溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“simhash的文本去重原理是什么”,在日常操作中,相信很多人在simhash的文本去重原理是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”simhash的文本去重原理是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
互聯網網頁存在大量的內容重復的網頁,文本,無論對于搜索引擎,爬蟲的網頁去重和過濾、新聞小說等內容網站的內容反盜版和追蹤,還是社交媒體等文本去重和聚類,都需要對網頁或者文本進行去重和過濾。為此必須有一套高效的去重算法,要不然爬蟲將做非常多的無用功,時效性等都無法得到保證,更重要的是用戶體驗也不好。業界關于文本指紋去重的算法眾多,如 k-shingle 算法、google 提出的simhash 算法、Minhash 算法、百度top k 最長句子簽名算法等等,下面介紹下simhash算法以及python應用。
simhash 是 google 用來處理海量文本去重的算法。 simhash 可以將一個文檔轉換成一個 64 位的字節,暫且稱之為特征字。判斷文檔是否重復,只需要判斷文檔特征字之間的漢明距離。根據經驗,一般當兩個文檔特征字之間的漢明距離小于 3, 就可以判定兩個文檔相似。
傳統的Hash算法只負責將原始內容盡量均勻隨機地映射為一個簽名值,原理上僅相當于偽隨機數產生算法。傳統的hash算法產生的兩個簽名,如果原始內容在一定概率下是相等的;如果不相等,除了說明原始內容不相等外,不再提供任何信息,因為即使原始內容只相差一個字節,所產生的簽名也很可能差別很大。所以傳統的Hash是無法在簽名的維度上來衡量原內容的相似度,而simHash本身屬于一種局部敏感哈希算法,它產生的hash簽名在一定程度上可以表征原內容的相似度。
我們主要解決的是文本相似度計算,要比較的是兩個文章是否相識,當然我們降維生成了hash簽名也是用于這個目的。看到這里估計大家就明白了,我們使用的simhash就算把文章中的字符串變成 01 串也還是可以用于計算相似度的,而傳統的hash卻不行。我們可以來做個測試,兩個相差只有一個字符的文本串,“你媽媽喊你回家吃飯哦” 和 “你媽媽叫你回家吃飯啦”。
通過simhash計算結果為:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通過傳統hash計算為:
0001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出來,相似的文本只有部分 01 串變化了,而普通的hash卻不能做到,這個就是局部敏感哈希的魅力。
在新拿到文本之后需要先進行分詞,這是因為需要挑出TopN個詞來表征這篇文本,并且分詞的權重不一樣,可以使用相應數據集的tf-idf值作為分詞的權重,這樣就分成了帶權重的分詞結果。
之后對所有分詞進行哈希運算獲取二值化的hash結果,再將權重與哈希值相乘,獲得帶權重的哈希值,最后進行累加以及二值化處理。 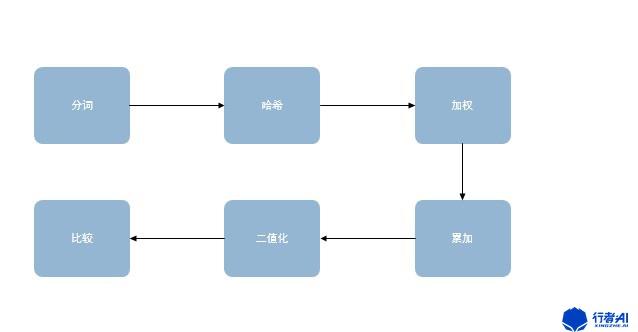
使用分詞手段將文本分割成關鍵詞的特征向量,分詞方法有很多一般都是實詞,也就是把停用詞等都去掉之后的部分,使用者可以根據自己的需求選擇.最后形成去掉噪音詞的單詞序列并為每個詞加上權重. 例如:
行者AI 專注 于 游戲 領域 多年 AI技術 積淀 一站式 提供 文本 圖片 音視頻 內容 審核 游戲AI 以及 數據 平臺 服務
