溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Apache IoTDB數據模型怎么創建”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
什么是時序數據?
物聯網誕生于1999年,在其理念和技術的不斷革新下,無處不在的設備和設施正在被越來越多的通過網絡連接起來,并不斷向云端發送實況數據。
以國家級氣象觀測站為例,全國有近6萬個氣象觀測站,每個氣象觀測站有70種氣象物理量需要采集。某市地鐵每列列車擁有3200個指標需要測量,全市列車數達300列。服務器運維監控中,一臺服務器需要同時監測IOPS、CPU、網絡等十余項指標。這些例子中展現出兩個概念:設備與度量指標。所謂度量指標(又被稱為工況、測點)是指用戶關心的能反映目標的某種狀況的數據項,例如CPU利用率、溫度、濕度等等。設備是指一個擁有一系列度量指標的實體,例如一臺服務器、一個進程、一列車、一個氣象觀測站等等。一個設備的一個度量指標形成了一條時序數據的唯一標識。
隨著時間推移,這條時序數據會產生一系列(時間戳,值)的二元組數據點,構成了時間序列數據集。因此,我們定義一條時間序列是由一個時間序列標識(設備和度量指標),一系列時間戳和數據值對組成的無限集。一個時間序列數據庫將管理百萬甚至千萬條這樣的時間序列。
IoTDB 數據模型及手動創建方式
IoTDB 的元數據管理采用目錄樹的結構,不同層級之間用 . 分割。根節點默認為 root ,除此之外主要有三個概念。存儲組、設備、測點。

手動創建存儲組:
set storage group to root.FU01
手動創建時間序列:
create timeseries root.FU01.deviceType1.AZQ01.Temperature with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY
設備不需要創建,當創建時間序列時會默認將倒數第二層當做設備。以上述時間序列為例,設備 ID 會被設置為root.FU01.deviceType1.AZQ01 。一個設備一個時間戳的多個測點值,最好一次同時寫入,盡量避免亂序數據產生。
當創建足夠多的時間序列后,元數據看起來就是下面這樣一顆樹了:
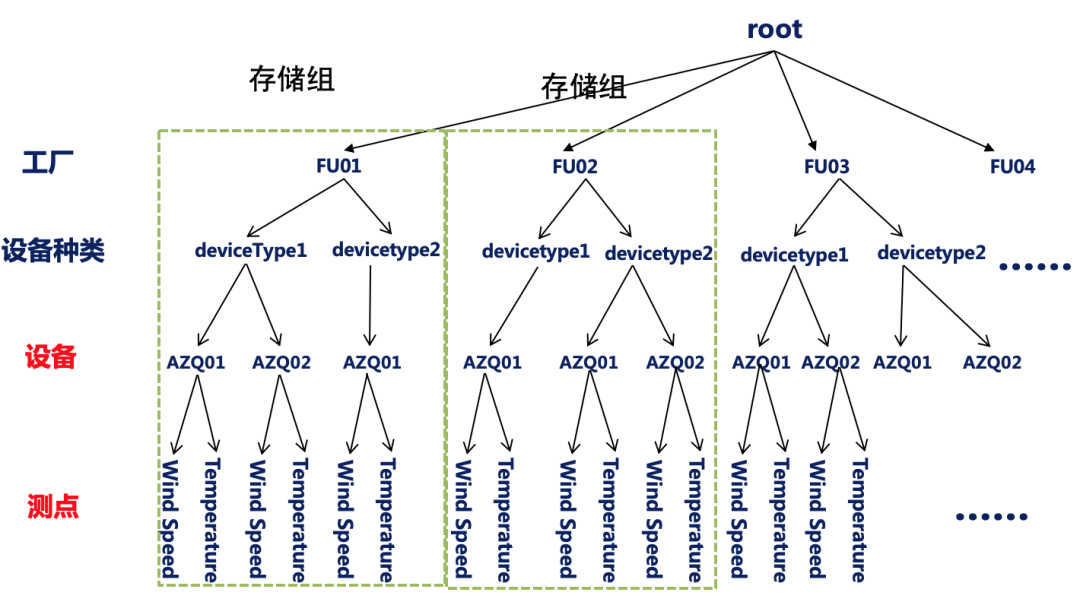
數據類型目前支持 6 種
BOOLEAN、INT32、INT64、FLOAT、DOUBLE、TEXT
編碼方式主要有 4 種
TS_2DIFF (時間列的默認編碼方式):適用 INT32、INT64RLE:適用 INT32、INT64、FLOAT、DOUBLE(對于 FLOAT 和 DOUBLE 是有損壓縮,默認保留2位小數,可在配置文件中修改 float_precision)GORILLA:適用 FLOAT、DOUBLEPLAIN:全搭
壓縮方式:
UNCOMPRESSED、SNAPPY(默認)
推薦建模方式
存儲組:推薦10-50個左右,每個存儲組是一個獨立的存儲引擎,增加存儲組可增加寫入并行度。
設備:推薦10萬以下
總序列個數:推薦1000萬以下
正常負載下此建模方式沒問題,如果系統提示系統負載過高,可將 enable_parameter_adapter 設置為 false,需要手動配置參數,防止爆內存,簡單的規則為:
memtable_size_threshold=tsfile_size_threshold
= IoTDB分配內存/2/存儲組個數/4 (有亂序數據)
