溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python多線程爬蟲的使用方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Python 3.6
Pycharm
wkhtmltopdf
re
requests
concurrent.futures
安裝Python并添加到環境變量,pip安裝需要的相關模塊即可。
現在聊天誰還不發幾個表情包?聊天時,表情包是我們重要的工具,更是拉進小伙伴們距離的好幫手,當聊天陷入尷尬境地時,隨手一張表情包,讓尷尬化為無形
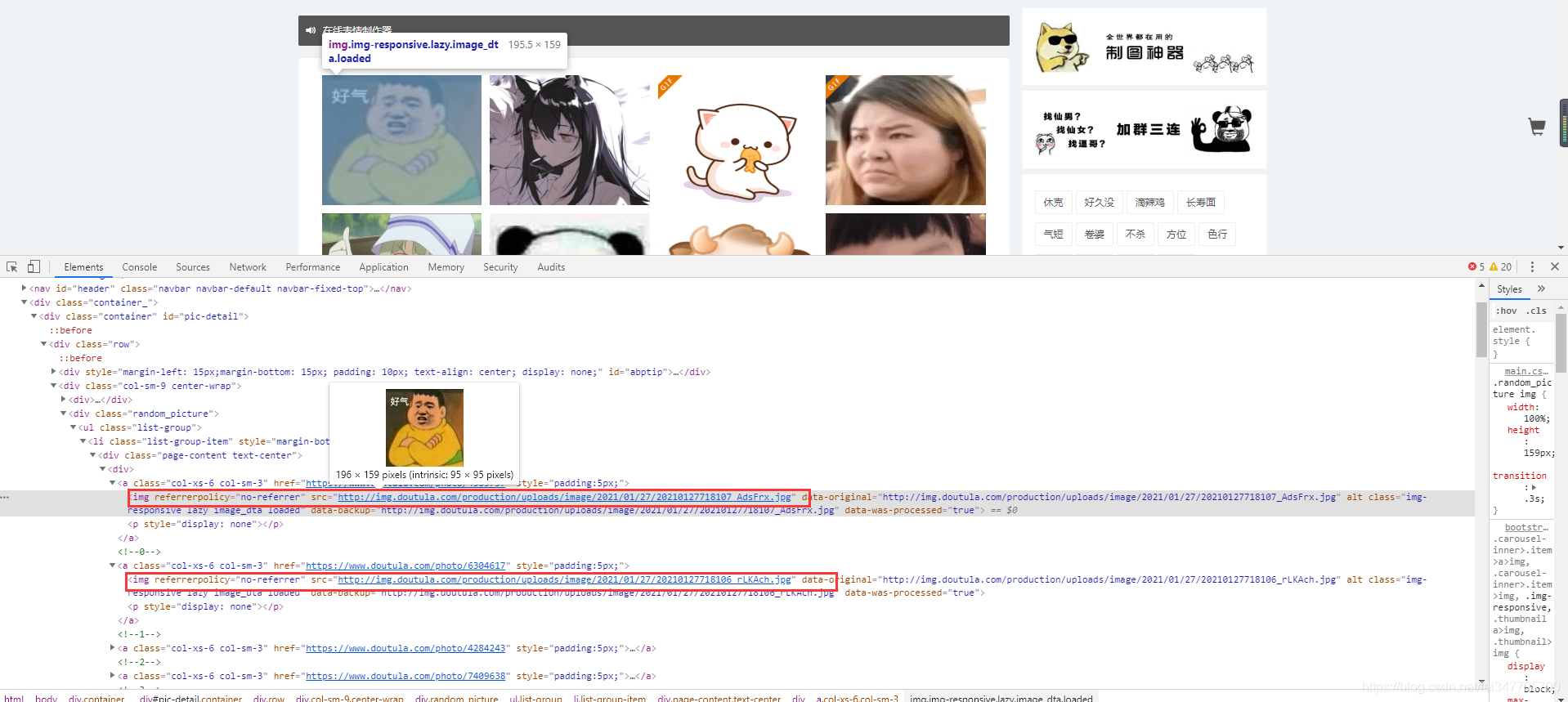
如圖所示斗圖網上面的圖片數據都包含在 a 標簽當中,可以嘗試直接請求這個網頁,查看response 返回的數據當中是否也含有 圖片地址。
import requests
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def main(html_url):
response = get_response(html_url)
print(response.text)
if __name__ == '__main__':
url = 'https://www.doutula.com/photo/list/'
main(url)在輸出結果中 ctrl + F 進行搜索。
這里有一個點想要注意一下,我用python請求網頁所給我們返回的結果當中,包含圖片url地址是:
data-original="圖片url"
data-backup="圖片url"
如果想要提取url地址的話,可以用parsel 解析庫,或者 re 正則表達式。之前都是使用的parsel,本篇文章就用 正則表達式吧。
urls = re.findall('data-original="(.*?)"', response.text)import requests
import re
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def save(image_url, image_name):
image_content = get_response(image_url).content
filename = 'images\\' + image_name
with open(filename, mode='wb') as f:
f.write(image_content)
print(image_name)
def main(html_url):
response = get_response(html_url)
urls = re.findall('data-original="(.*?)"', response.text)
for link in urls:
image_name = link.split('/')[-1]
save(link, image_name)
if __name__ == '__main__':
url = 'https://www.doutula.com/photo/list/'
main(url)
3631頁的數據,什么表情都有,嘿嘿嘿
import requests
import re
import concurrent.futures
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def save(image_url, image_name):
image_content = get_response(image_url).content
filename = 'images\\' + image_name
with open(filename, mode='wb') as f:
f.write(image_content)
print(image_name)
def main(html_url):
response = get_response(html_url)
urls = re.findall('data-original="(.*?)"', response.text)
for link in urls:
image_name = link.split('/')[-1]
save(link, image_name)
if __name__ == '__main__':
# ThreadPoolExecutor 線程池的對象
# max_workers 最大任務數
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
for page in range(1, 3632):
url = f'https://www.doutula.com/photo/list/?page={page}'
# submit 往線程池里面添加任務
executor.submit(main, url)
executor.shutdown()“Python多線程爬蟲的使用方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





