溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家分析了如何分析Apache TubeMQ數據可靠性的相關知識點,內容詳細易懂,操作細節合理,具有一定參考價值。如果感興趣的話,不妨跟著跟隨小編一起來看看,下面跟著小編一起深入學習“如何分析Apache TubeMQ數據可靠性”的知識吧。
我們在Apache TubeMQ的適用場景有介紹,TubeMQ適用于極端情況下容忍少量數據丟失的業務場景,那么TubeMQ到底在什么情況下可能會出現數據丟失?為什么要這么設計?同類MQ在這方面是怎么做的?這篇文檔計劃解答這幾個問題。
Apache TubeMQ系統數據存儲采用的是單節點多磁盤RAID10的副本方案進行存儲,數據只在如下場景存在可能丟失情況:
機器斷電,已回復成功但還沒有被消費且處在內存中的數據會丟;機器上線后,已存儲在磁盤上的數據不受影響;
RAID10 hold不住的磁盤異常,已返回成功但還沒有被消費的數據會受影響;磁盤修復后,已存儲但沒有恢復回來的數據會丟失;
RAID10 能hold住的日常壞盤,壞盤Broker節點的生產和消費不受影響;
這個問題也是交流最多的一個話題,大家最直觀的感受是:機器很容易掛,TubeMQ只有單節點,數據的可靠性是不高的。這里個人的觀點還是如其他場合介紹里一直表達的:用數據可靠性指標來反應系統的數據可靠性其實是不太合適,因為它只是反映了系統數據可靠性的果,對如何解決數據可靠性其實沒有太直接的關系;從介紹的數據可能存在丟的場景介紹我們可以看到,生產環境的機房情況、服務器硬件情況,以及業務能否即時消費完數據等直接影響到系統的數據可靠性,是這些內容故障導致了系統數據可靠性的高或者低,如果沒有上述這些問題,TubeMQ系統的數據可靠性其實就是100%,所以,我們應該通過對應環境導致數據可能丟失的故障率指標來評估、分析系統的數據可靠性,個人覺得這個是根本。
按照2019年我們線上環境的故障數據統計,TubeMQ集群在我們環境,全年導致數據可能丟失的故障率大概是2.67%:整個TubeMQ集群1500臺機器,日均有35萬億條的數據接入量前提下,全年大概有40臺左右的服務器出現過機器ping異常,以及RAID10 hold不住的磁盤組損壞異常。個人覺得我們環境的故障率指標還可以再降低,因為TubeMQ集群里用的機器多是重點業務用了幾年后淘汰下來的二手機器設備。
