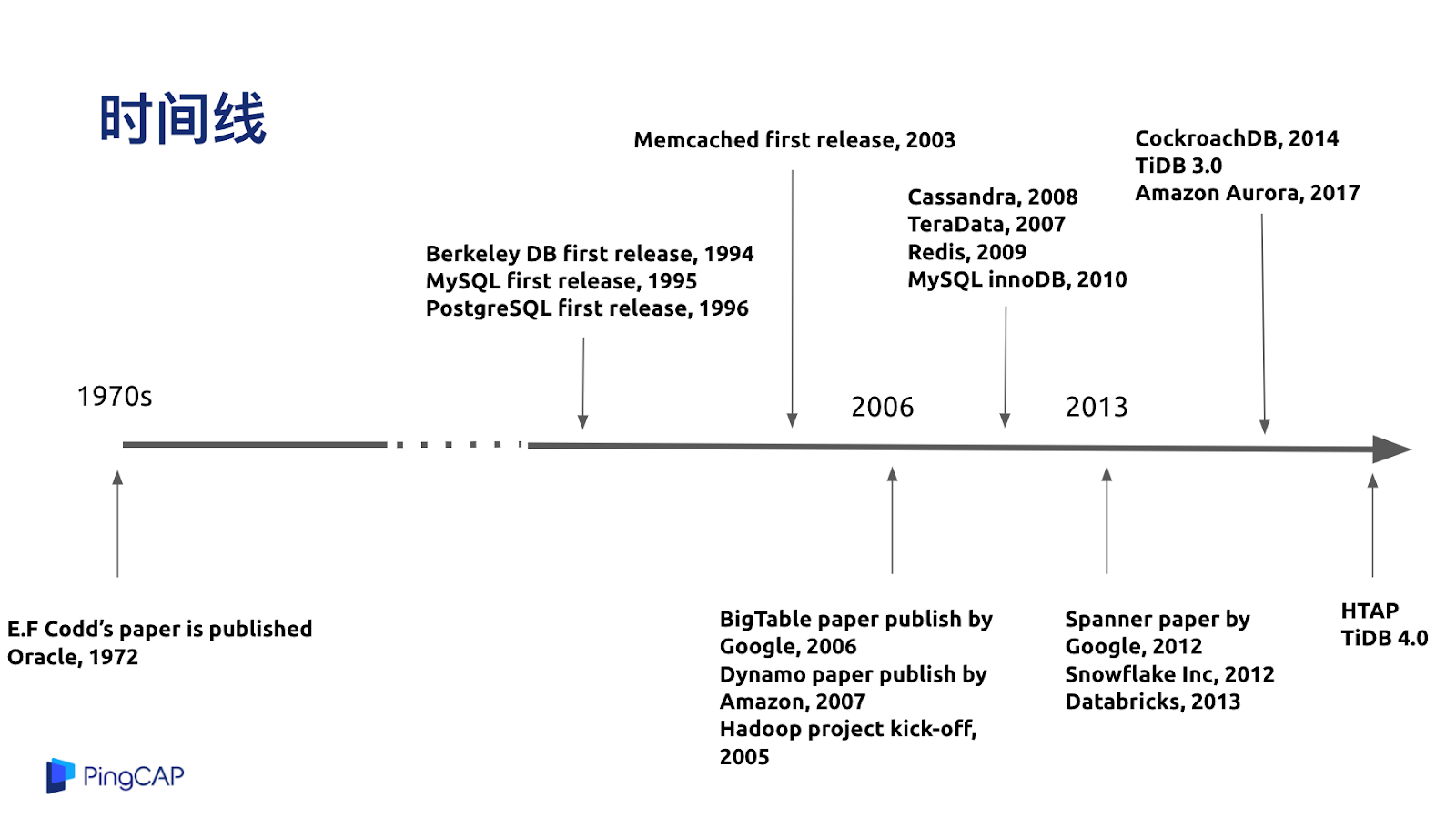
分布式數據庫的發展歷程,我按照年代進行了分類,到目前為止分成了四代。第一代是基于簡單的分庫分表或者中間件來做 Data Sharding 和 水平擴展。第二代系統是以 Cassandra、HBase 或者 MongoDB 為代表的 NoSQL 數據庫,一般多為互聯網公司在使用,擁有很好的水平擴展能力。
第三代系統我個人認為是以 Google Spanner 和 AWS Aurora 為代表的新一代云數據庫,他們的特點是融合了 SQL 和 NoSQL 的擴展能力,對業務層暴露了 SQL 的接口,在使用上可以做到水平的擴展。
第四代系統是以現在 TiDB 的設計為例,開始進入到混合業務負載的時代,一套系統擁有既能做交易也能處理高并發事務的特性,同時又能結合一些數據倉庫或者分析型數據庫的能力,所以叫 HTAP,就是融合型的數據庫產品。
未來是什么樣子,后面的分享我會介紹關于未來的一些展望。從整個時間線看,從 1970 年代發展到現在,database 也算是個古老的行業了,具體每個階段的發展情況,我就不過多展開。
對于數據庫中間件來說,第一代系統是中間件的系統,基本上整個主流模式有兩種,一種是在業務層做手動的分庫分表,比如數據庫的使用者在業務層里告訴你;北京的數據放在一個數據庫里,而上海的數據放在另一個數據庫或者寫到不同的表上,這種就是業務層手動的最簡單的分庫分表,相信大家操作過數據庫的朋友都很熟悉。
第二種通過一個數據庫中間件指定 Sharding 的規則。比如像用戶的城市、用戶的 ID、時間來做為分片的規則,通過中間件來自動的分配,就不用業務層去做。
這種方式的優點就是簡單。如果業務在特別簡單的情況下,比如說寫入或者讀取基本能退化成在一個分片上完成,在應用層做充分適配以后,延遲還是比較低的,而整體上,如果 workload 是隨機的,業務的 TPS 也能做到線性擴展。