= IoTDB分配內存/2/存儲組個數/2 (無亂序數據)
IoTDB 分配內存在 conf/iotdb-env.sh 中設置 MAX_HEAP_SIZE。
配置文件在 conf/iotdb-engine.properties。
推薦負載按這個調大多沒問題,負載再高可以聯系我們,這個手動調整參數在 0.11 版本就會去掉,解放生產力!
一個方法判斷有無亂序:只要每個設備寫入時間戳都是遞增的,就沒亂序數據,否則都可能產生亂序數據。
舉個例子:設備 root.turbine.d1 有三個測點 s1, s2, s3
# 無亂序數據insert into root.turbine.d1(timestamp,s1,s2,s3) values(1,1,2,3);insert into root.turbine.d1(timestamp,s1,s2,s3) values(2,1,2,3);# 時間戳先寫 2,再寫 1,可能有亂序數據insert into root.turbine.d1(timestamp,s1,s2,s3) values(2,1,2,3);insert into root.turbine.d1(timestamp,s1,s2,s3) values(1,1,2,3);# 時間戳先寫 1,再寫 1,雖然是不同測點,但還屬于一個設備,可能有亂序數據insert into root.turbine.d1(timestamp,s1,s2) values(1,1,2);insert into root.turbine.d1(timestamp,s3) values(1,3);
自動創建元數據模式
除了手動創建元數據的方式,還支持自動創建元數據,自動創建元數據是在數據寫入的過程進行的。主要針對提前不知道序列總數,實時消費消息隊列進行寫入的場景,代碼中就不需要每條數據都創建序列了。
當我們對一條時間序列寫入數據時,會首先檢查其存儲組是否存在,如果不存在會自動創建。我們把 root 定義為第 0 層,存儲組默認是第一層,也就是 root 下的一層,可在配置文件中修改默認創建的層級 default_storage_group_level。
自動創建的數據類型是根據寫入值的類型自動推斷出來的。假如傳入的是字符串格式的數據,即用 JDBC 的 insert 語句寫入,或者 Session 中值類型為 String 的 insertRecord(s) 接口寫入,會根據值的格式來判斷,主要有四種格式的字符串,以及默認類型:
不帶 . 的整數:如 123 => FLOAT帶 . 的浮點數:如 12.34 => FLOAT布爾型:true,false => BOOLEAN其他類型:abc,124sa => TEXT
對于前 3 種格式的字符串的默認類型,都可以在配置文件中配置,(0.10.0 版本,目前的 master 分支, boolean_string_infer_type 參數附近)
簡單試用
腳本默認前臺,需要手動后臺啟動,
nohup ./sbin/start-server.sh >/dev/null 2>&1 &
接下來可以啟動 Cli 命令行:
./sbin/start-client.sh -h 127.0.0.1 -p 6667 -u root -pw rootor./sbin/start-client.sh (默認用root連接本機)
在 0.10.0 版本中,即將改名為 start-cli.sh。
“Apache IoTDB數據模型怎么創建”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





