溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹使用selenium怎么對圖片進行下載,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
1,先把包給導進來:
import requests from selenium.webdriver import Chrome,ChromeOptions import os
不知道怎么導包的看我的第一篇,附上鏈接:
https://www.jb51.net/article/204774.htm
#請求的url
url = 'http://pic.netbian.com/4kmeinv/'
#進行偽裝
headers = {
"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
#發起請求
response = requests.get(url=url,headers=headers)
#手動設定響應數據的編碼格式
response.encoding = 'utf-8'
page_text = response.text
#這個就是再后臺上面運行那個瀏覽器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
option.add_experimental_option('excludeSwitches',['enable-automation'])
#這里也要輸入
browser = Chrome(options=option)
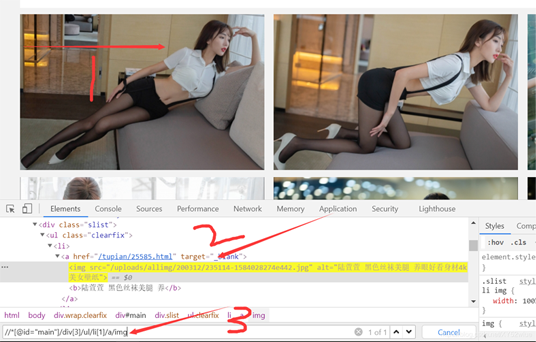
browser.get(url)相信看過我上篇的都知道這些,那就廢話不多說,定位元素:
先看下代碼再說:
li = browser.find_elements_by_xpath('//*[@id="main"]/div[3]/ul/li')老樣子,分為三步,第一步選中所選的圖片–>copy xpath–>ctrl+f -->粘貼進去可以看到是1of1,但明顯我們要的是這個頁面上所有的圖片,所以呀,只需要改一下就可以啦,將tr[1],里面的包括括號刪掉就可以。
這樣的話就是整個頁面內所有的圖片啦,

#創建一個文件夾
if not os.path.exists('./小美女圖'):
os.mkdir('./小美女圖')然后再循環一下就好啦:
for i in li:
img_src = i.find_element_by_xpath('./a/img').get_attribute('src')
img_name = i.find_element_by_xpath('./a/img').get_attribute('alt')+'.jpg'5,保存
img_data = requests.get(url=img_src,headers=headers).content img_path = '小美女圖/'+img_name with open(img_path,'wb') as fp: fp.write(img_data) print(img_name,'下載成功!!!')
關于使用selenium怎么對圖片進行下載就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





