溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python中普通程序員如何了解日志系統的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
當我們在做系統開發時,日志系統是繞不開的話題。作為日志系統的最終使用者,我們會接觸不同的日志系統,比如 log4j、 logback 和 slf4j 等等,還會接觸到日志系統的各種概念,比如 Formatter、Appender 和 Priority 等。這些日志系統有什么區別,這些概念又該怎么理解呢?
今天我們就聊下:我們普通程序員,也就是日志系統最終使用者,可以怎么理解日志系統。
Logging 系統的雛型
讓我們回到計算機世界的遠古時期或者我們剛剛接觸計算機世界的時期,那個時候我們有兩種調試程序的辦法:1)單步調試,一步步地跟蹤,查看代碼中變量的值。2) 是 printf 大法 —— 在特定的地方打印日志, 通過日志的輸出,幫助快速定位。
單步調試方法費時費力,但能準確定位問題。printf 大法簡單粗暴,需要嘗試,大部分情況能快速找到問題。單步調試和 printf 方法搭配使用,相得益彰。但是單步調試止步于 gdb 等調試工具,而 printf 大法最終發展出了一系列的日志系統。原因就在于單步調試在程序員調試才能用,而 printf 大法可以在調試和生產線上都能用,并且輸出的日志被各方面的人利用和解讀。
什么時候打印日志是個問題 —— Level
printf 大法是很簡陋的。在調試過程中,有可能日志打到很細粒度,比如每條數據的第三個字段是什么都打印出來了,但是真正運行又要把這些細粒度的日志刪除。等到下次調試,我們又要知道每條數據的第三個字段是什么了。為此,我們希望日志打印是智能:調試或者線上出問題的時候,各種細粒度的日志全部打印出來,正常運行的時候輸出一些最簡單的信息就可以了。
針對這個問題,日志系統引入日志級別(Level)的辦法解決。引入日志級別的概念之后,我們編程時打印日志,需要指明這條日志的級別。由于日志級別是最重要的參數,現在的日志系統都是直接通過使用不同的函數來指明級別的,包括 logger.TRACE、logger.DEGUB、logger.INFO、logger.WARN、logger.ERROR、logger.FATAL。其中級別的對比是 TRACE < DEBUG < INFO <WARN < ERROR < FATAL。同時系統運行行,我們將設定 log level設置在某一個級別上,那么級別優先級高的 log 都能打印出來,低的都不能打印出。例如,如果設置優先級為WARN,那么FATAL、ERROR、WARN 級別的log能正常輸出,而INFO、DEBUG、TRACE 級別的log則會被忽略。
