溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“用于數據分析的SQL技術有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
了解數據集
學習數據分析的最好方法是什么?通過在一個數據集上執行它!
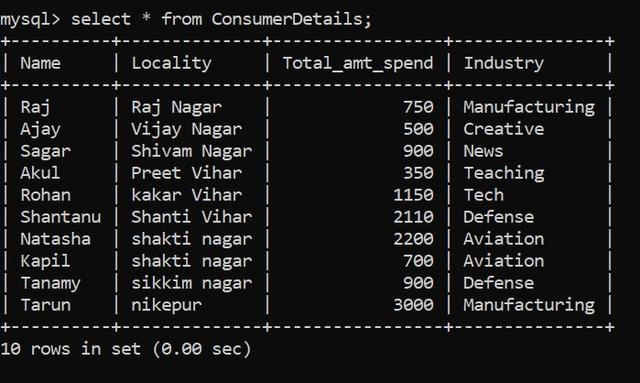
為此,我創建了一個零售商店的虛擬數據集。客戶數據表由ConsumerDetails表示。
我們的數據集由以下列組成:
Name –消費者的名稱
Locality –客戶所在地
Total_amt_spend –消費者在商店中花費的總金額
Industry –它表示消費者所屬的行業
注:我們將使用MySQL5.7進行實驗。
SQL技術1–計算行和項
Count函數
我們將從最簡單的查詢開始分析,即計算表中的行數。我們將使用函數COUNT()來完成此操作。
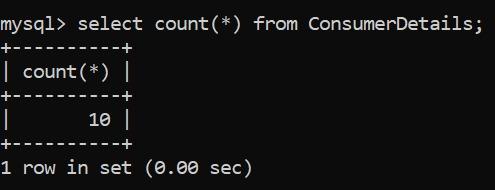
太好了!現在我們知道表中的行數是10。在一個小的測試數據集上使用這個函數似乎沒用。但是當你的行數達到數百萬時,它會有很大的幫助!
Distinct函數
很多時候,我們的數據表中充滿了重復的值。為了獲得獨一的值,我們使用了不同的函數。
在我們的數據集中,我們如何找到客戶所屬的行業?
你猜對了。我們可以通過使用DISTINCT函數來實現這一點。
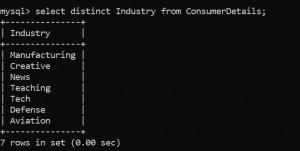
你甚至可以使用count和distinct一起計算唯一行的數量。你可以參考以下查詢:

SQL技術2–聚合函數
聚合函數是任何數據分析的基礎。它們為我們提供了數據集的概述。我們將討論的一些函數是–SUM()、AVG()和STDDEV()。
SUM函數
我們使用SUM()函數計算表中數值列的和。
我們來計算一下每位顧客的消費總額:
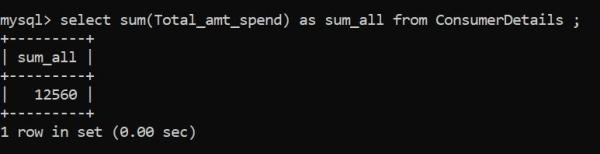
在上面的例子中,sum_all是存儲sum值的變量。消費者的消費總額是12560盧比。
AVG函數
AVG()函數計算平均值。讓我們找出消費者對我們零售店的平均支出:
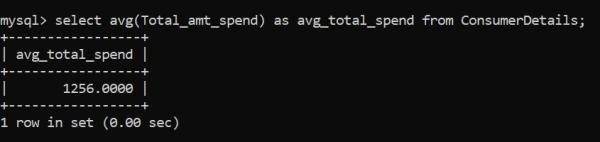
顧客在零售店的平均消費額為1256盧比。
STDDEV函數
如果你查看了數據集,然后查看了消費者的平均支出值,你會發現有些東西遺漏了。平均值并不能提供完整的理解,所以讓我們找到另一個重要的指標——標準差。函數為STDDEV()。
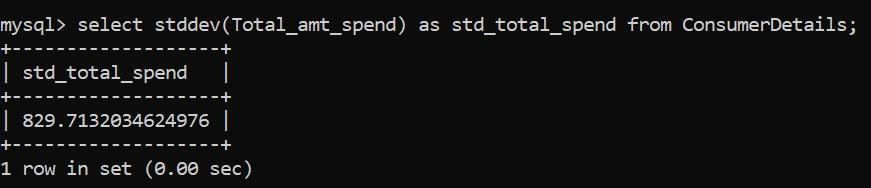
標準差為829.7,這意味著消費者的支出之間存在很大差距!
