溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何Kotlin協程用法淺析用在京東APP業務中實踐,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
協程定義及設計的目的:協程是一種并發設計模式,是一套由 Kotlin 提供的線程框架。開發者使用協程框架可以通過結構化并發機制在同一作用域下,把運行的不同線程的代碼寫在同一個代碼塊里并執行,簡化異步執行的代碼,使得我們的代碼顯得線性。用法淺析
本文基于kotlinx-coroutines-android V1.3.8版本協程庫進行講解。
使用協程前我們需要先了解幾個概念:
協程作用域 CoroutineScope:定義新協程的范圍,通過它的擴展函數可以創建、啟動協程,并可以管理協程,比如取消該作用域下的協程,Kotlin 協程為我們提供了一組內置的 Scope: MainScope:使用 Dispatchers.Main 調度器的作用域 LifecycleScope:與 Lifecycle 生命周期綁定 ViewModelScope:與 ViewModel 生命周期綁定 GlobalScope:生命周期貫穿全局
協程構建器:CoroutineScope 的擴展函數,用于構建協程,比如 launch,async;
協程上下文 CoroutineContext:一個左向鏈表的實現,Job、Dispatcher 調度器都可以是它的元素,CoroutineContext 有一個非常好的作用就是可以很方便的通過其獲取 Job、Dispatcher 調度器等數;
CoroutineStart啟動模式:DEFAULT:立即調度,可以在執行前被取消 LAZY:需要時才啟動,需要 start、join 等函數觸發才可進行調度 ATOMIC:立即調度,協程肯定會執行,執行前不可以被取消 UNDISPATCHED:立即在當前線程執行,直到遇到第一個掛起
Dispatchers調度器:DEFAULT:默認調度器,適合 CPU 密集型任務調度器,比如邏輯計算 Main:UI 線程調度器 Unconfined:對協程執行的線程不做限制,協程恢復時可以在任意線程 IO:IO調度器,適合 IO 密集型任務調度器 比如讀寫文件,網絡請求等
suspending lambda:一個可掛起的 lambda 表達式,它的全定義為 suspend CoroutineScope.() -> Unit,這是一個被 suspend 修飾符修飾的"CoroutineScope 擴展函數類型",作為擴展函數,它的優勢在于可以直接訪問 CoroutineScope 內的屬性;
suspension point 掛起點:一般對應掛起函數被調用的位置;
掛起函數:由 suspend 修飾的函數,掛起函數只能在掛起函數或者協程中調用;
開篇中概念章節中介紹了協程構建器用于協程的構建,協程的構建器是CoroutineScope的擴展函數。
coroutineScope.launch(Dispatchers.IO) { // 示例(1) // 運行在IO線程 } coroutineScope.launch(Dispatchers.Main) { // 示例(2) // 運行在UI線程 }在上述代碼中,演示了一個協程的創建,我們以實例(1)為例,它的含義是通過 coroutineScope 作用域的擴展函數 launch 創建了一個運行在IO線程的協程,大家可以看到代碼還是很清晰的,這時候就可以在協程中做一些耗時性的操作。同理實例(2)中創建了一個運行在UI線程的協程。
val job: Job = coroutineScope.launch(Dispatchers.IO, CoroutineStart.LAZY) { // 示例(1) // 運行在IO } job.start()在上述代碼中,我們將示例(1)進行了改造,調用 launch 函數時,新增了一個參數 CoroutineStart.LAZY,并將返回的 Job 對象賦值給變量 job。
默認情況下,協程的啟動模式為 CoroutineStart.DEFAULT,即協程創建完成之后會立即執行,示例中設置啟動模式為 CoroutineStart.LAZY,這時候 launch 函數創建了協程,并沒有啟動它,此時協程的啟動需要依靠 Job 的 start 等函數進行啟動。
Job 是一個具有生命周期的并且可以被取消的后臺工作或者說異步任務,Job 內提供了 isActive、isCompleted、isCancelled 屬性用以判斷協程的狀態,以及啟動協程 start()、取消協程 cancel() 等操作的 api。
假如現在有這個一個需求,存在兩個接口,一個用于獲取用戶個人信息、一個用于獲取企業信息,需要兩個接口數據都獲取到的時候才可以進行 UI 的刷新,這時候 async 并發就凸顯它的優勢;
coroutineScope.launch(Dispatchers.Main) { val async1 = async(Dispatchers.IO) { // 網絡請求1 "模擬用戶信息數據獲取" } val async2 = async(Dispatchers.IO) { // 網絡請求2 "模擬企業信息數據獲取" } handleData(async1.await(), async2.await()) // 模擬合并數據 }在上述代碼中通過 async 發起兩個協程獲取數據,并通過 await() 獲取到請求結果,因為并行發起,所以速度也是挺快的。
通過 async 創建的協程返回值是一個 Deferred,Deferred 帶有延遲的意思,可以通俗理解成要等一等才能拿到結果,Deferred 也是一個 Job,它是 Job 的一個子類,所以具有 Job 同樣的功能。
當然 async 默認的啟動模式和 launch 一樣,也是 CoroutineStart.DEFAULT 立即執行,當將啟動模式設置為 CoroutineStart.LAZY 時可以通過 await() 啟動協程,也可以通過 Job 的 start() 函數啟動。
在這一章節中,會通過幾個示例對比,來體現Kotlin協程的優勢在哪里,同時筆者建議閱讀此章節的時候不要太在意實現的細節,關注不同方式的實現風格就好。