我們編程時 DEBUG 或者 TRACE 級別打出細粒度的信息,比如每條數據的樣子。當我們調試時或者線上有問題時,我們將程序的當前日志級別設置成 TRACE 或者 DEBUG,從而將細粒度的信息打出來。而正常運行時,我們將當前日志級別設置成 INFO 或者 WARN 級別,從而忽略細粒度的信息,降低 IO 操作和提升系統性能。
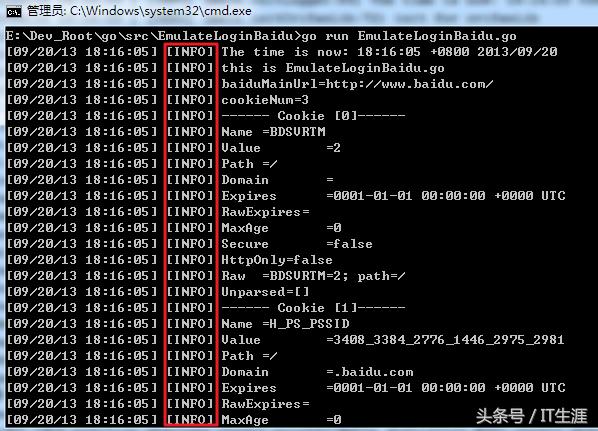
打印日志到哪里是還是一個問題 —— Appender
有了 Level,我們可以隨心意寫點 log 了,只要控制好日志級別就行。默認情況下,我們的日志是打印到 Console 里,我們直接人眼看。隨著時間的推移,情況變得復雜起來。比如我們需要將日志打入文件里,方便以后查看。即使日志打到文件,我們也需要登錄到機器才能查看,我們需要在發生錯誤時收到郵件或者短信。為了滿足這些需求,我們在日志系統中加入 Appender 部件。Appender 部件負責將日志寫的不同的目的。

比如下圖就是 Log4j 的日志配置示例。這個示例會打印出所有的信息,每次大小超過size,則這size大小的日志會自動存入按年份-月份建立的文件夾下面并進行壓縮,作為存檔。

日志系統可以自定多種 Appender,人們基于這套邏輯發明了一套日志收集和實時檢索的系統,也稱之為日志系統。在這里為了區別,我們將日志收集和檢索系統稱之為日志收集檢索系統。日志收集檢索系統一般有 Kafka 流、實時處理組件 Spark Streaming 或者 Storm、實時檢索系統 ElasticSearch 組成。后臺系統通過日志系統的 Appender 組件將日志打到 Kafka 流,然后 Spark Streaming 或者 Storm 處理流數據并將之寫入 ElasticSearch 檢索系統。這樣開發和運維就可以在 ElasticSearch 提供的 Web 查看可視化的日志了。日志收集檢索系統的主要好處是,1) 日志集中管理,不需要登錄到不同機器;2) 提供可視化的日志查看;3) 提供基于日志的監控、監測服務等。
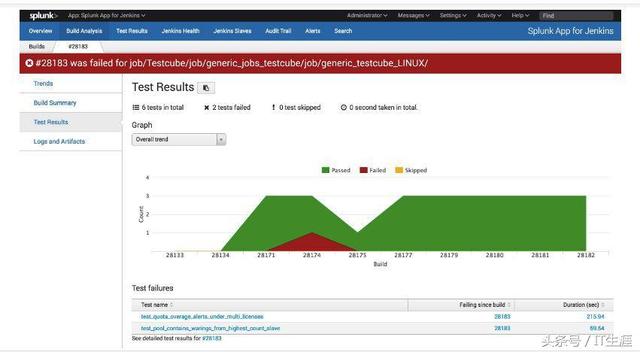
目前最有名的日志收集檢索系統應該是上圖的 Splunk 了。
日志什么樣也是個問題 —— Formatter
有了日志的 Level 和 Appender,我們還需要解決日志樣式的問題。一般情況,我們希望的日志格式包括:Level,函數名,文件名和打日志的代碼行數。這可以通過日志系統的 Formatter 組件來實現的。下圖是一個 Python 自定義的Formatter。