SQL技術3–極值識別
下一種類型的分析是確定極值,這將有助于你更好地理解數據。
Max函數
可以使用MAX()函數標識最大數值。讓我們看看如何應用它:
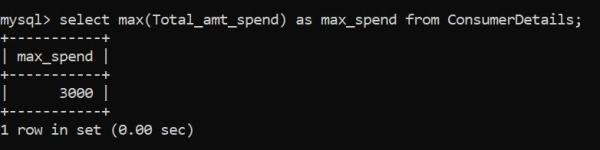
消費者在零售店的最高消費額是3000盧比。
Min函數
與max函數類似,我們有MIN()函數來標識給定列中的最小數值:
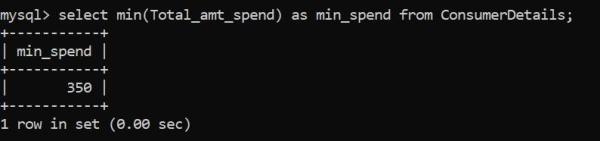
零售店消費者的最低消費額是350盧比。
SQL技術4–數據切片
現在,讓我們關注數據分析中最重要的部分之一——數據切片。分析的這一部分將構成高級查詢的基礎,并幫助你根據某種條件檢索數據。
假設零售店希望找到來自某個地方的客戶,特別是Shakti Nagar和Shanti Vihar地區。
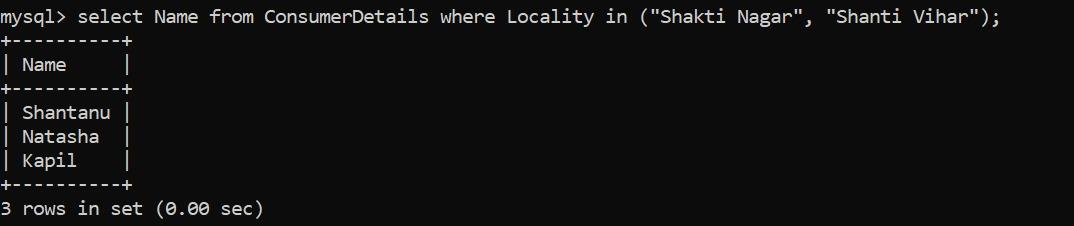
太好了,我們有3個客戶!我們使用WHERE子句根據消費者應該居住在當地的條件篩選出數據—Shakti Nagar和Shanti Vihar。
我沒有在這里使用OR條件。相反,我使用了IN運算符,它允許我們在WHERE子句中指定多個值。
我們需要找到那些居住在特定地區(Shakti Nagar和Shanti Vihar)且消費金額超過2000盧比的客戶。
在我們的數據集中,只有Shantanu和Natasha滿足這些條件。由于這兩個條件都需要滿足,所以和條件更適合這里。讓我們看看另一個例子。
這一次,零售店希望找回所有消費在1000盧比到2000盧比之間的消費者,以便推出特別的營銷優惠。
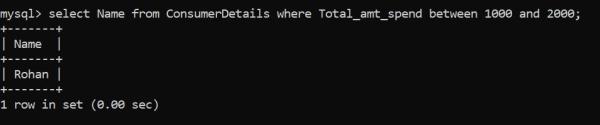
另一種寫同樣語句的方法是:

只有Rohan在滿足這個標準!
