溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python怎么實現RFM用戶分析模型”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
看這篇文章前源數據長這樣:

學完后只要敲一個回車,源數據就變成了這樣:
是不是心動了?OK,閑話少敘,我們來開動正餐!
RFM,是一種經典到頭皮發麻的用戶分類、價值分析模型,同時,這個模型以直白著稱,直白到把需要的字段寫在了臉上,讓我們再念一遍:“R!F!M!”:
R,Rencency,即每個客戶有多少天沒回購了,可以理解為最近一次購買到現在隔了多少天。
F,Frequency,是每個客戶購買了多少次。
M,Monetary,代表每個客戶平均購買金額,這里也可以是累計購買金額。
這三個維度,是RFM模型的精髓所在,幫助我們把混雜一體的客戶數據分成標準的8類,然后根據每一類用戶人數占比、金額貢獻等不同的特征,進行人、貨、場三重匹配的精細化運營。
用Python建立RFM模型,整體建模思路分為五步,一言蔽之——“五步在手,模型你有”,分別是數據概覽、數據清洗、維度打分、分值計算和客戶分層。
01 數據概覽
我們的源數據是訂單表,記錄著用戶交易相關的字段:
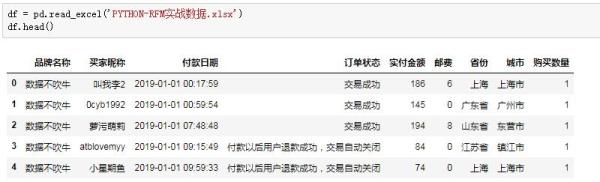
有個細節需要注意,訂單每一行代表著單個用戶的單次購買行為,什么意思呢?如果一個用戶在一天內購買了4次,訂單表對應記錄著4行,而在實際的業務場景中,一個用戶在一天內的多次消費行為,應該從整體上看作一次。
比如,我今天10點在必勝客天貓店買了個披薩兌換券,11點又下單了飲料兌換券,18點看到優惠又買了兩個冰淇淋兌換券。這一天內雖然我下單了3次,但最終這些兌換券我會一次消費掉,應該只算做一次完整的消費行為,這個邏輯會指導后面F值的計算。
我們發現在訂單狀態中,除了交易成功的,還有用戶退款導致交易關閉的,那還包括其他狀態嗎?Let me see see:

只有這兩種狀態,其中退款訂單對于我們模型價值不大,需要在后續清洗中剔除。
接著再觀察數據的類型和缺失情況:
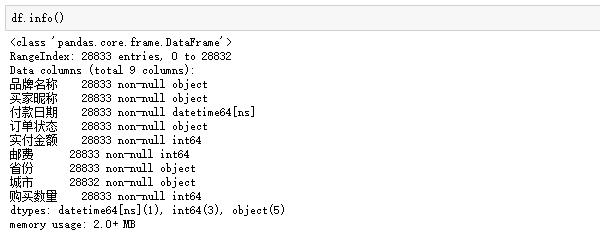
訂單一共28833行,沒有任何缺失值,Nice!類型方面,付款日期是時間格式,實付金額、郵費和購買數量是數值型,其他均為字符串類型。
02 數據清洗
剔除退款
在觀察階段,我們明確了第一個清洗的目標,就是剔除退款數據:

關鍵字段提取
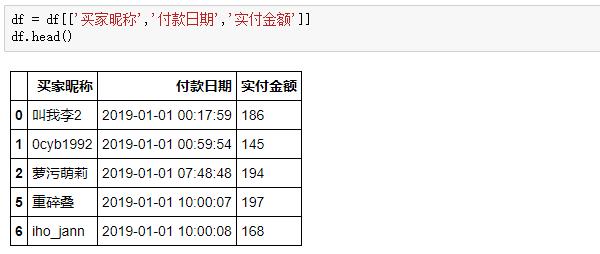
剔除之后,覺得我們訂單的字段還是有點多,而RFM模型只需要買家昵稱,付款時間和實付金額這3個關鍵字段,所以提取之:
關鍵字段構造
上面的基礎清洗告一段落,這一步關鍵在于構建模型所需的三個字段:R(最近一次購買距今多少天),F(購買了多少次)以及M(平均或者累計購買金額)。
首先是R值,即每個用戶最后一次購買時間距今多少天。如果用戶只下單過一次,用現在的日期減去付款日期即可;若是用戶多次下單,需先篩選出這個用戶最后一次付款的時間,再用今天減去它。
需要提醒的是,時間洪流越滾越兇,對應在時間格式中,就是距離今天越近,時間也就越“大”,舉個例子,2019年9月9日是要大于2019年9月1日的:

