溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何分析Python多線程在爬蟲中的應用,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
作為測試工程師經常需要解決測試數據來源的問題,解決思路無非是三種:
1、直接從生產環境拷貝真實數據
2、從互聯網上爬取數據
3、自己用腳本或者工具造數據。
前段時間,為了獲取更多的測試數據,筆者就做了一個從互聯網上爬取數據的爬蟲程序,雖然功能上基本滿足項目的需求,但是爬取的效率還是不太高。
作為一個精益求精的測試工程師,決定研究一下多線程在爬蟲領域的應用,以提高爬蟲的效率。
一、為什么需要多線程
凡事知其然也要知其所以然。在了解多線程的相關知識之前,我們先來看看為什么需要多線程。打個比方吧,你要搬家了,單線程就類似于請了一個搬家工人,他一個人負責打包、搬運、開車、卸貨等一系列操作流程,這個工作效率可想而知是很慢的;而多線程就相當于請了四個搬家工人,甲打包完交給已搬運到車上,然后丙開車送往目的地,最后由丁來卸貨。
由此可見多線程的好處就是高效、可以充分利用資源,壞處就是各個線程之間要相互協調,否則容易亂套(類似于一個和尚挑水喝、兩個和尚抬水喝、三個和尚沒水喝的窘境)。所以為了提高爬蟲效率,我們在使用多線程時要格外注意多線程的管理問題。
二、多線程的基本知識
進程:由程序,數據集,進程控制塊三部分組成,它是程序在數據集上的一次運行過程。如果同一段程序在某個數據集上運行了兩次,那就是開啟了兩個進程。進程是資源管理的基本單位。在操作系統中,每個進程有一個地址空間,而且默認就有一個控制進程。
線程:是進程的一個實體,是 CPU 調度和分派的基本單位,也是最小的執行單位。它的出現降低了上下文切換的消耗,提高了系統的并發性,并克服了一個進程只能干一件事的缺陷。線程由進程來管理,多個線程共享父進程的資源空間。
進程和線程的關系:
一個線程只能屬于一個進程,而一個進程可以有多個線程,但至少有一個線程。
資源分配給進程,同一進程的所有線程共享該進程的所有資源。
CPU 分給線程,即真正在 CPU 上運行的是線程。
線程的工作方式:
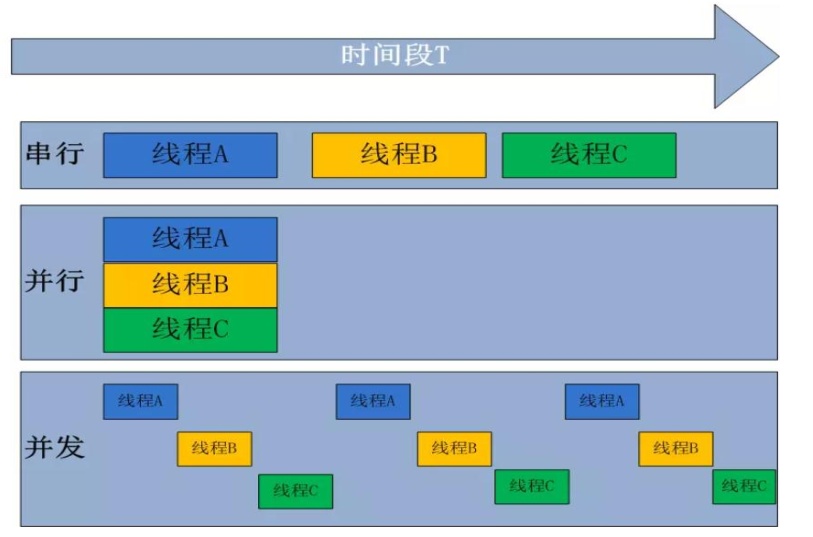
如下圖所示,串行指線程一個個地在 CPU 上執行;并行是在多個 CPU 上運行多個
線程;而并發是一種“偽并行”,一個 CPU 同一時刻只能執行一個任務,把 CPU 的時間
分片,一個線程只占用一個很短的時間片,然后各個線程輪流,由于時間片很短所以在
用戶看來所有線程都是“同時”的。并發也是大多數單 CPU 多線程的實際運行方式。
 點擊添加圖片描述(最多60個字)
點擊添加圖片描述(最多60個字)
進程的工作狀態:
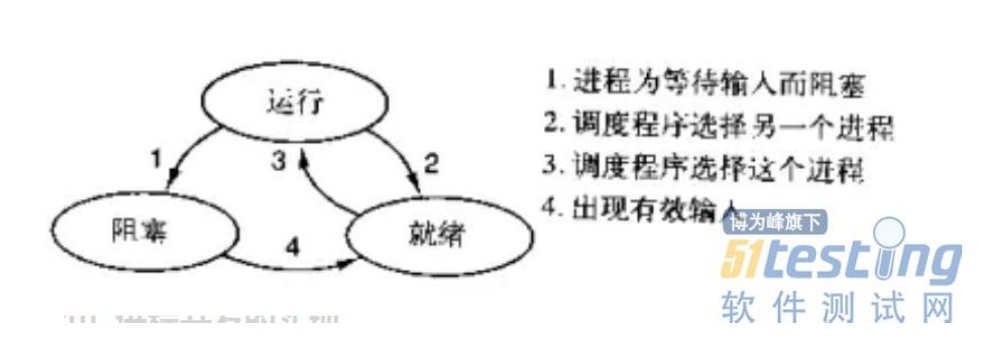
一個進程有三種狀態:運行、阻塞、就緒。三種狀態之間的轉換關系如下圖所示:運行態的進程可能由于等待輸入而主動進入阻塞狀態,也可能由于調度程序選擇其他進程而被動進入就緒狀態(一般是分給它的 CPU 時間到了);阻塞狀態的進程由于等到了有效的輸入而進入就緒狀態;就緒狀態的進程因為調度程序再次選擇了它而再次進入運行狀態。
 點擊添加圖片描述(最多60個字)
點擊添加圖片描述(最多60個字)
三、多線程通信實例
還是回到爬蟲的問題上來,我們知道爬取博客文章的時候都是先爬取列表頁,然后根據列表頁的爬取結果再來爬取文章詳情內容。而且列表頁的爬取速度肯定要比詳情頁的爬取速度快。
這樣的話,我們可以設計線程 A 負責爬取文章列表頁,線程 B、線程 C、線程 D 負責爬取文章詳情。A 將列表 URL 結果放到一個類似全局變量的結構里,線程 B、C、D從這個結構里取結果。
在 PYTHON 中,有兩個支持多線程的模塊:threading 模塊--負責線程的創建、開啟等操作;queque 模塊--負責維護那個類似于全局變量的結構。
這里還要補充一點:也許有同學會問直接用一個全局變量不就可以了么?干嘛非要用 queue?
