溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用Python進行下載”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1.使用requests
你可以使用requests模塊從一個URL下載文件。
考慮以下代碼:

你只需使用requests模塊的get方法獲取URL,并將結果存儲到一個名為“myfile”的變量中。然后,將這個變量的內容寫入文件。
2.使用wget

你還可以使用Python的wget模塊從一個URL下載文件。你可以使用pip按以下命令安裝wget模塊:
考慮以下代碼,我們將使用它下載Python的logo圖像。

在這段代碼中,URL和路徑(圖像將存儲在其中)被傳遞給wget模塊的download方法。
3.下載重定向的文件
在本節中,你將學習如何使用requests從一個URL下載文件,該URL會被重定向到另一個帶有一個.pdf文件的URL。該URL看起來如下:

要下載這個pdf文件,請使用以下代碼:

在這段代碼中,我們第一步指定的是URL。然后,我們使用request模塊的get方法來獲取該URL。在get方法中,我們將allow_redirects設置為True,這將允許URL中的重定向,并且重定向后的內容將被分配給變量myfile。
最后,我們打開一個文件來寫入獲取的內容。
4.分塊下載大文件
考慮下面的代碼:

首先,我們像以前一樣使用requests模塊的get方法,但是這一次,我們將把stream屬性設置為True。
接著,我們在當前工作目錄中創建一個名為PythonBook.pdf的文件,并打開它進行寫入。
然后,我們指定每次要下載的塊大小。我們已經將其設置為1024字節,接著遍歷每個塊,并在文件中寫入這些塊,直到塊結束。
不漂亮嗎?不要擔心,稍后我們將顯示一個下載過程的進度條。
5.下載多個文件(并行/批量下載)
要同時下載多個文件,請導入以下模塊:

我們導入了os和time模塊來檢查下載文件需要多少時間。ThreadPool模塊允許你使用池運行多個線程或進程。
讓我們創建一個簡單的函數,將響應分塊發送到一個文件:
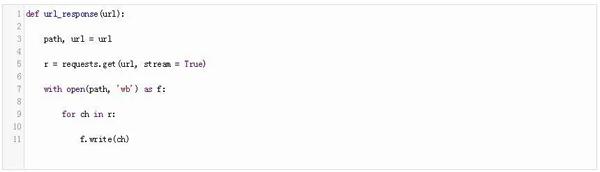
這個URL是一個二維數組,它指定了你要下載的頁面的路徑和URL。
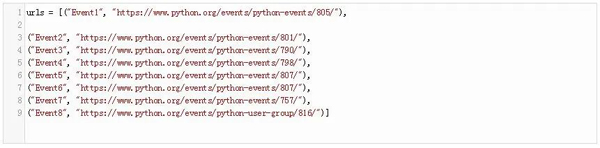
就像在前一節中所做的那樣,我們將這個URL傳遞給requests.get。最后,我們打開文件(URL中指定的路徑)并寫入頁面內容。
現在,我們可以分別為每個URL調用這個函數,我們也可以同時為所有URL調用這個函數。讓我們在for循環中分別為每個URL調用這個函數,注意計時器:

現在,使用以下代碼行替換for循環:

運行該腳本。
6.使用進度條進行下載
進度條是clint模塊的一個UI組件。輸入以下命令來安裝clint模塊:

考慮以下代碼:
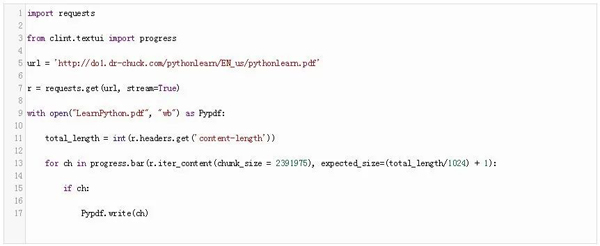
在這段代碼中,我們首先導入了requests模塊,然后,我們從clint.textui導入了進度組件。唯一的區別是在for循環中。在將內容寫入文件時,我們使用了進度條模塊的bar方法。
7.使用urllib下載網頁
在本節中,我們將使用urllib下載一個網頁。
urllib庫是Python的標準庫,因此你不需要安裝它。
以下代碼行可以輕松地下載一個網頁:

在這里指定你想將文件保存為什么以及你想將它存儲在哪里的URL。

在這段代碼中,我們使用了urlretrieve方法并傳遞了文件的URL,以及保存文件的路徑。文件擴展名將是.html。
8.通過代理下載
如果你需要使用代理下載你的文件,你可以使用urllib模塊的ProxyHandler。請看以下代碼:

在這段代碼中,我們創建了代理對象,并通過調用urllib的build_opener方法來打開該代理,并傳入該代理對象。然后,我們創建請求來獲取頁面。
此外,你還可以按照官方文檔的介紹來使用requests模塊:
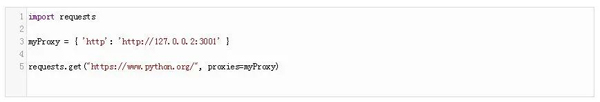
你只需要導入requests模塊并創建你的代理對象。然后,你就可以獲取文件了。
9.使用urllib3
urllib3是urllib模塊的改進版本。你可以使用pip下載并安裝它:

我們將通過使用urllib3來獲取一個網頁并將它存儲在一個文本文件中。
導入以下模塊:

在處理文件時,我們使用了shutil模塊。
現在,我們像這樣來初始化URL字符串變量:

然后,我們使用了urllib3的PoolManager ,它會跟蹤必要的連接池。

創建一個文件:

最后,我們發送一個GET請求來獲取該URL并打開一個文件,接著將響應寫入該文件:

10.使用Boto3從S3下載文件
要從Amazon S3下載文件,你可以使用Python boto3模塊。
在開始之前,你需要使用pip安裝awscli模塊:

對于AWS配置,請運行以下命令:

現在,按以下命令輸入你的詳細信息:
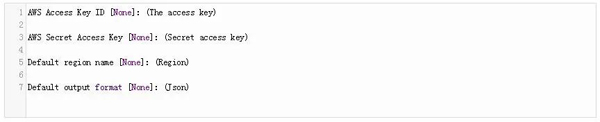
要從Amazon S3下載文件,你需要導入boto3和botocore。Boto3是一個Amazon SDK,它允許Python訪問Amazon web服務(如S3)。Botocore提供了與Amazon web服務進行交互的命令行服務。
Botocore自帶了awscli。要安裝boto3,請運行以下命令:

現在,導入這兩個模塊:

在從Amazon下載文件時,我們需要三個參數:
Bucket名稱
你需要下載的文件名稱
文件下載之后的名稱
初始化變量:

現在,我們初始化一個變量來使用會話的資源。為此,我們將調用boto3的resource()方法并傳入服務,即s3:

最后,使用download_file方法下載文件并傳入變量:

11.使用asyncio
asyncio模塊主要用于處理系統事件。它圍繞一個事件循環進行工作,該事件循環會等待事件發生,然后對該事件作出反應。這個反應可以是調用另一個函數。這個過程稱為事件處理。asyncio模塊使用協同程序進行事件處理。
要使用asyncio事件處理和協同功能,我們將導入asyncio模塊:

現在,像這樣定義asyncio協同方法:

關鍵字async表示這是一個原生asyncio協同程序。在協同程序的內部,我們有一個await關鍵字,它會返回一個特定的值。我們也可以使用return關鍵字。
現在,讓我們使用協同創建一段代碼來從網站下載一個文件:

在這段代碼中,我們創建了一個異步協同函數,它會下載我們的文件并返回一條消息。
然后,我們使用另一個異步協同程序調用main_func,它會等待URL并將所有URL組成一個隊列。asyncio的wait函數會等待協同程序完成。
現在,為了啟動協同程序,我們必須使用asyncio的get_event_loop()方法將協同程序放入事件循環中,最后,我們使用asyncio的run_until_complete()方法執行該事件循環。
“怎么使用Python進行下載”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





