溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
編輯:zone
來源:數據管道
作者:艾德寶器
Abstract
Pandas是一個開源的Python數據分析庫,結合 NumPy 和 Matplotlib 類庫,可以在內存中進行高性能的數據清洗、轉換、分析及可視化工作。
對于數據開發工程師或分析師而言,SQL 語言是標準的數據查詢工具。本文提供了一系列的示例,說明如何使用pandas執行各種SQL操作。
Pandas簡介
Pandas把結構化數據分為了三類:
Series,可以理解為一個一維的數組,只是index可以自己改動。
DataFrame,一個類似于表格的數據類型的2維結構化數據。
Panel,3維的結構化數據。
Dataframe實例:

對于DataFrame,有一些固有屬性:

SQL VS Pandas
SELECT(數據選擇)
在SQL中,選擇是使用逗號分隔的列列表(或*來選擇所有列):
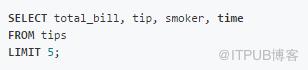
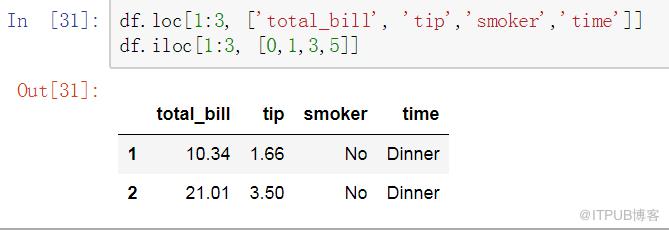
在Pandas中,選擇不但可根據列名稱選取,還可以根據列所在的位置選取。相關語法如下:
loc,基于列label,可選取特定行(根據行index)
iloc,基于行/列的位置
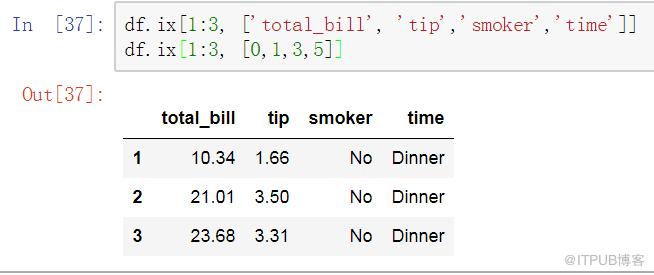
ix,為loc與iloc的混合體,既支持label也支持position
at,根據指定行index及列label,快速定位DataFrame的元素;
iat,與at類似,不同的是根據position來定位的;

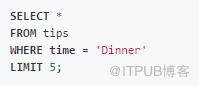
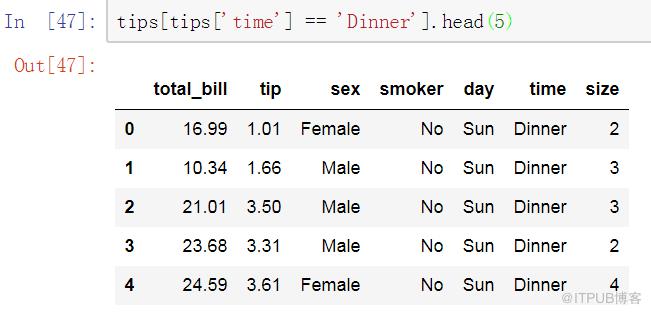
WHERE(數據過濾)
在SQL中,過濾是通過WHERE子句完成的:
在pandas中,Dataframe可以通過多種方式進行過濾,最直觀的是使用布爾索引:
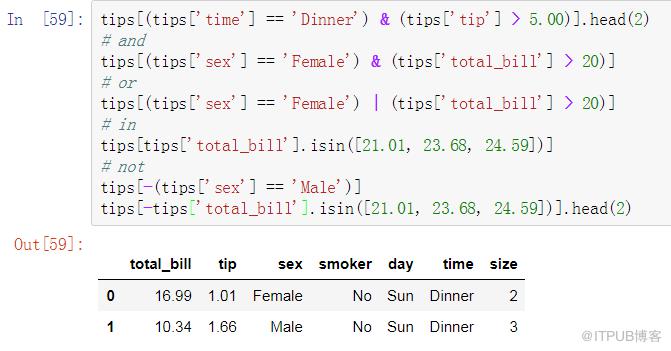
在where子句中常常會搭配and, or, in, not關鍵詞,Pandas中也有對應的實現:
SQL:
Pandas:
在where字句中搭配NOT NULL可以獲得某個列不為空的項,Pandas中也有對應的實現:
SQL:
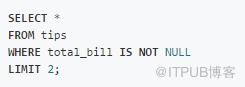
Pandas:

DISTINCT(數據去重)
SQL:
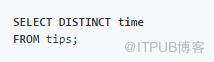
Pandas:
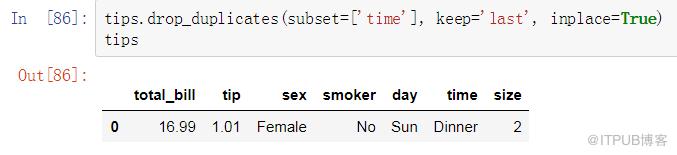
寶器帶你畫重點:
subset,為選定的列做數據去重,默認為所有列;
keep,可選擇{'first', 'last', False},保留重復元素中的第一個、最后一個,或全部刪除;
inplace ,Pandas 中 inplace 參數在很多函數中都會有,它的作用是:是否在原對象基礎上進行修改,默認為False,返回一個新的Dataframe;若為True,不創建新的對象,直接對原始對象進行修改。
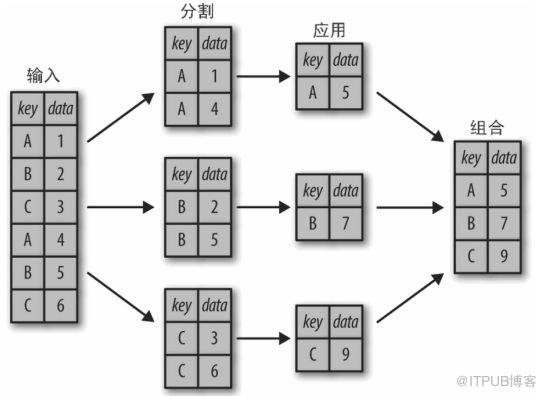
GROUP BY(數據分組)
groupby()通常指的是這樣一個過程:我們希望將數據集拆分為組,應用一些函數(通常是聚合),然后將這些組組合在一起:
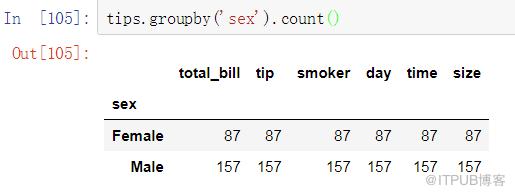
常見的SQL操作是獲取數據集中每個組中的記錄數。
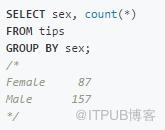
Pandas中對應的實現:

注意,在Pandas中,我們使用size()而不是count()。這是因為count()將函數應用于每個列,返回每個列中的非空記錄的數量。具體如下:
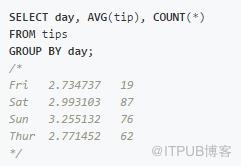
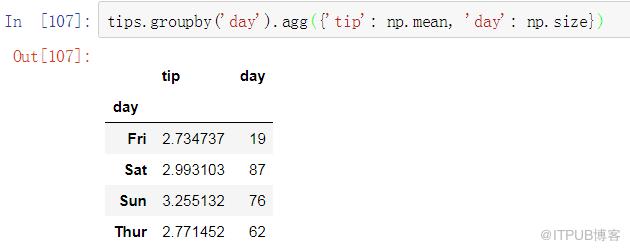
還可以同時應用多個函數。例如,假設我們想要查看每個星期中每天的小費金額有什么不同。
SQL:
Pandas:
更多關于Groupy和數據透視表內容請閱讀:
這些祝福和干貨比那幾塊錢的紅包重要的多!
JOIN(數據合并)
可以使用join()或merge()執行連接。
默認情況下,join()將聯接其索引上的DataFrames。
每個方法都有參數,允許指定要執行的連接類型(LEFT, RIGHT, INNER, FULL)或要連接的列(列名或索引)