但是缺點也比較明顯。對于一些比較復雜的業務,特別是一些跨分片的操作,比如說查詢或者寫入要保持跨分片之間的數據強一致性的時候就比較麻煩。另外一個比較明顯的缺點是它對于大型集群的運維是比較困難的,特別是去做一些類似的表結構變更之類的操作。想象一下如果有一百個分片,要去加一列或者刪一列,相當于要在一百臺機器上都執行操作,其實很麻煩。
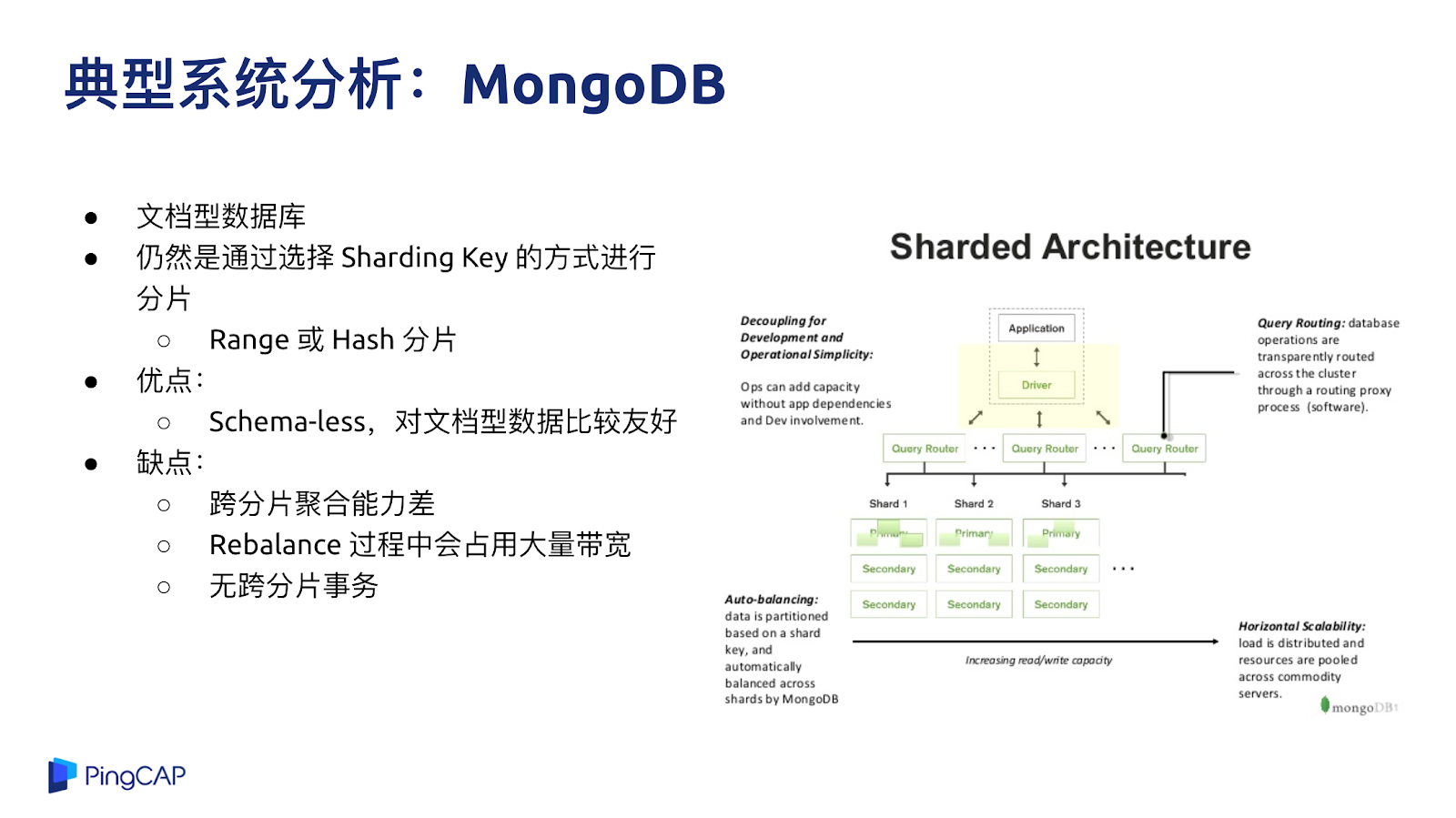
在 2010 年前后,好多互聯網公司都發現了這個大的痛點,仔細思考了業務后,他們發現業務很簡單,也不需要 SQL 特別復雜的功能,于是就發展出了一個流派就是 NoSQL 數據庫。NoSQL 的特點就是放棄到了高級的 SQL 能力,但是有得必有失,或者說放棄掉了東西總能換來一些東西,NoSQL 換來的是一個對業務透明的、強的水平擴展能力,但反過來就意味著你的業務原來是基于 SQL 去寫的話,可能會帶來比較大的改造成本,代表的系統有剛才我說到的 MongoDB、Cassandra、HBase 等。
最有名的系統就是 MongoDB,MongoDB 雖然也是分布式,但仍然還是像分庫分表的方案一樣,要選擇分片的 key,他的優點大家都比較熟悉,就是沒有表結構信息,想寫什么就寫什么,對于文檔型的數據比較友好,但缺點也比較明顯,既然選擇了 Sharding Key,可能是按照一個固定的規則在做分片,所以當有一些跨分片的聚合需求的時候會比較麻煩,第二是在跨分片的 ACID 事務上沒有很好的支持。
HBase 是 Hadoop 生態下的比較有名的分布式 NoSQL 數據庫,它是構建在 HDFS 之上的一個 NoSQL 數據庫。Cassandra 是一個分布式的 KV 數據庫,其特點是在 KV 操作上提供多種一致性模型,缺點與很多 NoSQL 的問題一樣,包括運維的復雜性, KV 的接口對于原有業務改造的要求等。
剛才說過 Sharding 或者分庫分表,NoSQL 也好,都面臨著一個業務的侵入性問題,如果你的業務是重度依賴 SQL,那么用這兩種方案都是很不舒適的。于是一些技術比較前沿的公司就在思考,能不能結合傳統數據庫的優點,比如 SQL 表達力,事務一致性等特性,但是又跟 NoSQL 時代好的特性,比如擴展性能夠相結合發展出一種新的、可擴展的,但是用起來又像單機數據庫一樣方便的系統。在這個思路下就誕生出了兩個流派,一個是 Spanner,一個是 Aurora,兩個都是頂級的互聯網公司在面臨到這種問題時做出的一個選擇。
