溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何使用PyTorch進行矩陣分解進行動漫的推薦,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
我們一天會遇到很多次推薦——當我們決定在Netflix/Youtube上看什么,購物網站上的商品推薦,Spotify上的歌曲推薦,Instagram上的朋友推薦,LinkedIn上的工作推薦……列表還在繼續!推薦系統的目的是預測用戶對某一商品的“評價”或“偏好”。這些評級用于確定用戶可能喜歡什么,并提出明智的建議。
推薦系統主要有兩種類型:
基于內容的系統:這些系統試圖根據項目的內容(類型、顏色等)和用戶的個人資料(喜歡、不喜歡、人口統計信息等)來匹配用戶。例如,Youtube可能會根據我是一個廚師的事實,以及/或者我過去看過很多烘焙視頻來推薦我烹飪視頻,從而利用它所擁有的關于視頻內容和我個人資料的信息。
協同過濾:他們依賴于相似用戶喜歡相似物品的假設。用戶和/或項目之間的相似性度量用于提出建議。
羨慕討論了一種非常流行的協同過濾技術——矩陣分解。
推薦系統有兩個實體-用戶和物品(物品的范圍十分廣泛,可以是實際出售的產品,也可以是視頻,文章等)。假設有m個用戶和n個物品。我們推薦系統的目標是構建一個mxn矩陣(稱為效用矩陣),它由每個用戶-物品對的評級(或偏好)組成。最初,這個矩陣通常非常稀疏,因為我們只對有限數量的用戶-物品對進行評級。
這是一個例子。假設我們有4個用戶和5個超級英雄,我們試圖預測每個用戶對每個超級英雄的評價。這是我們的評分矩陣最初的樣子:

針對超級英雄等級4x5評分矩陣
現在,我們的目標是通過尋找用戶和項目之間的相似性來填充這個矩陣。例如,我們看到User3和User4對蝙蝠俠給出了相同的評級,所以我們可以假設用戶是相似的,他們對蜘蛛俠的感覺也是一樣的,并預測User3會給蜘蛛俠評級為4。然而,在實踐中,這并不是那么簡單,因為有多個用戶與許多不同的項交互。
在實踐中,通過將評分矩陣分解成兩個高而細的矩陣來填充矩陣。分解得到:
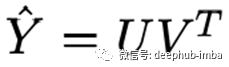
用戶-產品對的評分的預測是用戶和產品的點積
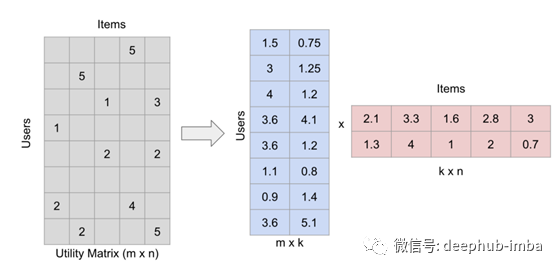
矩陣因式分解(為了方便說明,數字是隨機取的)
使用PyTorch實現矩陣分解,可以使用PyTorch提供的嵌入層對用戶和物品的嵌入矩陣(Embedding)進行分解,利用梯度下降法得到最優分解。
數據集
我使用了來自Kaggle的動畫推薦數據集:
https://www.kaggle.com/CooperUnion/anime-recommendations-database
我們有69600個用戶和9927個動漫。提供了6337241個評分。
目標
給定一組動畫的用戶評分,預測每一對用戶動畫的評分。
數據探索
我們看到有很多評級為-1的行,這表示缺少評級,我們可以去掉這些行。
anime_ratings_df = pd.read_csv("rating.csv")
anime_ratings_df.shape
print(anime_ratings_df.head())
我們還可以查看評分的分布和每個用戶的評分數量。
Counter(anime_ratings.rating)

每個用戶的平均評分數
np.mean(anime_ratings.groupby(['user_id']).count()['anime_id'])
輸出 91.05231321839081
數據預處理
因為我們將使用PyTorch的嵌入層來創建用戶和物品嵌入,所以我們需要連續的id來索引嵌入矩陣并訪問每個用戶/項目嵌入。
def encode_column(column):
""" Encodes a pandas column with continous IDs"""
keys = column.unique()
key_to_id = {key:idx for idx,key in enumerate(keys)}
return key_to_id, np.array([key_to_id[x] for x in column]), len(keys)
anime_df, num_users, num_anime, user_ids, anime_ids = encode_df(train_df)
print("Number of users :", num_users)
print("Number of anime :", num_anime)