太好了!我們已經走到一半了。讓我們在迄今所獲得的知識基礎上再接再厲。
SQL技術5–限制數據
Limit
假設我們要查看由數百萬條記錄組成的數據表。我們不能直接使用SELECT語句,因為這會將整個表轉儲到我們的屏幕上,這既麻煩又計算密集。我們可以使用Limit:
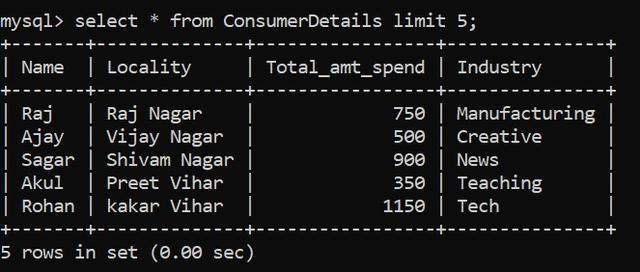
上面的SQL命令幫助我們顯示表的前5行。
OFFSET
如果你只想選擇第四行和第五行,你會怎么做?我們將使用OFFSET。OFFSET將跳過指定的行數。讓我們看看它是如何工作的:
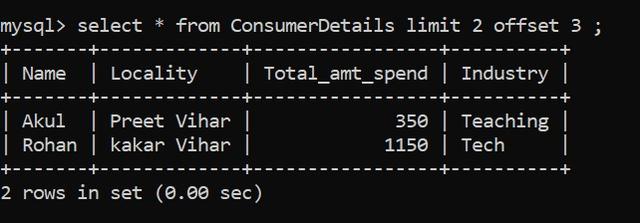
SQL技術6–數據排序
對數據進行分類有助于我們對數據進行觀察。我們可以使用關鍵字ORDER by來執行排序過程。
ORDER BY
關鍵字可用于按升序或降序對數據進行排序。默認情況下,ORDER BY關鍵字按升序對數據排序。
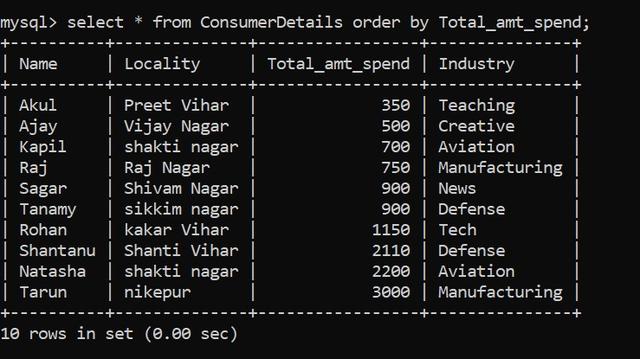
讓我們看一個示例,其中我們根據Total_amt_spend列按升序對數據進行排序:
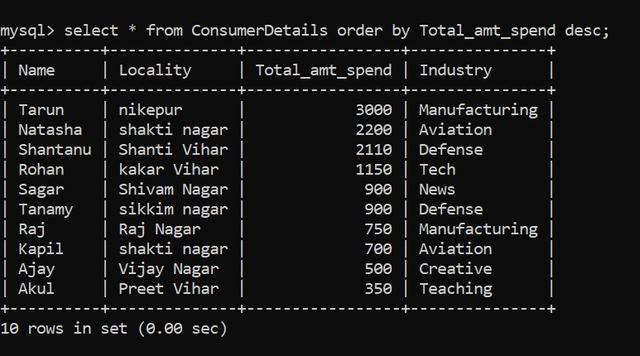
要將數據集按降序排序,可以按照以下命令進行操作:
SQL技術7–過濾模式
在前面的部分中,我們學習了如何根據一個或多個條件過濾數據。在這里,我們將學習匹配指定的模式列。為此,我們將首先了解LIKE運算符和通配符。
LIKE
LIKE在WHERE子句中用于搜索列中的指定模式。
通配符
通配符用于替換字符串中的一個或多個字符。它們與LIKE運算符一起使用。最常見的兩個通配符是:
%,表示0個或更多個字符
_,它代表一個字符
在我們的虛擬零售數據集中,假設我們想要所有以“Nagar”結尾的地區。花點時間來理解問題陳述,并思考如何解決這個問題。
讓我們試著把這個問題分解一下。我們需要以“Nagar”結尾的所有位置,并且在這個特定字符串之前可以有任意數量的字符。因此,我們可以在“Nagar”之前使用“%”通配符:
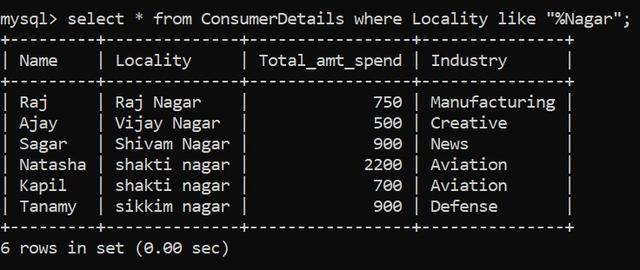