Shared Nothing 這個流派是以 Google Spanner 為代表,好處是在于可以做到幾乎無限的水平擴展,整個系統沒有端點,不管是 1 個 T、10 個 T 或者 100 個 T,業務層基本上不用擔心擴展能力。第二個好處是他的設計目標是提供強 SQL 的支持,不需要指定分片規則、分片策略,系統會自動的幫你做擴展。第三是支持像單機數據庫一樣的強一致的事務,可以用來支持金融級別的業務。
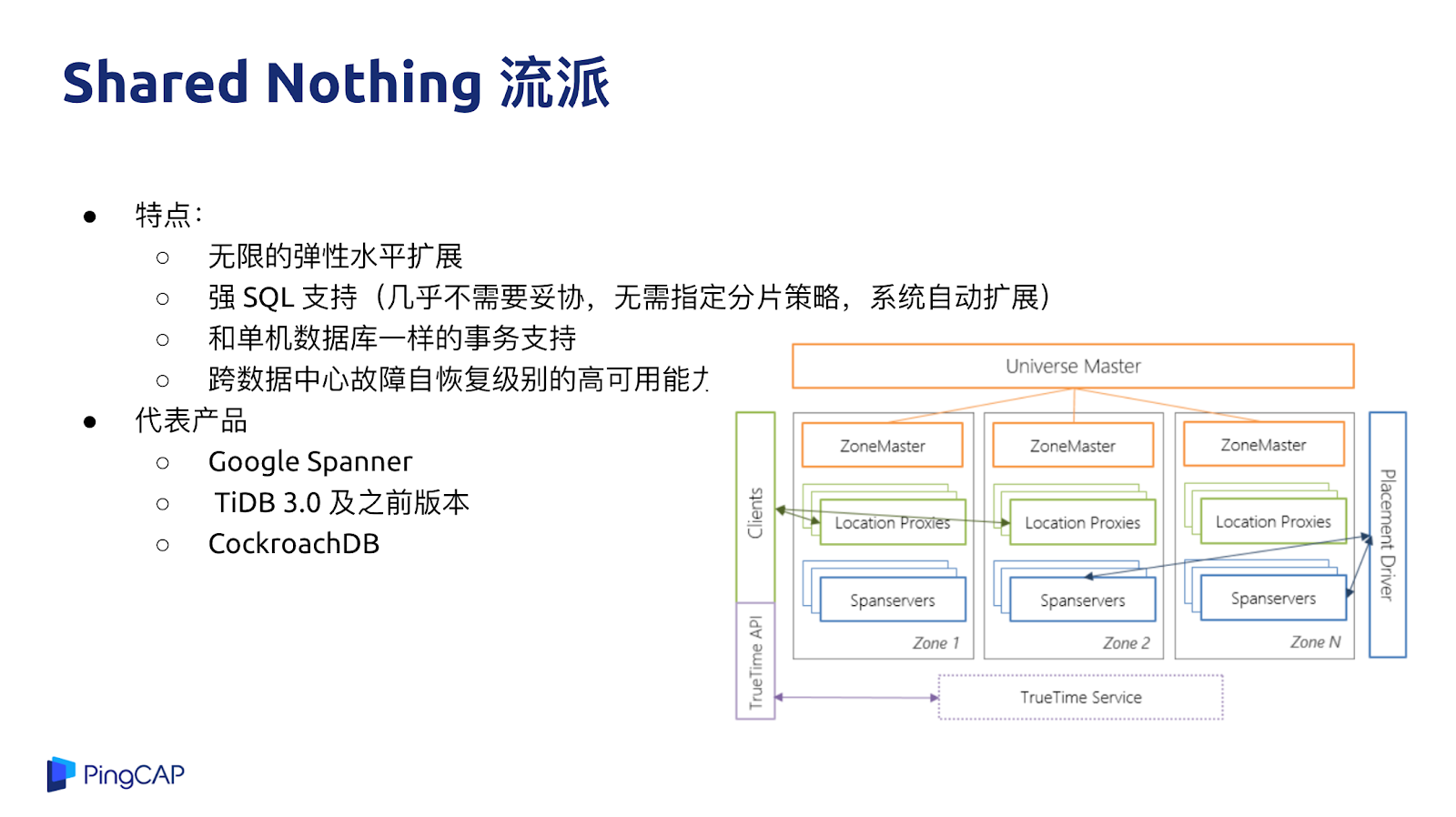
代表產品就是 Spanner 與 TiDB,這類系統也有一些缺點,從本質上來說一個純分布式數據庫,很多行為沒有辦法跟單機行為一模一樣。舉個例子,比如說延遲,單機數據庫在做交易事務的時候,可能在單機上就完成了,但是在分布式數據庫上,如果要去實現同樣的一個語義,這個事務需要操作的行可能分布在不同的機器上,需要涉及到多次網絡的通信和交互,響應速度和性能肯定不如在單機上一次操作完成,所以在一些兼容性和行為上與單機數據庫還是有一些區別的。即使是這樣,對于很多業務來說,與分庫分表相比,分布式數據庫還是具備很多優勢,比如在易用性方面還是比分庫分表的侵入性小很多。
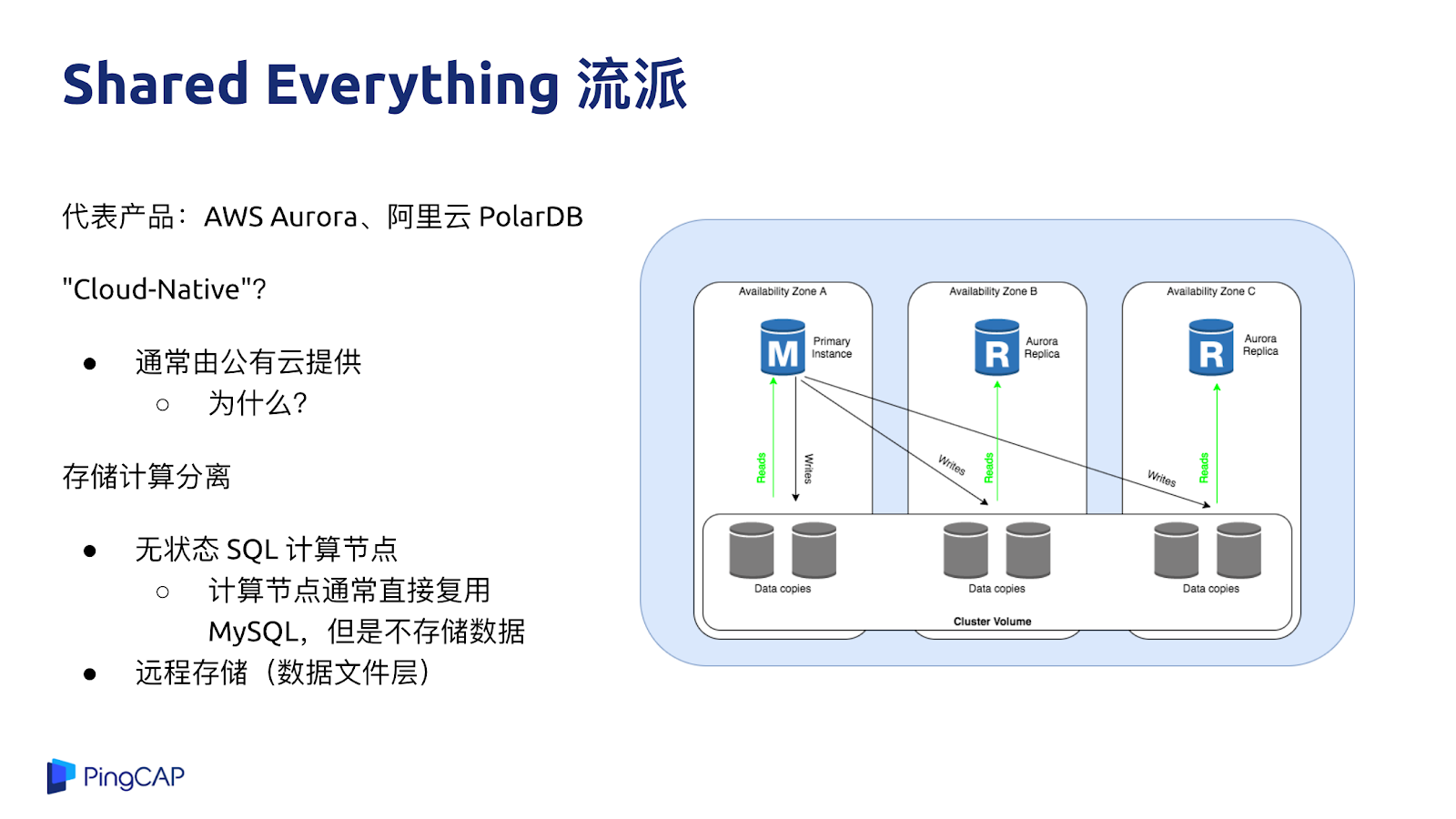
第二種流派就是 Shared Everything 流派,代表有 AWS Aurora、阿里云的 PolarDB,很多數據庫都定義自己是 Cloud-Native Database,但我覺得這里的 Cloud-Native 更多是在于通常這些方案都是由公有云服務商來提供的,至于本身的技術是不是云原生,并沒有一個統一的標準。從純技術的角度來去說一個核心的要點,這類系統的計算與存儲是徹底分離的,計算節點與存儲節點跑在不同機器上,存儲相當于把一個 MySQL 跑在云盤上的感覺,我個人認為類似 Aurora 或者 PolarDB 的這種架構并不是一個純粹的分布式架構。