anime_df.head()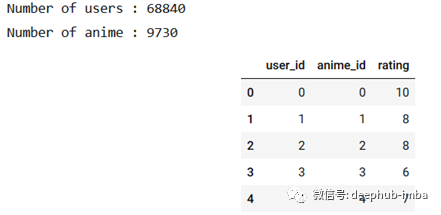
訓練
我們的目標是為每個用戶和每個物品找到最佳的嵌入向量。然后,我們可以通過獲取用戶嵌入和物品嵌入的點積,對任何用戶和物品進行預測
成本函數:我們目標是使評分矩陣的均方誤差最小。這里的N是評分矩陣中非空白元素的數量。
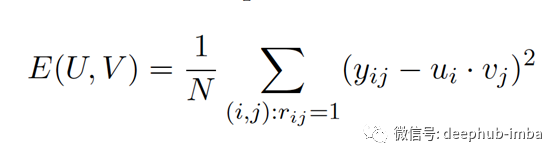
def cost(df, emb_user, emb_anime):
""" Computes mean square error"""
Y = create_sparse_matrix(df, emb_user.shape[0], emb_anime.shape[0])
predicted = create_sparse_matrix(predict(df, emb_user, emb_anime), emb_user.shape[0], emb_anime.shape[0], 'prediction')
return np.sum((Y-predicted).power(2))/df.shape[0]
預測
def predict(df, emb_user, emb_anime):
""" This function computes df["prediction"] without doing (U*V^T).
Computes df["prediction"] by using elementwise multiplication of the corresponding embeddings and then
sum to get the prediction u_i*v_j. This avoids creating the dense matrix U*V^T.
"""
df['prediction'] = np.sum(np.multiply(emb_anime[df['anime_id']],emb_user[df['user_id']]), axis=1)
return df用戶和物品向量的初始化
有許多方法來初始化嵌入權重,并沒有一個統一的答案,例如,fastai使用一種叫做截斷標準初始化器(Truncated Normal initializer)的東西。在我的實現中,我剛剛用(0,11 /K)的uniform值初始化了嵌入(隨機初始化在我的例子中運行得很好!)其中K是嵌入矩陣中因子的數量。K是一個超參數,通常是由經驗決定的——它不應該太小,因為你想讓你的嵌入學習足夠的特征,但你也不希望它太大,因為它會開始過度擬合你的訓練數據,增加計算時間。
def create_embeddings(n, K):
"""
Creates a random numpy matrix of shape n, K with uniform values in (0, 11/K)
n: number of items/users
K: number of factors in the embedding
"""
return 11*np.random.random((n, K)) / K創建稀疏效用矩陣:由于我們的成本函數需要效用矩陣,我們需要一個函數來創建這個矩陣。
def create_sparse_matrix(df, rows, cols, column_name="rating"):
""" Returns a sparse utility matrix"""
return sparse.csc_matrix((df[column_name].values,(df['user_id'].values, df['anime_id'].values)),shape=(rows, cols))梯度下降
梯度下降方程為:
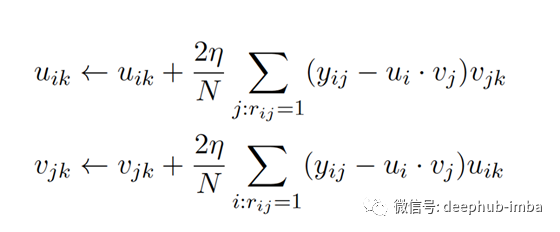
我在實現過程中使用了動量,該動量可以幫助加快相關方向上的梯度下降并抑制振蕩,從而加快收斂速度。我還添加了正則化功能,以確保我的模型不會過度適合訓練數據。因此,我的代碼中的梯度下降方程比上述方程稍微復雜。
正則成本函數為:

def gradient_descent(df, emb_user, emb_anime, iterations=2000, learning_rate=0.01, df_val=None):
"""
Computes gradient descent with momentum (0.9) for given number of iterations.