降成本: 大家都知道,要達到完全100%的數據可靠性是非常耗費成本的,一個MQ管道要做成類似太空飛船設計樣構造多套獨立節點的冗余數據備份,來保證數據不丟;而從我們的分析來看,通過MQ傳遞的業務數據,90%左右的數據是可以容許極端情況下丟失少量數據的,有10%左右的數據是要求一條都不能丟,比如交易流水,涉及到錢相關的日志數據等;如果我們將這10%的高可靠數據單獨拎出來處理的話,我們就可以節約大量的成本,基于這個思路,TubeMQ負責完成要求高性能、極端情況下容許數據少量丟失的數據服務。 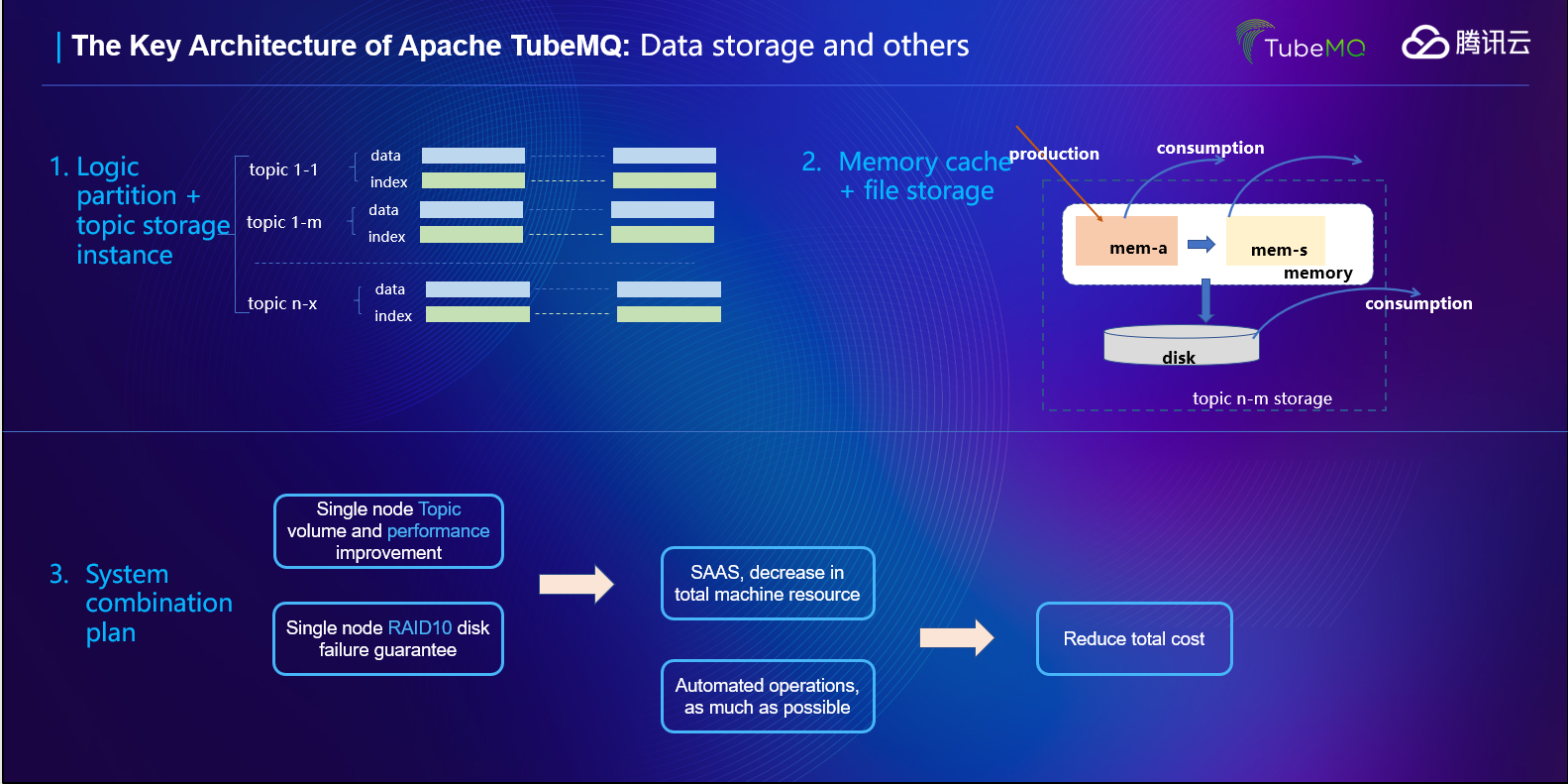
如上圖示,除了方案上的考量外,我們在TubeMQ的存儲方案設計上也是做了仔細的斟酌:我們按照Topic維度進行了數據和索引的組件;我們在文件之上再疊加了一層內存存儲作為磁盤文件存儲的延申。但我們又沒有因為業務容忍少量丟失而完全的無所顧忌,比如:我們數據生產采用的是QoS1方案;我們的數據存儲是有強制的緩存刷盤(按條、按時間、按size)控制的刷盤控制;我們的磁盤故障是有服務端基于運營策略的Broker節點自動只讀或者下線管控(ServiceStatusHolder);生產端針對Broker節點的服務質量也是有自動異常節點感知和算法屏蔽,等等等等,以此來達到高性能同時盡可能的提高數據的可靠性,降低數據丟失的可能。
能降多少成本? 拿外部多個使用Kafka的廠商已經公開的運營數據來看,1萬億日均接入量,Kafka大概需要200 ~ 300臺萬兆機,按照2019年的運營數據,TubeMQ大概40 ~ 50臺萬兆機;這里還包含一些可以區分的特殊情況,比如獨立集群、特定業務份數的不同等,但機器的成本指標數據的比值應該是相差不大的。如果把這些數據指標換算成錢的話,這個節約的成本僅服務器成本都可以以億單位 來計算。
也有人會說,是不是我拿Kafka的單副本進行業務服務,就可以達到TubeMQ一樣的成本效果了?我想表達的是,如果可以的話,我們就不會耗費這么長的時間和資源去改進TubeMQ,直接使用Kafka單副本方案了,在我們開源初期做過一份全面的單Broker的性能壓測對比總結報告tubemq_perf_test_vs_Kafka,大家可以在上面找到對應的具體差異。
這里想表達的是,實際上,TubeMQ系統本身的數據可靠性其實并不低。這里大家有沒有想過,各個MQ,在多副本方案下,系統數據可靠性又有多高呢?