原來 MySQL 的主從復制都走 Binlog,Aurora 作為一種在云上 Share Everything Database 的代表,Aurora 的設計思路是把整個 IO 的 flow 只通過 redo log 的形式來做復制,而不是通過整個 IO 鏈路打到最后 Binlog,再發到另外一臺機器上,然后再 apply 這個 Binlog,所以 Aurora 的 IO 鏈路減少很多,這是一個很大的創新。
日志復制的單位變小,意味著我發過去的只有 Physical log,不是 Binlog,也不是直接發語句過去,直接發物理的日志能代表著更小的 IO 的路徑以及更小的網絡包,所以整個數據庫系統的吞吐效率會比傳統的 MySQL 的部署方案好很多。
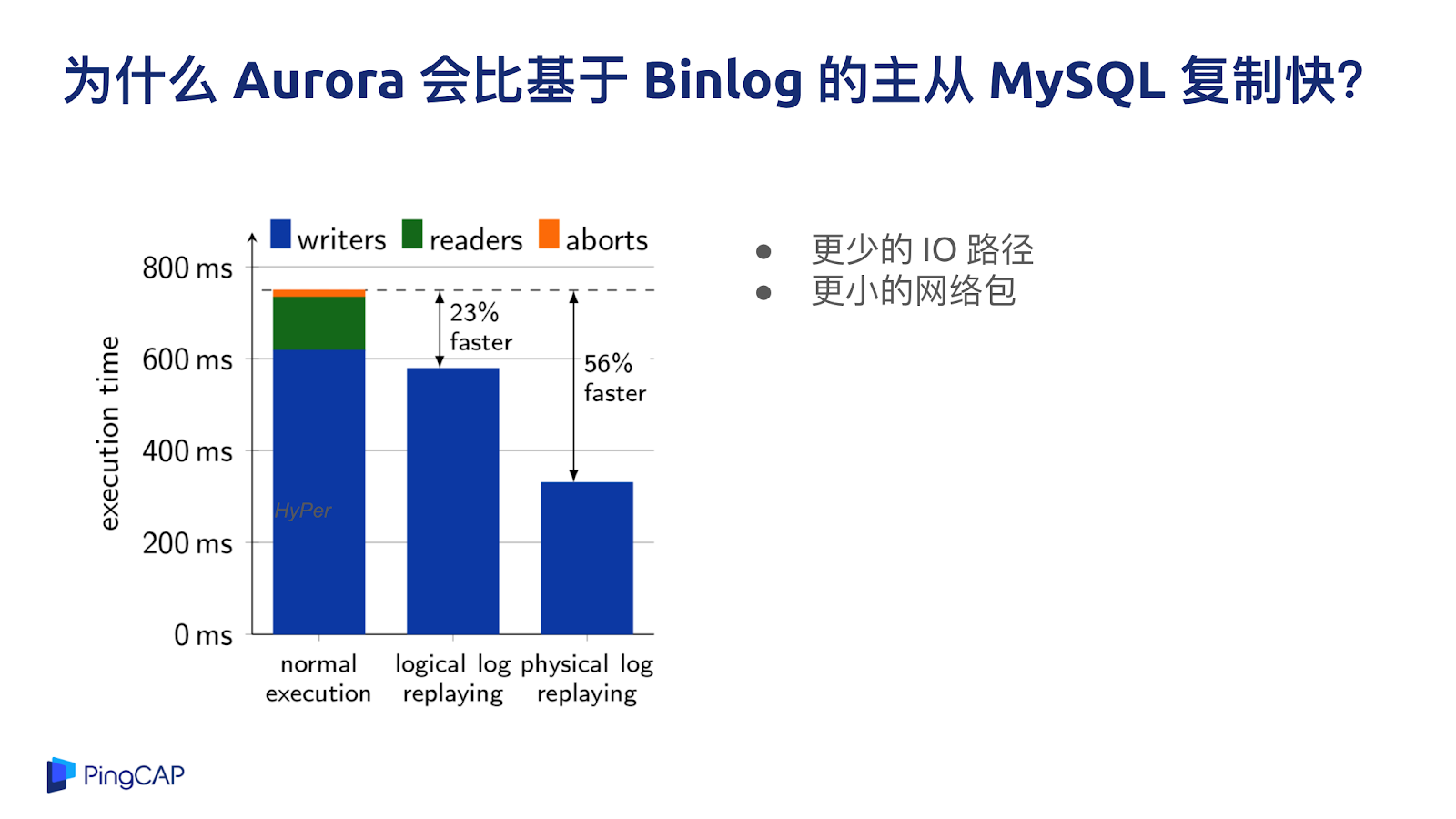
Aurora 的優勢是 100% 兼容 MySQL,業務兼容性好,業務基本上不用改就可以用,而且對于一些互聯網的場景,對一致性要求不高的話,數據庫的讀也可以做到水平擴展,不管是 Aurora 也好,PolarDB 也好,讀性能是有上限的。
Aurora 的短板大家也能看得出來,本質上這還是一個單機數據庫,因為所有數據量都是存儲在一起的,Aurora 的計算層其實就是一個 MySQL 實例,不關心底下這些數據的分布,如果有大的寫入量或者有大的跨分片查詢的需求,如果要支持大數據量,還是需要分庫分表,所以 Aurora 是一款更好的云上單機數據庫。
第四代系統就是新形態的 HTAP 數據庫,英文名稱是 Hybrid Transactional and Analytical Processing,通過名字也很好理解,既可以做事務,又可以在同一套系統里面做實時分析。HTAP 數據庫的優勢是可以像 NoSQL 一樣具備無限水平擴展能力,像 NewSQL 一樣能夠去做 SQL 的查詢與事務的支持,更重要的是在混合業務等復雜的場景下,OLAP 不會影響到 OLTP 業務,同時省去了在同一個系統里面把數據搬來搬去的煩惱。目前,我看到在工業界基本只有 TiDB 4.0 加上 TiFlash 這個架構能夠符合上述要求。