目前的詞只是進行了分割,但是詞與詞含有的信息量是不一樣的,比如行者AI 游戲 審核 這三個詞就比 專注 服務 以及更能表達文本的主旨含義,這也就是所謂信息熵的概念。
為此我們還需要設定特征詞的權重,簡單一點的可以使用絕對詞頻來表示,也就是某個關鍵詞出現的次數,但是事實上出現次數少的所含有的信息量可能更多.總之需要選擇一種加權方法,否則效果會打折扣。
前面我們使用分詞方法和權重分配將文本就分割成若干個帶權重的實詞,比如權重使用1-5的數字表示,1最低5最高。
行者AI(5) 專注(2) 于(1) 游戲(3) 領域(1) 多年(1) AI技術(4) 積淀(1) 一站式(2) 提供(1) 文本(2) 圖片(2) 音視頻(2) 內容(1) 審核(2) 游戲AI(4) 以及(1) 數據(3) 平臺(1) 服務(2)
對各個特征詞進行二值化哈希值計算, 再將所有的哈希值累加,最后將累加結果二值化。 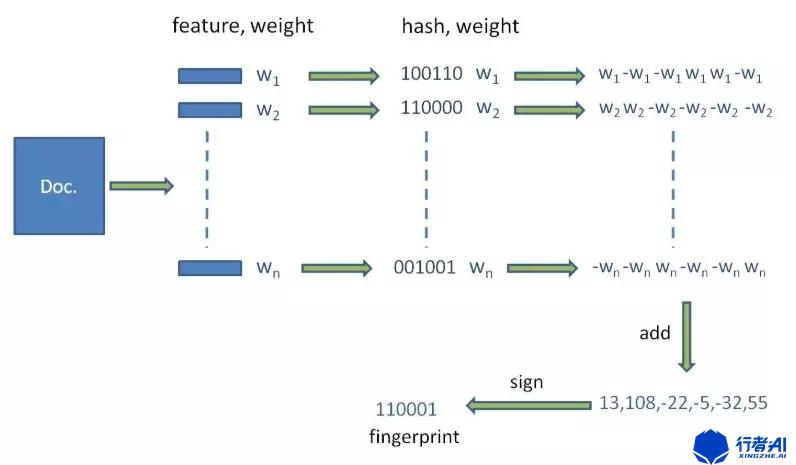
在信息論中,兩個等長字符串之間的漢明距離(英語:Hamming distance)是兩個字符串對應位置的不同字符的個數。換句話說,它就是將一個字符串變換成另外一個字符串所需要替換的字符個數。
漢明重量是字符串相對于同樣長度的零字符串的漢明距離,也就是說,它是字符串中非零的元素個數:對于二進制字符串來說,就是1的個數,所以11101的漢明重量是4。
對于二進制字符串a與b來說,它等于a 異或b后所得二進制字符串中“1”的個數。
漢明距離是以理查德·衛斯里·漢明的名字命名的,漢明在誤差檢測與校正碼的基礎性論文中首次引入這個概念。
在通信中累計定長二進制字中發生翻轉的錯誤數據位,所以它也被稱為信號距離。漢明重量分析在包括信息論、編碼理論、密碼學等領域都有應用。但是,如果要比較兩個不同長度的字符串,不僅要進行替換,而且要進行插入與刪除的運算,在這種場合下,通常使用更加復雜的編輯距離等算法。
谷歌經過工程驗證認為當兩個64bit的二值化simhash值的漢明距離超過3則認為不相似,所以判重問題就轉換為求兩個哈希值的漢明距離問題。
pip 源中有數種 simhash 的實現,simhash,使用起來十分方便,直接使用 pip 就可以安裝
pip install simhash
使用例子
from simhash import Simhash def simhash_demo(text1, text2): """ 求兩文本的相似度 :param text1: :param text2: :return: """ a_simhash = Simhash(text1) b_simhash = Simhash(text2) max_hashbit = max(len(bin(a_simhash.value)), (len(bin(b_simhash.value)))) # 漢明距離 distince = a_simhash.distance(b_simhash) print(distince) similar = 1 - distince / max_hashbit return similar if __name__ == '__main__': text1 = "行者AI專注于游戲領域,多年的AI技術積淀,一站式提供文本、圖片、音/視頻內容審核,游戲AI以及數據平臺服務" text2 = "行者AI專注于游戲領域,多年的AI技術積淀,二站式提供文本、圖片、音 視頻內容審核,游戲AI以及數據平臺服務" similar = simhash_demo(text1, text2) print(similar)
到此,關于“simhash的文本去重原理是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