emb_user: the trained user embedding
emb_anime: the trained anime embedding
"""
Y = create_sparse_matrix(df, emb_user.shape[0], emb_anime.shape[0])
beta = 0.9
grad_user, grad_anime = gradient(df, emb_user, emb_anime)
v_user = grad_user
v_anime = grad_anime
for i in range(iterations):
grad_user, grad_anime = gradient(df, emb_user, emb_anime)
v_user = beta*v_user + (1-beta)*grad_user
v_anime = beta*v_anime + (1-beta)*grad_anime
emb_user = emb_user - learning_rate*v_user
emb_anime = emb_anime - learning_rate*v_anime
if(not (i+1)%50):
print("\niteration", i+1, ":")
print("train mse:", cost(df, emb_user, emb_anime))
if df_val is not None:
print("validation mse:", cost(df_val, emb_user, emb_anime))
return emb_user, emb_anime
在驗證集上預測
因為我們無法為我們的訓練集中未遇到的用戶和動漫(冷啟動問題)做出預測,所以我們需要從看不見的數據集中刪除它們。
def encode_new_data(valid_df, user_ids, anime_ids):
""" Encodes valid_df with the same encoding as train_df.
"""
df_val_chosen = valid_df['anime_id'].isin(anime_ids.keys()) & valid_df['user_id'].isin(user_ids.keys())
valid_df = valid_df[df_val_chosen]
valid_df['anime_id'] = np.array([anime_ids[x] for x in valid_df['anime_id']])
valid_df['user_id'] = np.array([user_ids[x] for x in valid_df['user_id']])
return valid_df我們的模型略微過擬合了訓練數據,因此可以增加正則化因子(lambda)以使其更好地泛化。
train_mse = cost(train_df, emb_user, emb_anime)
val_mse = cost(valid_df, emb_user, emb_anime)
print(train_mse, val_mse)輸出:6.025304207874527 11.735503902293352
讓我們看看預測:
valid_df[70:80].head()
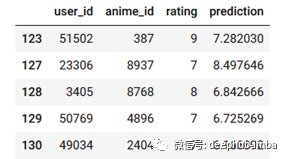
鑒于這些評分僅基于用戶行為之間的相似性,在1-10的評分范圍內,均方根值僅為3.4算是不錯了。它顯示了即使如此簡單,矩陣分解仍然具有多么強大的功能。
矩陣分解是一種非常簡單和方便的方法。但是,它也有缺陷,其中之一已經在我們的實現中遇到:
冷啟動問題
我們無法對訓練數據中從未遇到過的項目和用戶進行預測,因為我們沒有為它們提供嵌入。
冷啟動問題可以通過許多方式來解決,包括推薦流行的項目,讓用戶對一些項目進行評級,使用基于內容的方法,直到我們有足夠的數據來使用協同過濾。
很難包含關于用戶/物品的附加上下文
我們只使用用戶id和物品id來創建嵌入。我們不能在實現中使用關于用戶和項的任何其他信息。有一些復雜的基于內容的協同過濾模型可以用來解決這個問題。
評級并不總是可用的
很難從用戶那里得到反饋。大多數用戶只有在真正喜歡或絕對討厭某樣東西的時候才會給它打分。在這種情況下,我們通常不得不想出一種方法來衡量隱性反饋,并使用負采樣技術來想出一個合理的訓練集。
上述內容就是如何使用PyTorch進行矩陣分解進行動漫的推薦,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