import logging def AltCustomFormatter(logging.Formatter): def __init__(self, fmt=None, datefmt=None): super(AltCustomFormatter, self).__init__(fmt, datefmt) def format(self, record): # 如果你添加了多個handler,你會發現我們的定制消息被重復了多次, # 我們在record里設置一個marker來避免 if record.levelno > logging.INFO and not hasattr(record, 'is_custom'): record.msg = "[%s, %s, %s] %s" % (record.filename, record.lineno, record.funcName, record.msg) record.is_custom = True return super(AltCustomFormatter, self).format(record)
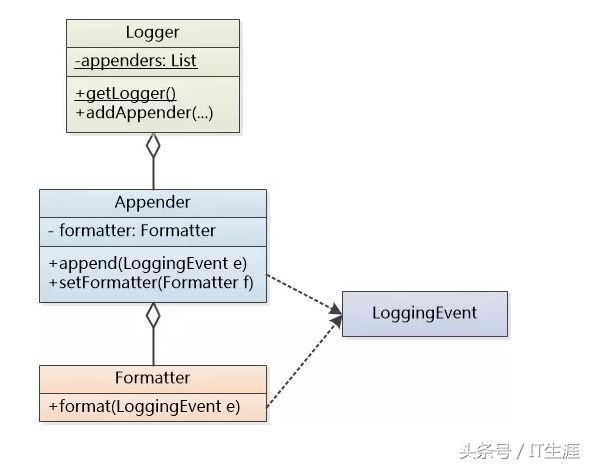
在引入 Level、Formater 和 Appender 概念之后,整個日志系統的架子算是搭起來了,如下圖所示。作為一個普通程序員,可以安心使用這個日志系統了。
高效地打印日志是另外一個問題 —— Efficient
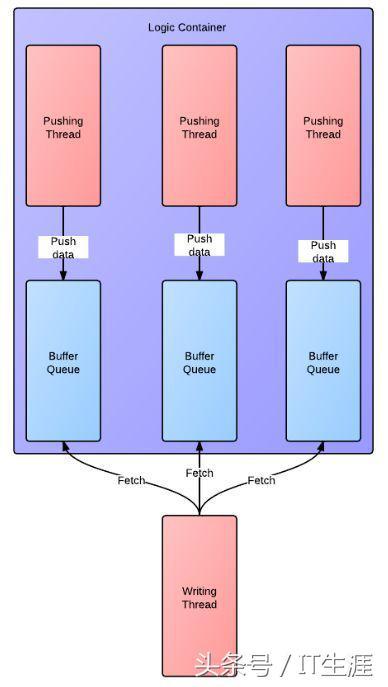
但是作為一個有追求的普通程序,我們想知道大規模系統的極限環境中,日志系統能不能撐得住。答案嘛,是按照上面設計的日志系統是撐不住的。因為大規模系統的極限環境,實時要求高,不能忍受寫文件或者寫網絡的延遲。怎么辦呢?有請對付 IO 延遲利器 —— Buffer。基于 Buffer,并考慮到 Buffer 所帶來的線程同步的問題, 人們設計了下面的方案。在這個方案中,每個線程生成一個 Buffer,然后寫線程輪詢從 Buffer 讀入信息,并寫目的地。在這套方案中,寫日志并不會導致服務延遲。
除了架構上的設計,還有一些小 trick 提高性能。比如我們在 log4j 官方 API 查到丑陋的 INFO 函數們。Java 語言不支持不定長參數的情況下,log4j 強行搞一個支持不定長的 INFO 函數,就只能靠著寫不同的函數重載,最終也只支持 9 個參數。
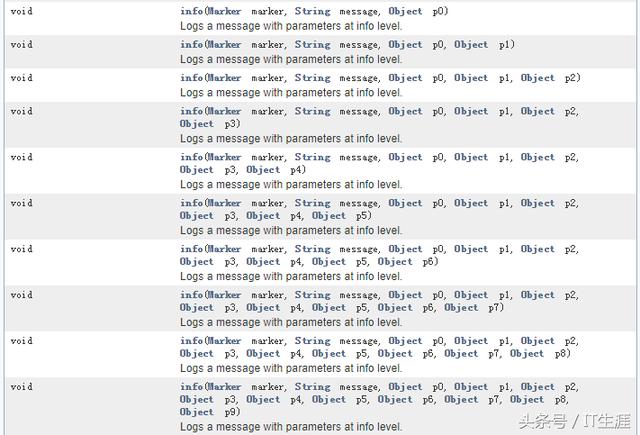
但這些丑陋的 INFO 是有意義的。這些丑陋的 INFO 是為了能夠實現下表中不定長參數的方式。這種不定長參數方式相比字符串拼接方式的區別在哪里呢? 當前級別是 ERROR 時,INFO 級別的信息是不用輸出的,字符串拼接方式還是要拼字符串,而不定長參數方式就可以不用拼接字符串了。

感謝各位的閱讀!關于“python中普通程序員如何了解日志系統”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