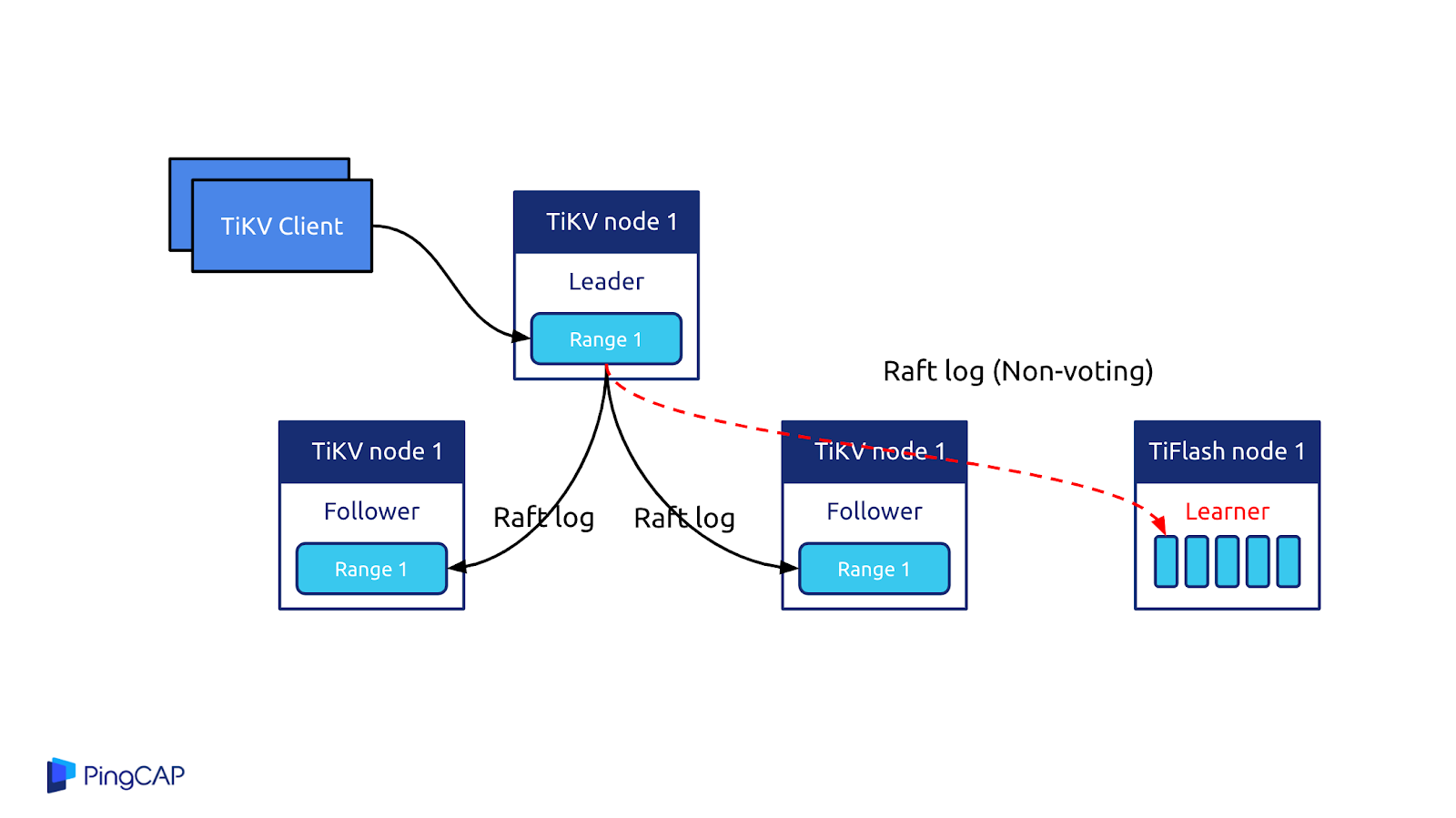
為什么 TiDB 能夠實現 OLAP 和 OLTP 的徹底隔離,互不影響?因為 TiDB 是計算和存儲分離的架構,底層的存儲是多副本機制,可以把其中一些副本轉換成列式存儲的副本。OLAP 的請求可以直接打到列式的副本上,也就是 TiFlash 的副本來提供高性能列式的分析服務,做到了同一份數據既可以做實時的交易又做實時的分析,這是 TiDB 在架構層面的巨大創新和突破。
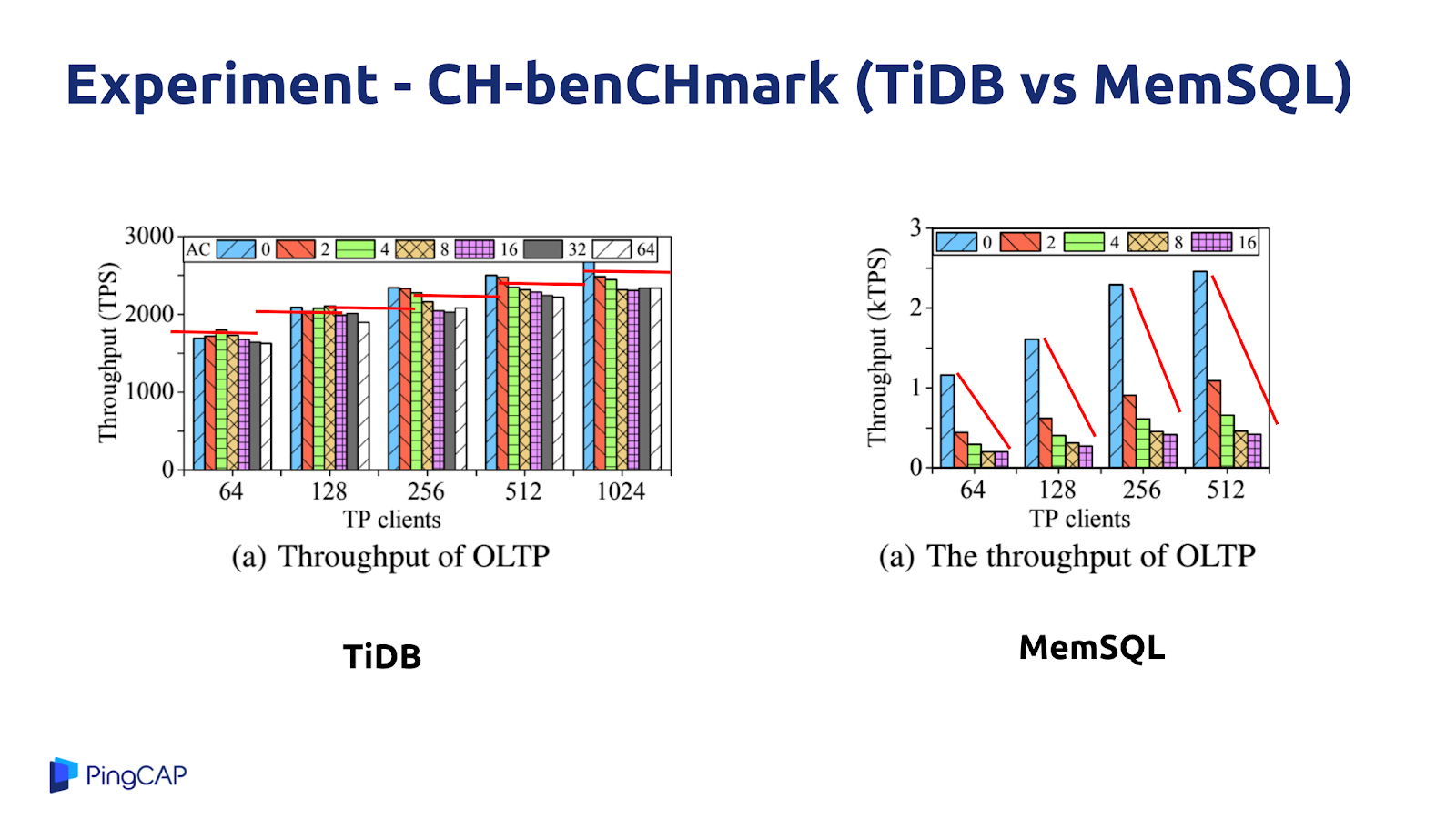
下圖是 TiDB 的測試結果,與 MemSQL 進行了對比,根據用戶場景構造了一種 workload,橫軸是并發數,縱軸是 OLTP 的性能,藍色、黃色、綠色這些是 OLAP 的并發數。這個實驗的目的就是在一套系統上既跑 OLTP 又跑 OLAP,同時不斷提升 OLTP 和 OLAP 的并發壓力,從而查看這兩種 workload 是否會互相影響。可以看到在 TiDB 這邊,同時加大 OLTP 和 OLAP 的并發壓力,這兩種 workload 的性能表現沒有什么明顯變化,幾乎是差不多的。但是,同樣的實驗發生在 MemSQL 上,大家可以看到 MemSQL 的性能大幅衰減,隨著 OLAP 的并發數變大,OLTP 的性能下降比較明顯。
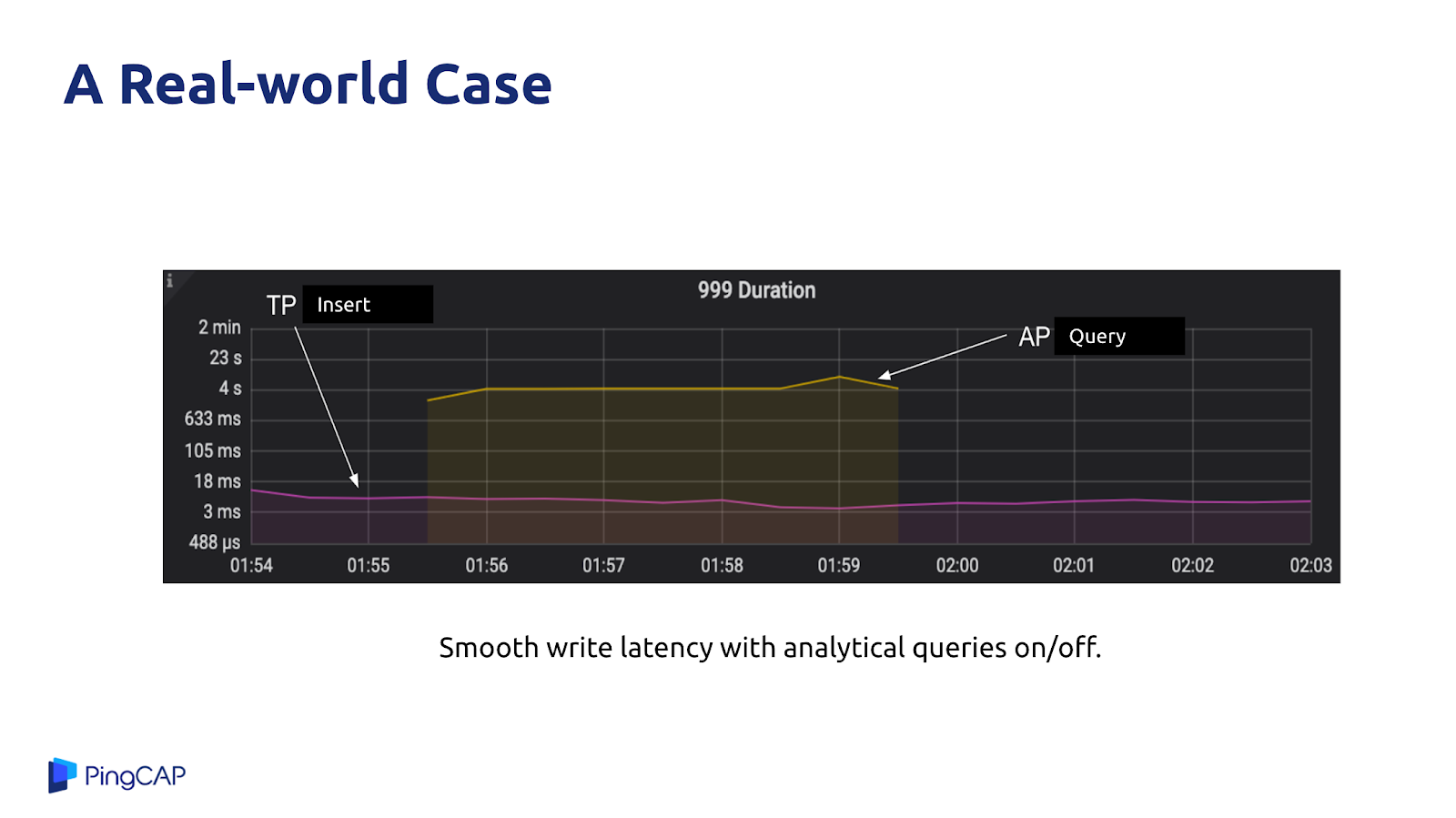
接下來是 TiDB 在一個用戶實際業務場景的例子,在進行 OLAP 業務的查詢的時候,OLTP 業務仍然可以實現平滑的寫入操作,延遲一直維持在較低的水平。
Snowflake 是一個 100% 構建在云上的數據倉庫系統,底層的存儲依賴 S3,基本上每個公有云都會提供類似 S3 這樣的對象存儲服務,Snowflake 也是一個純粹的計算與存儲分離的架構,在系統里面定義的計算節點叫 Virtual Warehouse,可以認為就是一個個 EC2 單元,本地的緩存有日志盤,Snowflake 的主要數據存在 S3 上,本地的計算節點是在公有云的虛機上。