Kafka: 以我個人分析的觀點,在高性能場景下Kafka的多副本方案也只是盡力而為的保證數據多副本存儲不丟。
Kafka副本機制通過一個AR集合以及ISR集合來識別和區分副本份數以及在線同步副本數,通過replica.lag.time.max.ms參數記錄各個副本最近同步的時間來判定各個Follower是否仍與Leader處于同步在線;在0.9X版本之前Kafka還有另外一個已經去掉的replica.lag.max.messages參數,Follower副本滯后Leader副本的消息數,結合起來判定失效副本。線上運行時Kafka又通過ISR的個數及請求的副本應答個數保證數據多個節點存儲:服務器端通過min.insync.replicas來確保ISR里最少處于同步狀態的副本個數,客戶端可以指定請求的Ack個數(0:不應答,1:Leader存儲即OK,-1:所有ISR節點都應答)結合起來確保數據可以被多個副本所接收。
從這個機制的設計我們可以很清晰的看到,即使是Kafka的設計者,也是很清楚數據很有可能沒有從Leader同步到各個Follower,存在復制不及時的情況,所以將ISR識別由(滯后條數,同步時間)改為了(同步時間),因為滯后量太大影響到了ISR副本數的判定。而這個ISR的副本數又影響到了對應Topic的寫入,如果Topic的ISR個數為0,原生Kafka是無法寫入消息的;為此Kafka又增加了一個unclean.leader.election.enable參數,允許未處于同步狀態的Topic副本可以選為Leader對外服務,做盡力而為的服務。
從如上分析,在大數據場景下Kafka的這種副本機制,可以滿足回溯消費業務需要,主副本所在機器故障后,已經同步到副本的數據可以被回溯業務消費到,但是,由于上述問題存在數據丟的問題,對于要求回溯并保證數據不丟的場景無法滿足;同時,這種方案資源消耗大利用率非常的低,按照2副本的配置,資源增加了至少1倍、網絡帶寬下降1/2,同時為了避免2副本形成ISR為0的情況,使用方很有可能配置3副本,從而資源增加更多而資源利用率則更低,用如此高的成本維系的卻是一個不可靠的數據服務,方案并不廉價有效;最后,Kafka在分區無副本存活時阻塞生產流量直接掉0,這對大流量環境的業務個人覺得是無法接受的,而即使采用配置3副本模式,因為3副本保活是動態的,極端情況下仍然存在生產受阻問題。
Pulsar: 以我個人的分析觀點,可以保證數據不丟,但大數據場景下是有影響的。
Pulsar采用了類似Raft協議模式,多數副本寫成功即返回成功,并且是采用的服務器主動Push請求到各個Bookeeper副本節點的模式。這種實時的多副本同步方案可以滿足絕大多數的高可靠業務需要,用戶的眼睛是雪亮的,我想近期的Pulsar火熱,也是與它滿足了市場上這方面業務需求有關系。不過,如果把它放置在大數據場景下,上千的Topic上萬的Partition時,這種多副本方案就需要耗費大量的機器資源。所以,我們TEG數據平臺部對于高可靠的數據,使用的是Pulsar對內進行服務;同時我們也將我們對Pulsar的改進捐獻給社區。
TubeMQ: 就如其適用場景介紹,TubeMQ就是為了滿足在容忍極端情況下允許數據少量丟失的業務數據上報管道需求,結合業務成本、數據可靠性的要求走了一條不一樣的自研路,針對致命異常在系統可靠性上也達到了不一樣的效果:
只要Topic分配的Broker集合里還有任意一臺Broker存活,該Topic的對外服務都可用;
基于第1點,只要集群里所有的Topic都還有任意一臺Broker存活,整個集群的Topic對外服務都是可用;
即使管控節點Master全部掛掉,集群里新增的生產、消費會受影響,但已注冊了的生產、消費不受影響,仍可繼續生產和消費;
TubeMQ基于有損服務的前提下采用盡可能保證數據不丟、服務不受阻的思路進行設計,力求方案簡單維護簡便:TubeMQ的設計里,分區故障并不影響Topic的整體對外服務,只要Topic有一個分區存活,整體的對外服務就不會受阻;TubeMQ的數據時延P99可以做到毫秒級,這樣保證了業務可以盡可能快的消費完數據,做到盡可能不丟;TubeMQ獨有的數據存儲方案設計性能要比Kafka的TPS至少高出50%以上(有些機型上還是翻倍的效果),同時借助存儲方案的不同,單機容納的Topic數和分區數更多,進而可以使得集群規模更大,減少維護成本。這些不一樣的考慮和實現結合起來從而使得TubeMQ做到低成本,高性能,高穩定性基礎。
關于“如何分析Apache TubeMQ數據可靠性”就介紹到這了,更多相關內容可以搜索億速云以前的文章,希望能夠幫助大家答疑解惑,請多多支持億速云網站!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