太棒了,我們有6個地方以這個名字結尾。注意,我們使用LIKE操作符來執行模式匹配。
接下來,我們將嘗試解決另一個基于模式的問題。我們需要第二個字符在他們各自的名字中有“a”的消費者的名字。
再一次,我建議你花點時間來理解這個問題,并想出一個解決它的邏輯。
讓我們把問題分解一下。這里,第二個字符需要是“a”。第一個字符可以是任何字符,所以我們用通配符_。
在第二個字符之后,可以有任意數量的字符,因此我們將這些字符替換為通配符“%”。最終的模式匹配如下所示:
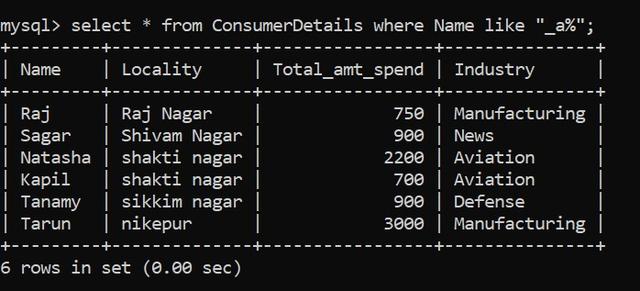
我們有6個人滿足了這個條件。
SQL技術8–分組、匯總數據和分組篩選
我們終于到了SQL中最強大的分析工具之一,使用GROUP BY語句對數據進行分組。
這個語句最有用的應用是尋找分類變量的分布。這是通過使用GROUPBY語句和聚合函數(如–COUNT、SUM、AVG等)來完成的。
讓我們用一個問題陳述來更好地理解這一點。零售商店希望找到與其所屬行業對應的客戶數量:
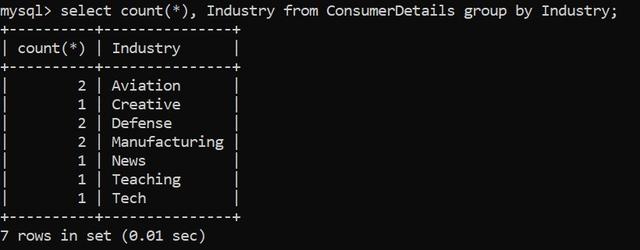
我們注意到,屬于不同行業的客戶數量或多或少是相同的。因此,讓我們改成根據客戶所屬行業分組,計算出他們的支出總額:
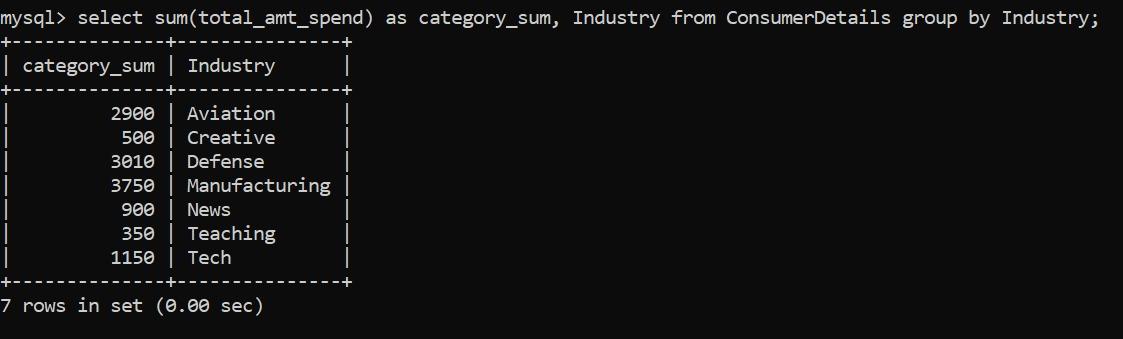
我們可以觀察到,消費金額最大的是屬于制造業的客戶。這看起來有點容易,對吧?讓我們繼續更改要求,讓它變得更復雜。
現在,零售商希望找到總銷售額大于2500的行業。為了解決這個問題,我們將再次根據行業數據進行分組,然后使用HAVING子句。
HAVING
HAVING子句與WHERE子句類似,但僅用于過濾分組的數據。記住,它總是在group by語句之后。

我們只有3個類別滿足條件-航空,國防和制造業。但為了更清楚,我還將添加ORDER BY關鍵字,使其更直觀:

“用于數據分析的SQL技術有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