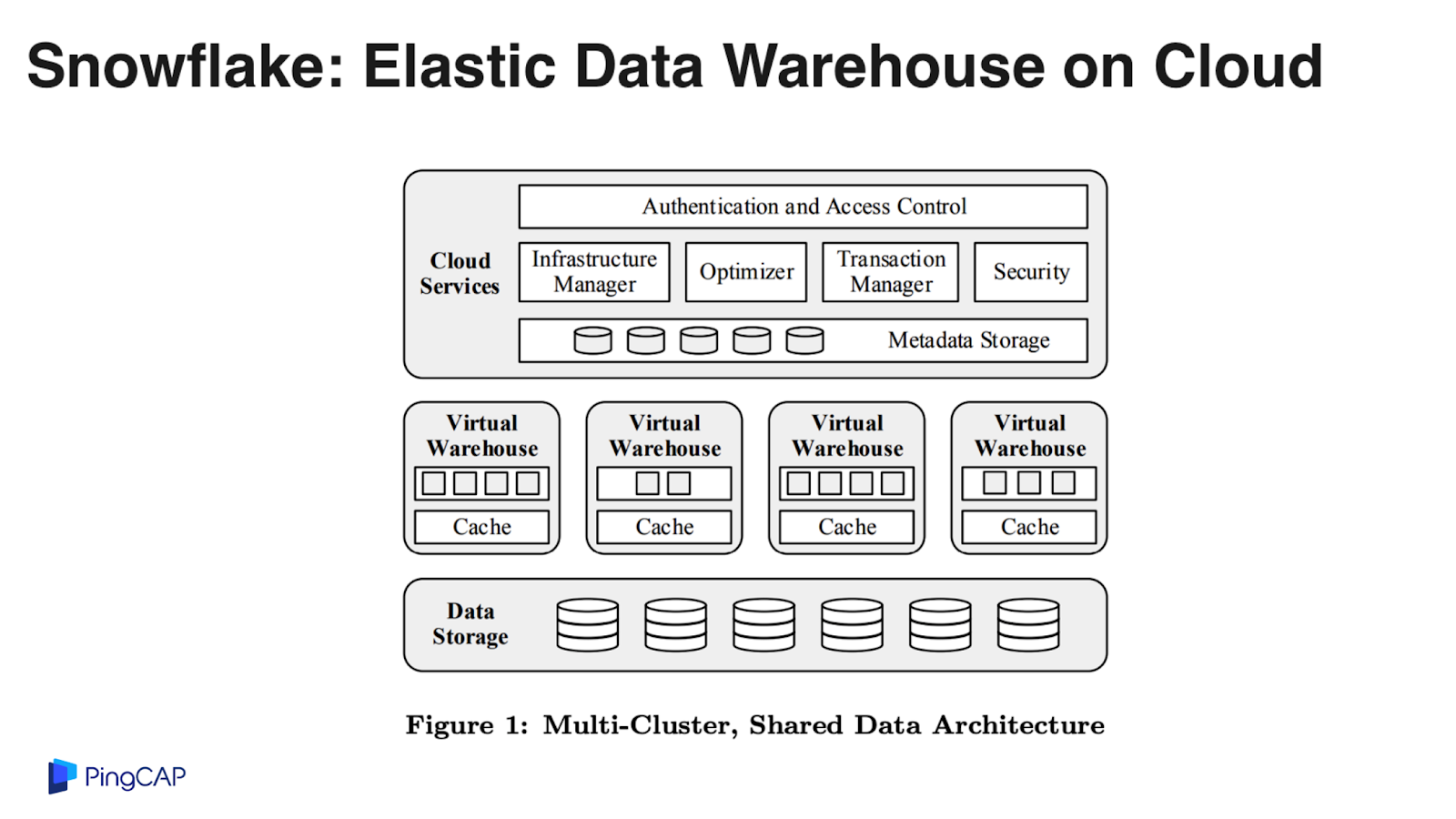
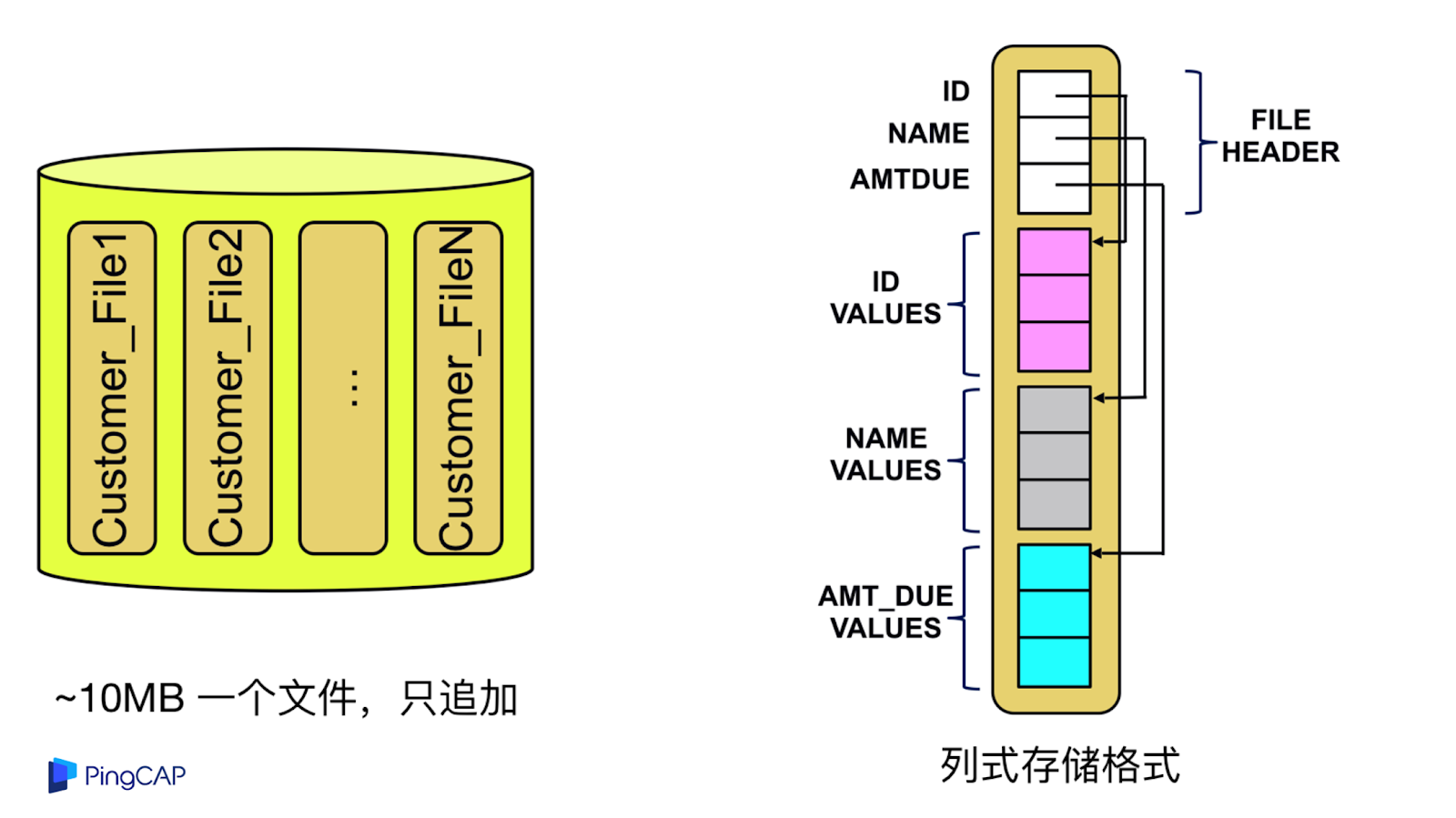
這是 Snowflake 在 S3 里面存儲的數據格式的特點,每一個 S3 的對象是 10 兆一個文件,只追加,每一個文件里面包含源信息,通過列式的存儲落到磁盤上。
Snowflake 這個系統最重要的一個閃光點就是對于同一份數據可以分配不同的計算資源進行計算,比如某個 query 可能只需要兩臺機器,另外一個 query 需要更多的計算資源,但是沒關系,實際上這些數據都在 S3 上面,簡單來說兩臺機器可以掛載同一塊磁盤分別去處理不同的工作負載,這就是一個計算與存儲解耦的重要例子。
第二個系統是 BigQuery,BigQuery 是 Google Cloud 上提供的大數據分析服務,架構設計上跟 Snowflake 有點類似。BigQuery 的數據存儲在谷歌內部的分布式文件系統 Colossus 上面,Jupiter 是內部的一個高性能網絡,上面這個是谷歌的計算節點。
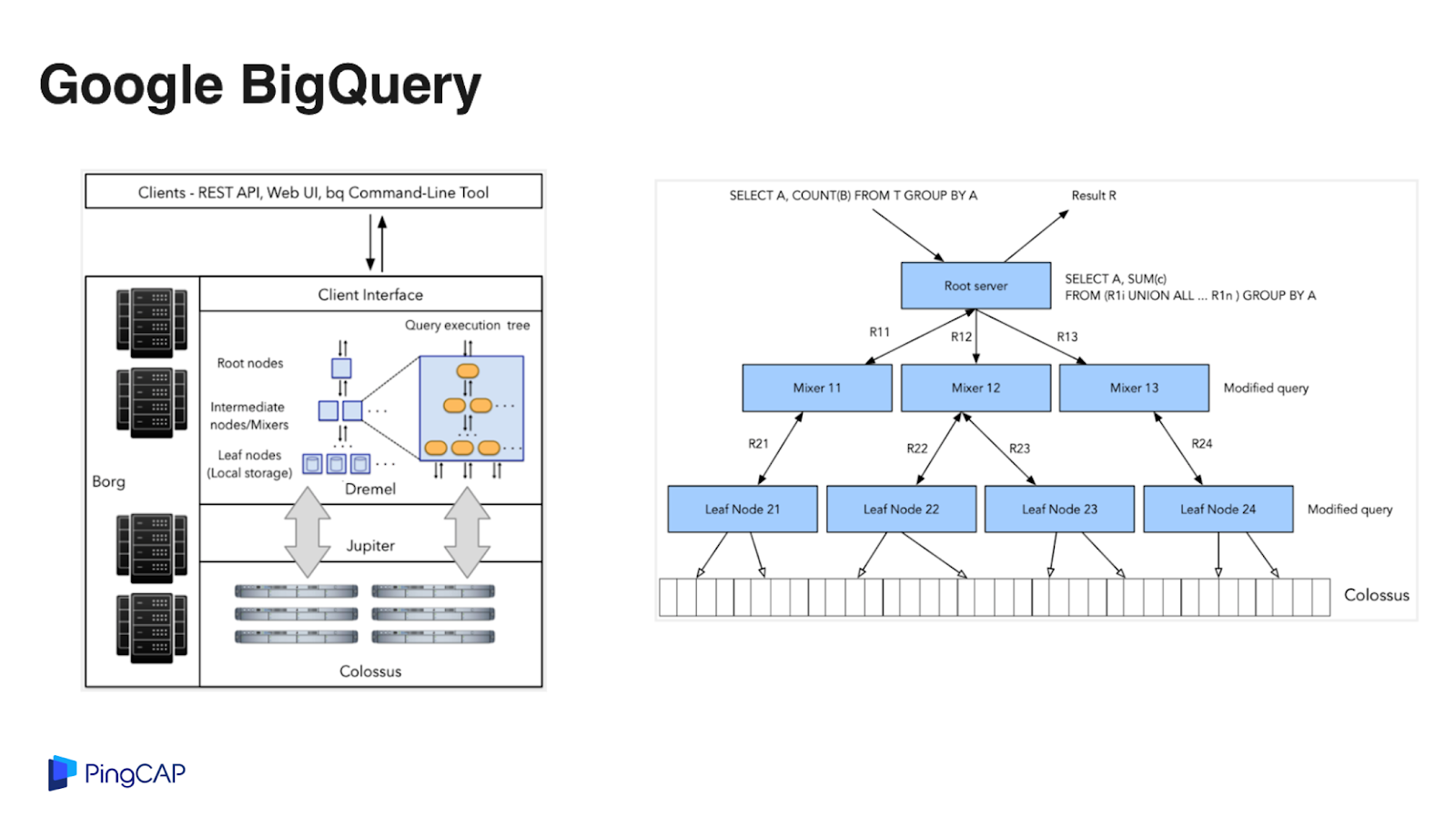
BigQuery 的處理性能比較出色,每秒在數據中心內的一個雙向的帶寬可以達到 1 PB,如果使用 2000 個專屬的計算節點單元,大概一個月的費用是四萬美金。BigQuery 是一個按需付費的模式,一個 query 可能就用兩個 slot,就收取這兩個 slot 的費用,BigQuery 的存儲成本相對較低,1 TB 的存儲大概 20 美金一個月。
第三個系統是 RockSet,大家知道 RocksDB 是一個比較有名的單機 KV 數據庫,其存儲引擎的數據結構叫 LSM-Tree,LSM-Tree 的核心思想進行分層設計,更冷的數據會在越下層。RockSet 把后面的層放在了 S3 的存儲上面,上面的層其實是用 local disk 或者本地的內存來做引擎,天然是一個分層的結構,你的應用感知不到下面是一個云盤還是本地磁盤,通過很好的本地緩存讓你感知不到下面云存儲的存在。