現在看一下不同的連接類型的SQL和Pandas實現:
INNER JOIN
SQL:

Pandas:

LEFT OUTER JOIN
SQL:
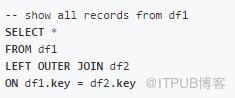
Pandas:
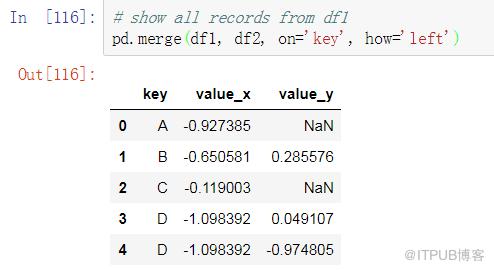
RIGHT JOIN
SQL:
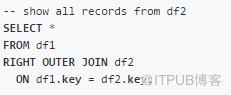
Pandas:
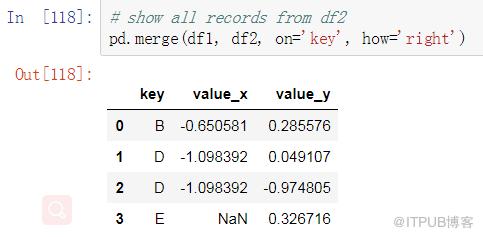
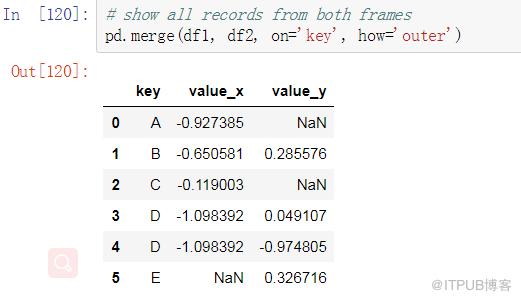
FULL JOIN
SQL:

Pandas:
ORDER(數據排序)
SQL:
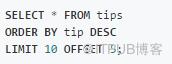
Pandas:
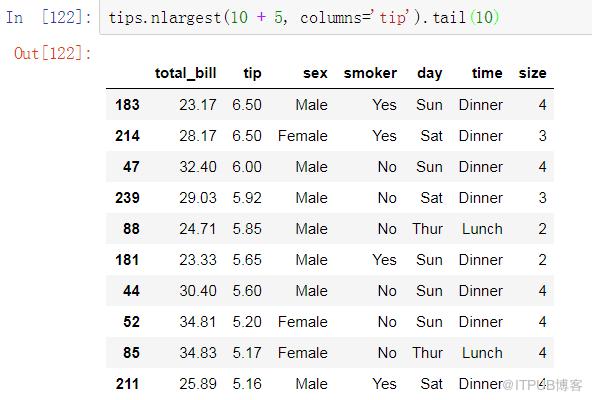
UPDATE(數據更新)
SQL:

Pandas:

DELETE(數據刪除)
SQL:
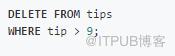
Pandas:

總結:
本文從Pandas里面基本數據結構Dataframe的固定屬性開始介紹,對比了做數據分析過程中的一些常用SQL語句的Pandas實現。
參考:
http://m.v.qq.com/play/play.htmlcoverid=&vid=q0836f6kewx&ptag=4_6.7.0.22106_qq
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