因此,要拿到所有用戶最近一次付款時間,只需要按買家昵稱分組,再選取付款日期的最大值即可:
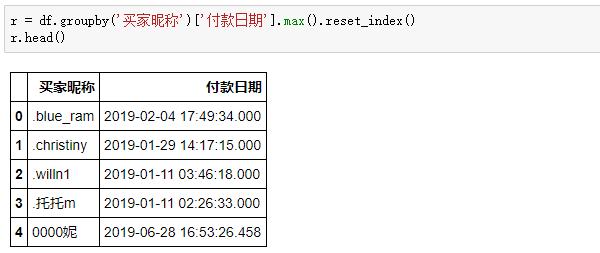
為了得到最終的R值,用今天減去每位用戶最近一次付款時間,就得到R值了,這份訂單是7月1日生成的,所以這里我們把“2019-7-1”當作“今天”:

接著來搞定F值,即每個用戶累計購買頻次。
在前面數據概覽階段,我們明確了“把單個用戶一天內多次下單行為看作整體一次”的思路,所以,引入一個精確到天的日期標簽,依照“買家昵稱”和“日期標簽”進行分組,把每個用戶一天內的多次下單行為合并,再統計購買次數:

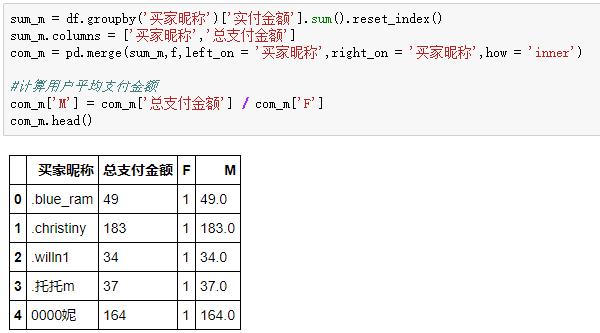
上一步計算出了每個用戶購買頻次,這里我們只需要得到每個用戶總金額,再用總金額除以購買頻次,就能拿到用戶平均支付金額:
最后,萬劍歸宗,三個指標合并:
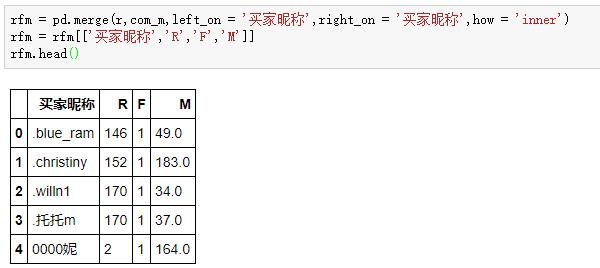
至此,我們完成了模型核心指標的計算,算是打掃干凈了屋子再請客。
03 維度打分
維度確認的核心是分值確定,按照設定的標準,我們給每個消費者的R/F/M值打分,分值的大小取決于我們的偏好,即我們越喜歡的行為,打的分數就越高:
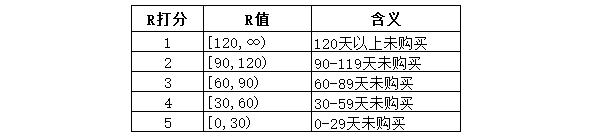
以R值為例,R代表了用戶有多少天沒來下單,這個值越大,用戶流失的可能性越大,我們當然不希望用戶流失,所以R越大,分值越小。
F值代表了用戶購買頻次,M值則是用戶平均支付金額,這兩個指標是越大越好,即數值越大,得分越高。
RFM模型中打分一般采取5分制,有兩種比較常見的方式,一種是按照數據的分位數來打分,另一種是依據數據和業務的理解,進行分值的劃分。這里希望同學們加深對數據的理解,進行自己的分值設置,所以講述過程中使用的是第二種,即提前制定好不同數值對應的分值。
R值根據行業經驗,設置為30天一個跨度,區間左閉右開:
F值和購買頻次掛鉤,每多一次購買,分值就多加一分:
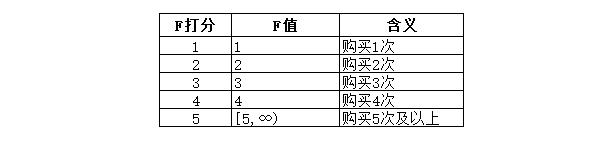
我們可以先對M值做個簡單的區間統計,然后分組,這里我們按照50元的一個區間來進行劃分:
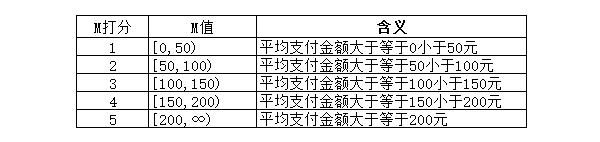
這一步我們確定了一個打分框架,每一位用戶的每個指標,都有了與之對應的分值。
04 分值計算
分值的劃分邏輯已經確定,看著好像有點麻煩。下面我們有請潘大師(Pandas)登場,且看他如何三拳兩腳就搞定這麻煩的分組邏輯,先拿R值打個樣:
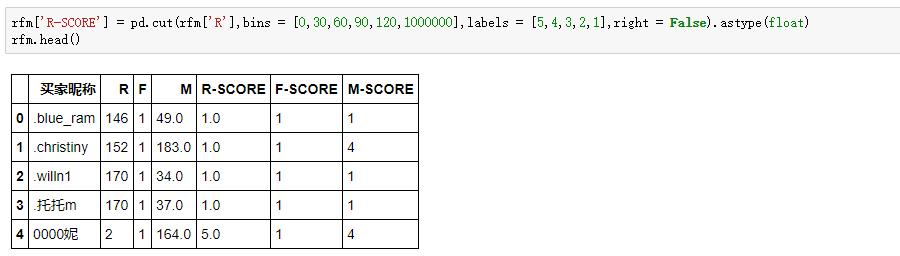
滄海橫流,方顯潘大師本色,短短一行代碼就搞定了5個層級的打分。Pandas的cut函數,我們復習一下:
第一個參數傳入要切分的數據列。
bins參數代表我們按照什么區間進行分組,上面我們已經確定了R值按照30天的間隔進行分組,輸入[0,30,60,90,120,1000000]即可,最后一個數值設置非常大,是為了給分組一個容錯空間,允許出現極端大的值。
right表示了右側區間是開還是閉,即包不包括右邊的數值,如果設置成False,就代表[0,30),包含左側的分組數據而不含右側,若設置為True,則是[0,30],首尾都包含。
labels和bins切分的數組前后呼應,什么意思呢?bins設置了6個數值,共切分了5個分組,labels則分別給每個分組打標簽,0-30是5分,30-60是4分,依此類推。
接著,F和M值就十分容易了,按照我們設置的值切分就好:

第一輪打分已經完成,下面進入第二輪打分環節。
客官不要緊臟,面試都還不止兩輪呢,倫家RFM模型哪有那么隨便的。
現在R-SCORE、F-SCORE、M-SCORE在1-5幾個數之間,如果把3個值進行組合,像111,112,113...這樣可以組合出125種結果,過多的分類和不分類本質是一樣的。所以,我們通過判斷每個客戶的R、F、M值是否大于平均值,來簡化分類結果。
因為每個客戶和平均值對比后的R、F、M,只有0和1(0表示小于平均值,1表示大于平均值)兩種結果,整體組合下來共有8個分組,是比較合理的一個情況。我們來判斷用戶的每個分值是否大于平均值:

Python中判斷后返回的結果是True和False,對應著數值1和0,只要把這個布爾結果乘上1,True就變成了1,False變成了0,處理之后更加易讀。
05 客戶分層
回顧一下前幾步操作,清洗完之后我們確定了打分邏輯,然后分別計算每個用戶的R、F、M分值(SCORE),隨后,用分值和對應的平均值進行對比,得到了是否大于均值的三列結果。至此,建模所需的所有數據已經準備就緒,剩下的就是客戶分層了。
RFM經典的分層會按照R/F/M每一項指標是否高于平均值,把用戶劃分為8類,我們總結了一下,具體像下面表格這樣:

由于傳統的分類,部分名稱有些擰巴,像大多數分類前都冠以“重要”,“潛力”和“深耕”到底有什么區別?“喚回”和“挽回”有什么不一樣?
本著清晰至上原則,我們對原來的名稱做了適當的改進。強調了潛力是針對消費(平均支付金額),深耕是為了提升消費頻次,以及重要喚回客戶其實和重要價值客戶非常相似,只是最近沒有回購了而已,應該做流失預警等等。這里只是拋磚引玉,提供一個思路,總之,一切都是為了更易理解。
對于每一類客戶的特征,我們也做了簡單的詮釋,比如重要價值客戶,就是最近購買我們的產品,且在整個消費生命周期中購買頻次較高,平均每次支付金額也高。其他的分類也是一樣邏輯,可以結合詮釋來強化理解。下面,我們就用Python來實現這一分類。
先引入一個人群數值的輔助列,把之前判斷的R\F\M是否大于均值的三個值給串聯起來:
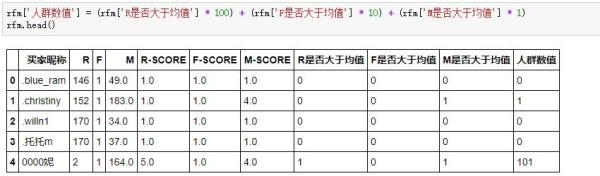
人群數值是數值類型,所以位于前面的0就自動略過,比如1代表著“001”的高消費喚回客戶人群,10對應著“010”的一般客戶。
為了得到最終人群標簽,再定義一個判斷函數,通過判斷人群數值的值,來返回對應的分類標簽:

最后把標簽分類函數應用到人群數值列:
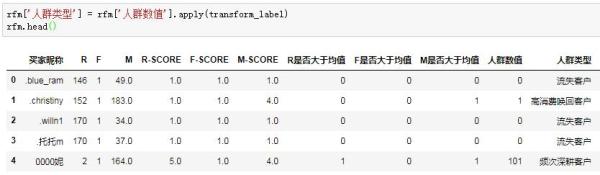
客戶分類工作的完成,宣告著RFM模型建模的結束,每一位客戶都有了屬于自己的RFM標簽。
RFM模型結果分析
其實到上一步,已經走完了整個建模流程,但是呢,一切模型結果最終都要服務于業務,所以,最后我們基于現有模型結果做一些拓展、探索性分析。
查看各類用戶占比情況:

探究不同類型客戶消費金額貢獻占比:
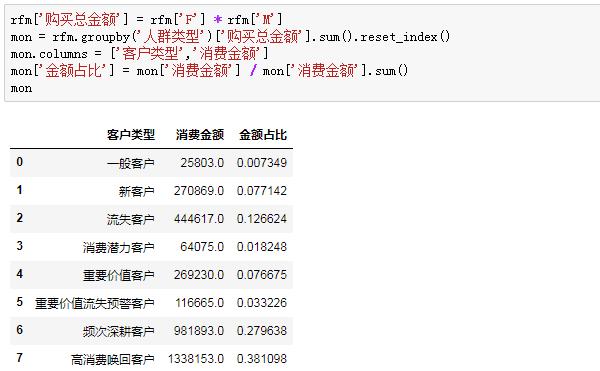
結果可視化之(可視化代碼留給大家自行嘗試):
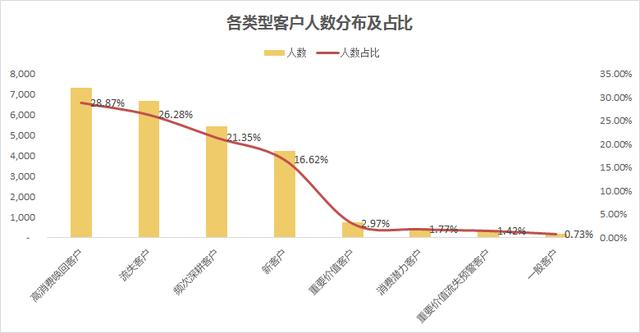
從上面結果,我們可以快速得到一些推斷:
客戶流失情況嚴峻,高消費喚回客戶、流失客戶占比超過50%,怎么樣制定針對性喚回策略迫在眉睫。
重要價值客戶占比僅2.97%,還有三個客戶占比甚至不足2%,我們模型打分可能不夠科學,可以進一步調整打分區間進行優化。
...
再結合金額進行分析:
高消費喚回客戶人數占比28.87%,金額占比上升到了38.11%,這部分客戶是消費的中流砥柱,他們為什么流失,應結合訂單和購買行為數據進一步展開挖掘。
頻次深耕客戶金額占比緊隨其后,這部分客戶的特征是近期有消費、消費頻次低、消費金額高,和高消費喚回客戶僅有購買時間上的不同,如何避免這部分客戶向高消費喚回客戶的流轉是我們要思考的主要命題。
流失客戶人數占比26.28%,金額占比僅12.66%,這部分客戶中有多少是褥羊毛用戶,有多少是目標用戶,對我們引流策略能夠進行怎么樣的指導和調整?
“Python怎么實現RFM用戶分析模型”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