所以剛才看了這三個系統,我覺得有幾個特點,一個是首先都是天然分布式的,第二個是構建在云的標準服務上面的,尤其是 S3 和 EBS,第三是 pay as you go,在架構里面充分利用了云的彈性能力。我覺得這三點最重要的一點是存儲,存儲系統決定了云上數據庫的設計方向。
在存儲里邊我覺得更關鍵的可能是 S3。EBS 其實我們也有研究過,TiDB 第一階段其實已經正在跟 EBS 塊存儲做融合,但從更長遠的角度來看,我覺得更有意思的方向是在 S3 這邊。
首先第一點 S3 非常劃算,價格遠低于 EBS,第二 S3 提供了 9 個 9 很高的可靠性,第三是具備線性擴展的吞吐能力,第四是天然跨云,每一個云上都有 S3 API 的對象存儲服務。但是 S3 的問題就是隨機寫入的延遲非常高,但是吞吐性能不錯,所以我們要去利用這個吞吐性能不錯的這個特點,規避延遲高的風險。這是 S3 benchmark 的一個測試,可以看到隨著機型的提升,吞吐能力也是持續的提升。
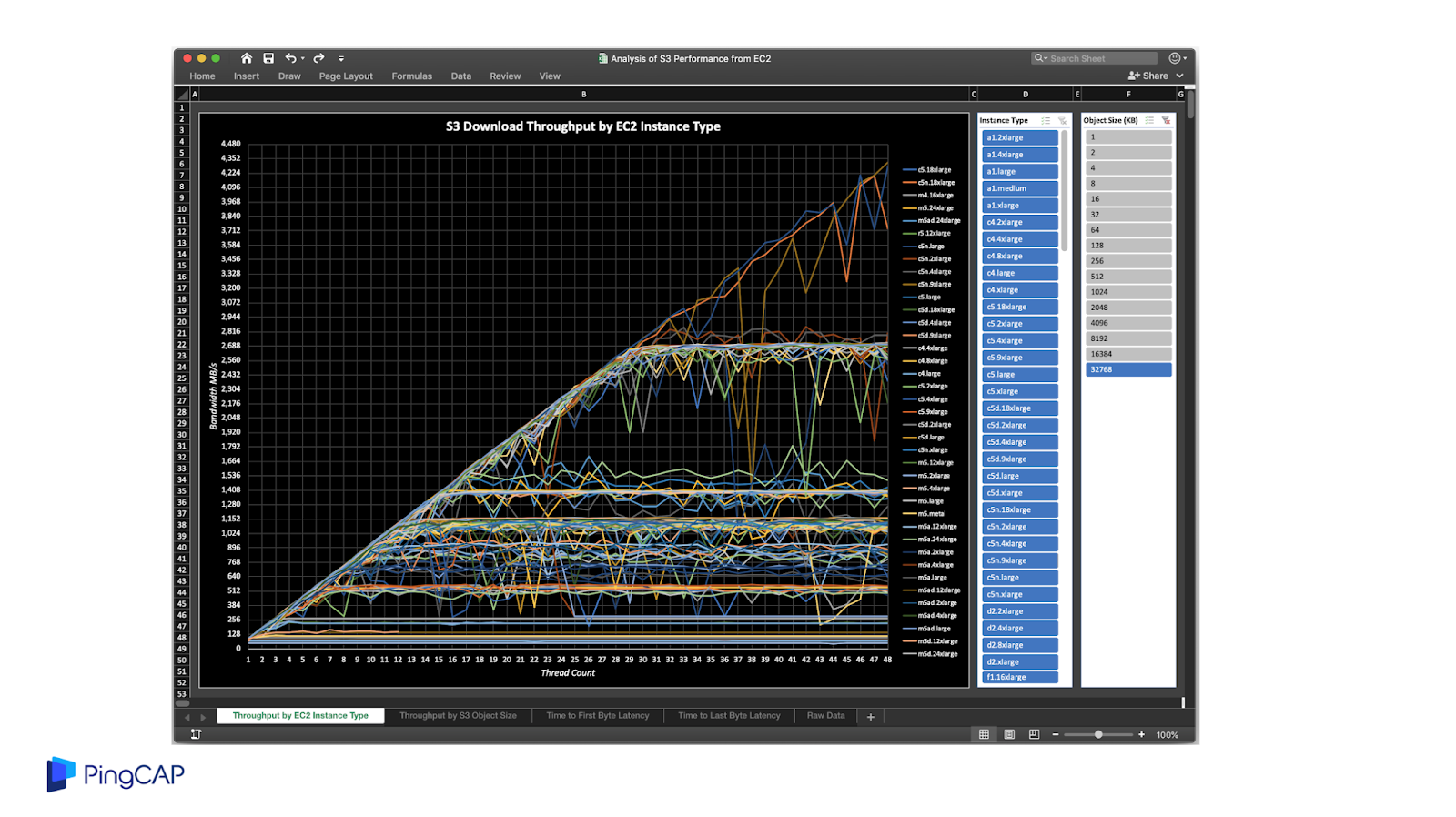
如果要解決 S3 的 Latency 問題,這里提供一些思路,比如像 RockSet 那樣用 SSD 或者本地磁盤來做 cache,或者通過 kinesis 寫入日志,來降低整個寫入的延遲。還有數據的復制或者你要去做一些并發處理等,其實可以去做 Zero-copy data cloning,也是降低延遲的一些方式。
上述例子有一些共同點都是數據倉庫,不知道大家有沒有發現,為什么都是數據倉庫?數據倉庫對于吞吐的要求其實是更高的,對于延遲并不是那么在意,一個 query 可能跑五秒出結果就行了,不用要求五毫秒之內給出結果,特別是對于一些 Point Lookup 這種場景來說,Shared Nothing 的 database 可能只需要從客戶端的一次 rpc,但是對于計算與存儲分離的架構,中間無論如何要走兩次網絡,這是一個核心的問題。