因為全局變量并不是線程安全的,比如說全局變量里(列表類型)只有一個 url 了,線程 B 判斷了一下全局變量非空,在還沒有取出該 url 之前,cpu 把時間片給了線程 C,線程 C 將最后一個url 取走了,這時 cpu 時間片又輪到了 B,B 就會因為在一個空的列表里取數據而報錯。
而 queue 模塊實現了多生產者、多消費者隊列,在放值取值時是線程安全的。
廢話不多說了,直接上代碼給大伙看看:
import threading # 導入 threading 模塊
from queue import Queue #導入 queue 模塊
import time #導入 time 模塊
# 爬取文章詳情頁
def get_detail_html(detail_url_list, id):
while True:
url = detail_url_list.get() #Queue 隊列的 get 方法用于從隊列中提取元素
time.sleep(2) # 延時 2s,模擬網絡請求和爬取文章詳情的過程
print("thread {id}: get {url} detail finished".format(id=id,url=url)) #打印線程 id 和被爬取了文章內容的 url
# 爬取文章列表頁
def get_detail_url(queue):
for i in range(10000):
time.sleep(1) # 延時 1s,模擬比爬取文章詳情要快
queue.put("http://testedu.com/{id}".format(id=i))#Queue 隊列的 put 方法用于向 Queue 隊列中放置元素,由于 Queue 是先進先出隊列,所以先被 Put 的 URL 也就會被先 get 出來。
print("get detail url {id} end".format(id=i))#打印出得到了哪些文章的 url
#主函數
if __name__ == "__main__":
detail_url_queue = Queue(maxsize=1000) #用 Queue 構造一個大小為 1000 的線程安全的先進先出隊列
# 先創造四個線程
thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,)) #A 線程負責抓取列表
url
html_thread= []
for i in range(3):
thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i))
html_thread.append(thread2)#B C D 線程抓取文章詳情
start_time = time.time()
# 啟動四個線程
thread.start()
for i in range(3):
html_thread[i].start()
# 等待所有線程結束,thread.join()函數代表子線程完成之前,其父進程一直處于阻塞狀態。
thread.join()
for i in range(3):
html_thread[i].join()
print("last time: {} s".format(time.time()-start_time))#等 ABCD 四個線程都結束后,在主進程中計算總爬取時間。
運行結果:
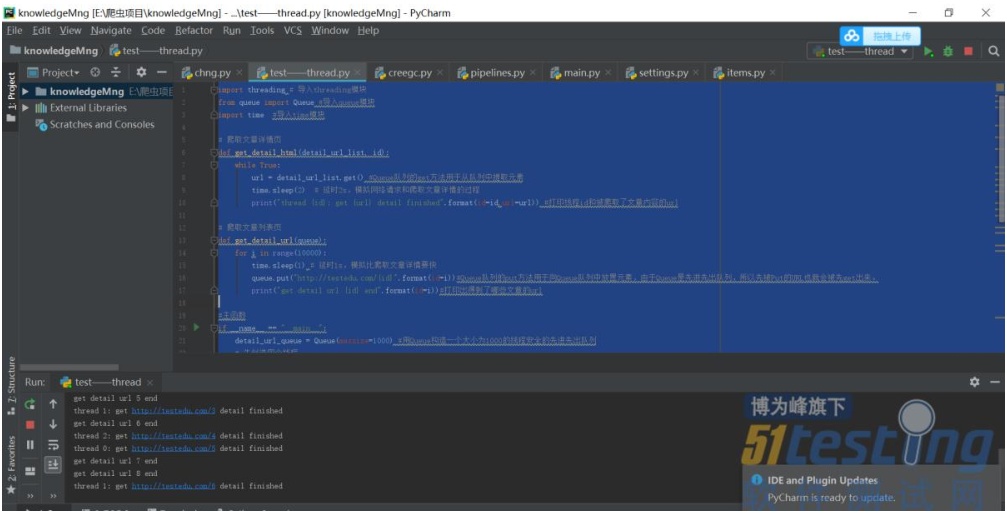
從運行結果可以看出各個線程之間井然有序地工作著,沒有出現任何報錯和告警的情況。可見使用 Queue 隊列實現多線程間的通信比直接使用全局變量要安全很多。而且使用多線程比不使用多線程的話,爬取時間上也要少很多,在提高了爬蟲效率的同時也兼顧了線程的安全,可以說在爬取測試數據的過程中是非常實用的一種方式。
上述內容就是如何分析Python多線程在爬蟲中的應用,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