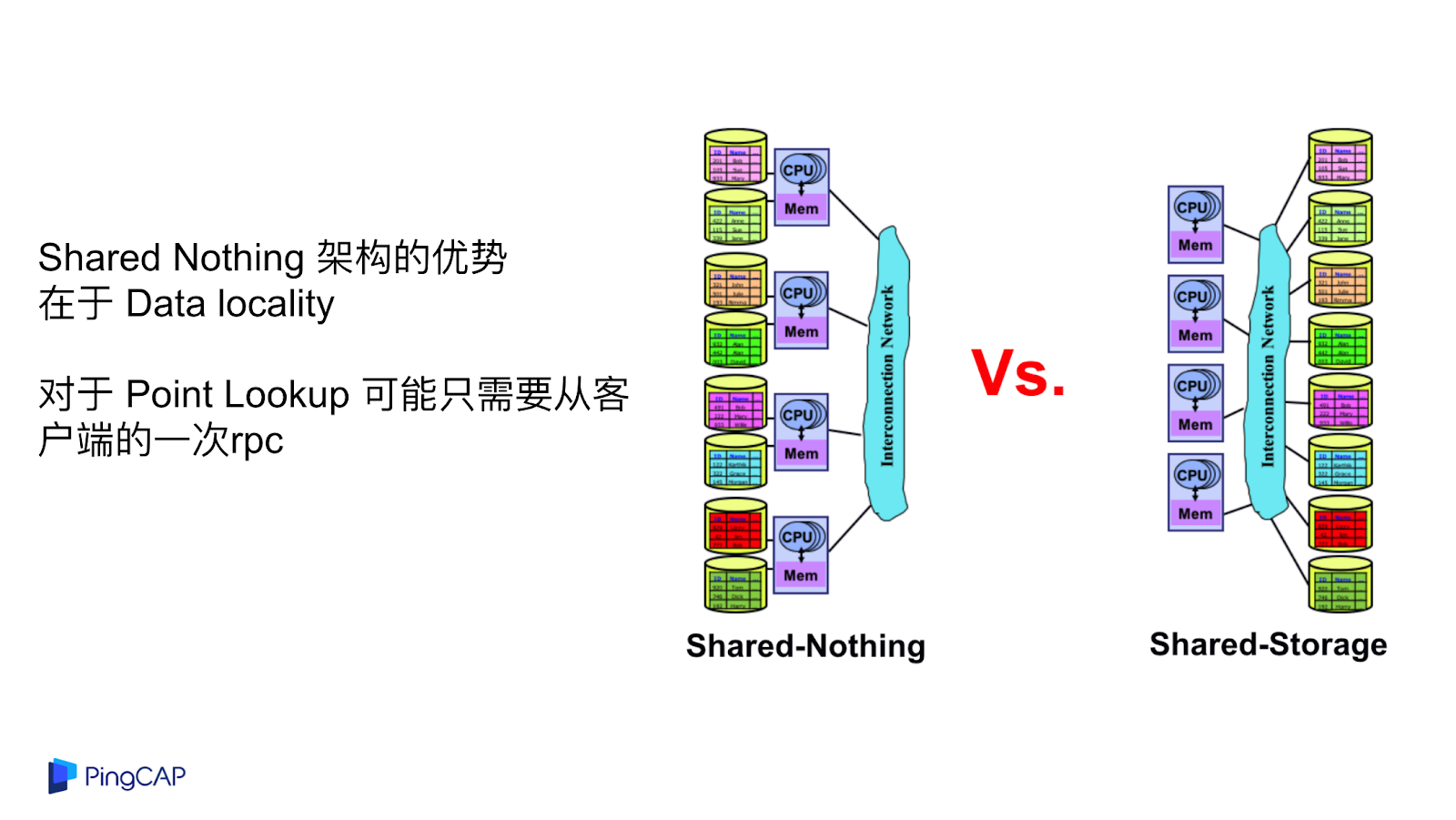
你可能會說沒有關系,反正計算和存儲已經分離了,大力出奇跡,可以加計算節點。但是我覺得新思路沒必要這么極端,Aurora 是一個計算存儲分離架構,但它是一個單機數據庫,Spanner 是一個純分布式的數據庫,純 Shared Nothing 的架構并沒有利用到云基礎設施提供的一些優勢。
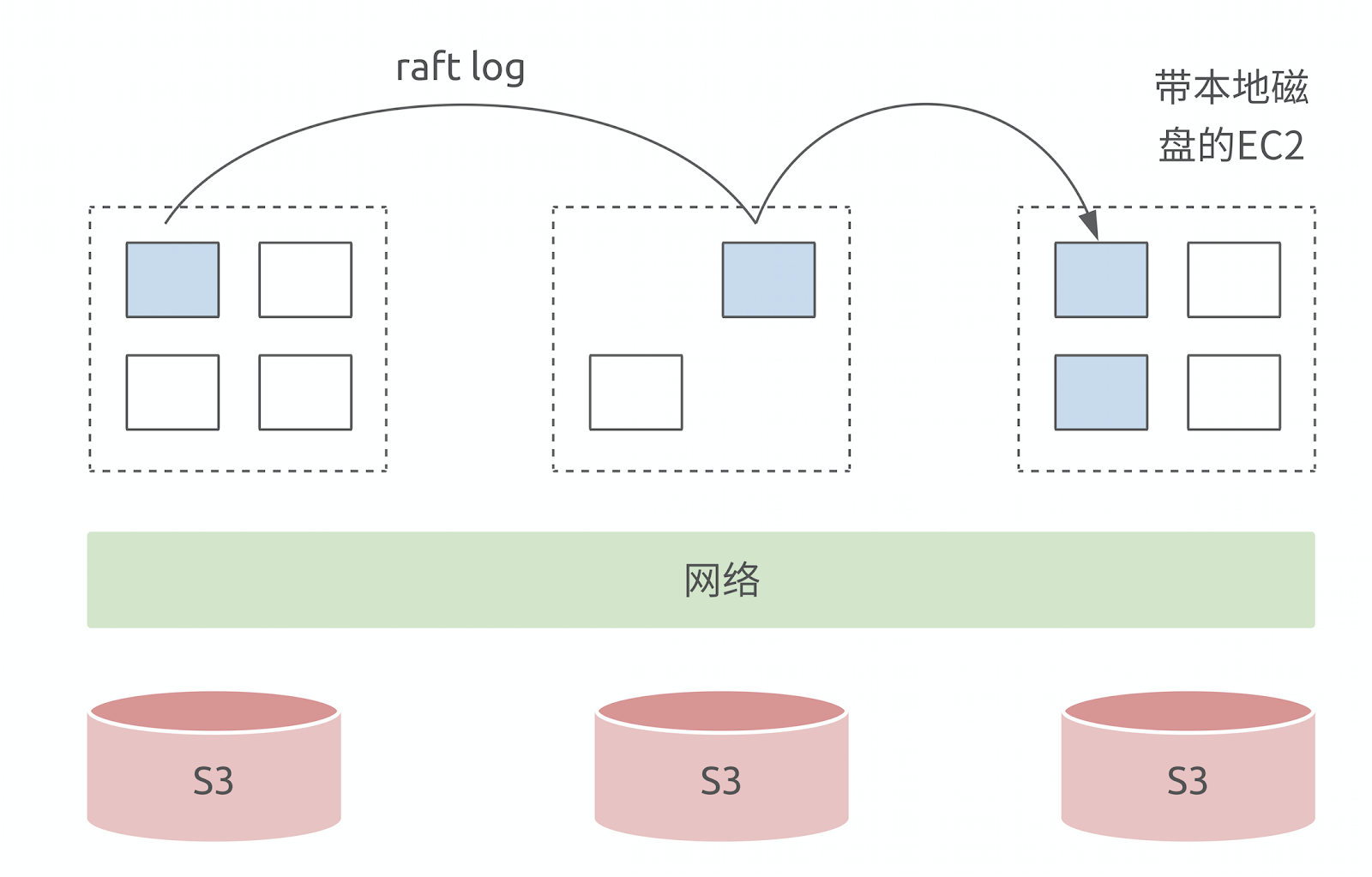
比如說未來我們的數據庫可以做這樣的設計,在計算層其實帶著一點點狀態,因為每臺 EC2 都會帶一個本地磁盤,現在主流的 EC2 都是 SSD,比較熱的數據可以在這一層做 Shared Nothing,在這一層去做高可用,在這一層去做隨機的讀取與寫入。熱數據一旦 cache miss,才會落到 S3 上面,可以在 S3 只做后面幾層的數據存儲,這種做法可能會帶來問題,一旦穿透了本地 cache,Latency 會有一些抖動。
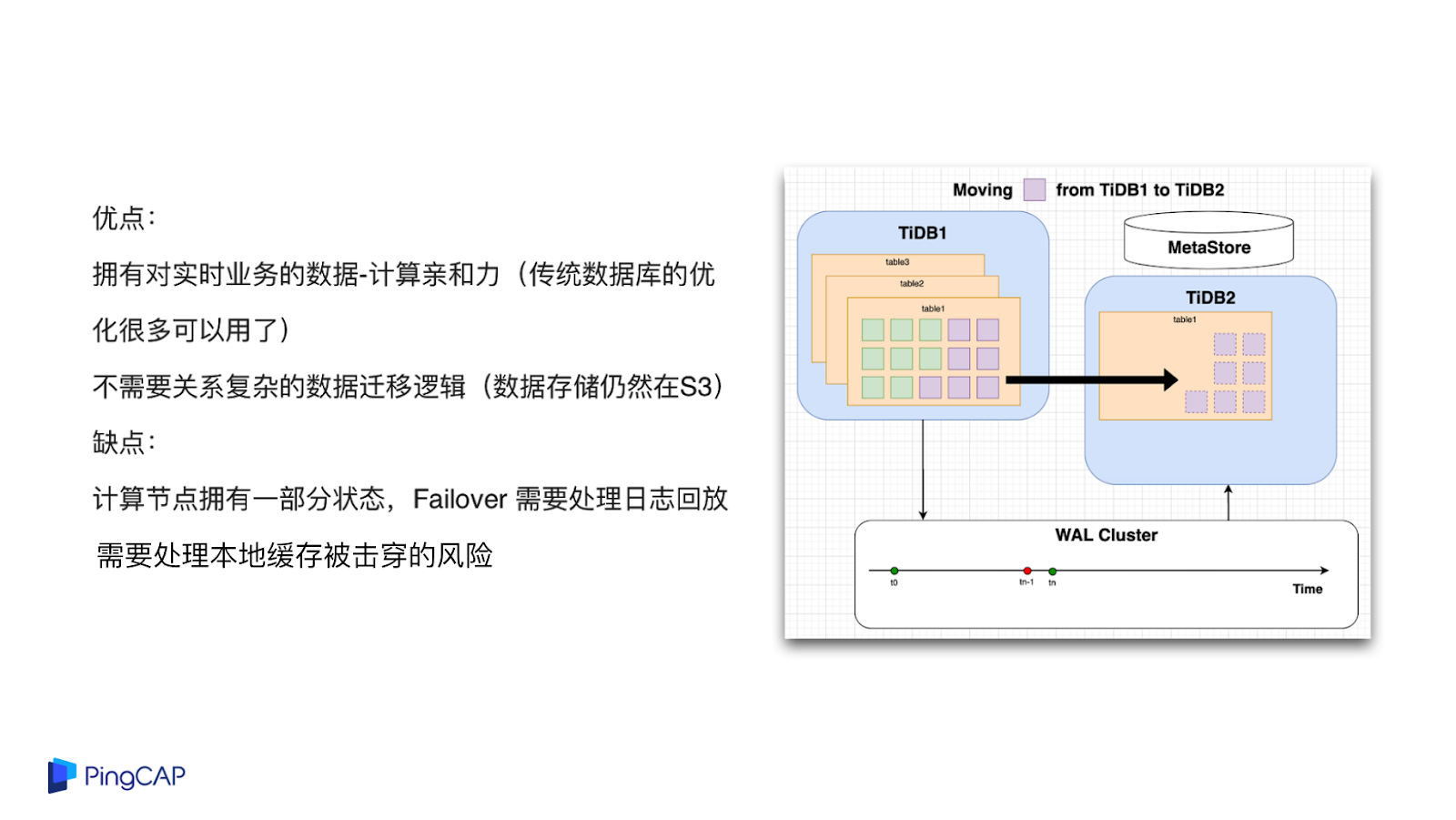
這種架構設計的好處:首先,擁有對實時業務的數據計算親和力,在 local disk 上會有很多數據,在這點上很多傳統數據庫的一些性能優化技巧可以用起來;第二,數據遷移其實會變得很簡單,實際上底下的存儲是共享的,都在 S3 上面,比如說 A 機器到 B 機器的數據遷移其實不用真的做遷移,只要在 B 機器上讀取數據就行了。
這個架構的缺點是:第一,緩存穿透了以后,Latency 會變高;第二,計算節點現在有了狀態,如果計算節點掛掉了以后,Failover 要去處理日志回放的問題,這可能會增加一點實現的復雜度。
關于“云原生數據庫設計的方法是什么”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“云原生數據庫設計的方法是什么”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