/** 獲取用戶信息 */ private fun getUserInfo() { // 示例(1) apiService.getUserInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, re: Response<UserInfoEntry>) { runOnUiThread { tvName.text = response.body()?.userName } } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) } /** 獲取用戶信息 協程*/ private fun getUserInfoByCoroutine() { // 示例(2) coroutineScope.launch(Dispatchers.Main) { val userInfo = coroutineApiService.getUserInfo() tvName.text = userInfo.userName } }這是一個獲取用戶信息的網絡請求示例,通過普通的 CallBack 方式及 Kotlin協 程的方式分別實現。
示例(1)是比較常見的一個種方式,發起網絡請求,通過 CallBack 回調數據,最后切換主線程刷新 UI,很常見的寫法。
示例(2)是協程的實現方式,通過 scope 的擴展函數 launch 創建了一個運行在主線程的協程,協程的實現中,也是獲取數據后刷新 UI。
現在我們對比一下兩種方式的實現,看看協程的實現有什么優化的地方?首先在協程的實現中沒有了 CallBack 的回調,其次在刷新UI的時候并沒有切換到主線程的操作,最后代碼量也是比較簡潔的。
其實還好,第一種方式在我們在開發中,這種 CallBack 的回調,應該應用過無數次了,寫起來也是分分鐘的事情,并不會多么困難。確實,這樣 Kotlin 協程的優勢也不是那么明顯了。
接下來我們看一個復雜一些的場景,以上文講解 async 時提到過的合并用戶信息數據和企業信息數據為例,我們看看更詳細的實現,在這里復述一下場景:“存在兩個接口,一個用于獲取用戶個人信息、一個用于獲取企業信息,需要兩個接口數據都獲取到的時候才可以進行 UI 的刷新”。
/** 開始獲取數據 */ private fun start() { getUserInfo() getCompanyInfo() } /** 獲取用戶信息 */ private fun getUserInfo() { apiService.getUserInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, r: Response<UserInfoEntry>) { // 判斷是不是已經拿到公司信息了 // 刷新UI handle.post() } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) } /** 獲取公司信息 */ private fun getCompanyInfo() { apiService.getCompanyInfo().enqueue(object : Callback<UserInfoEntry> { override fun onResponse(c: Call<UserInfoEntry>, r: Response<UserInfoEntry>) { // 判斷是不是已經拿到用戶信息了 // 刷新UI handle.post() } override fun onFailure(call: Call<UserInfoEntry>, t: Throwable) { } }) }在這種方式中,我們將兩個接口請求封裝了兩個 API,同時發起網絡請求,相對使用上不能說不方便,關鍵在于數據的處理上,用戶信息的數據拿到之后需要判斷企業信息是不是也獲取到了,同理企業信息的數據也是一樣,現在只有兩組數據的合并,如果涉及更多信息類型數據的獲取,相應的邏輯處理就變的越來越復雜了。
當然如果改成串行的邏輯也是很好處理的,比如先獲取用戶信息數據,獲取之后再進行企業信息數據的讀取,但是這種方式犧牲了時間,本來可以并行的請求,變成串行,請求時間加長。
/** 獲取信息 kotlin協程 */ private fun getKotlinInfo() { coroutineScope.launch(Dispatchers.Main) { val userInfo = async { apiService.getUserInfo() } // 獲取用戶信息 val companyInfo = async { apiService.getCompanyInfo() } // 公司信息 MergeEntry(userInfo.await(), companyInfo.await()) } }這是 Kotlin 協程的實現方式,使用 CoroutineScope 的 async 構建器實現,在需要更多請求時,它的邏輯處理很方便,多一個請求多一個 async 即可,并行的請求節省時間,而且消除了回調,并且不需要切換線程。
在了解了協程的創建、啟動及優勢之后,現在有一個問題我們什么時候使用協程?當我們需要處理耗時數據的時候,這時候可以使用協程切換到子線程執行,當處理完數據需要刷新 UI 的時候可以使用協程切換到主線程,其實需要指定運行線程的時候就可以用協程處理。
coroutineScope.launch(Dispatchers.IO) { // 運行在IO線程 handleFileData() // 模擬讀文件耗時操作 launch(Dispatchers.Main) { // 數據處理完成刷新UI tvName.text = "" } }在上述代碼中,有一個耗時讀文件操作,所以這里使用了協程,通過 launch 切換到 IO 線程處理耗時操作,處理完成之后通過 launch 函數切到 Main 線程刷新 UI,好像沒毛病,我們繼續看下一段代碼。
coroutineScope.launch(Dispatchers.IO) {// 運行在IO線程 handleFileData() // 模擬讀文件 launch(Dispatchers.Main) { // 數據處理完成刷新UI launch(Dispatchers.IO) { // 處理數據 launch(Dispatchers.Main) { // 數據處理完成刷新UI launch(Dispatchers.IO) { launch(Dispatchers.Main) { launch(Dispatchers.IO) { launch(Dispatchers.Main) { } } } } } } } }這個示例演示的場景比較極端,很少在開發中會遇到 IO 與 Main 線程切換如此頻繁,在這里只是為了暴露問題。前面我們說過 Kolin 協程消除了回調,但在這個示例中卻表現的很回調,層層嵌套。
因為單單使用 launch、async 協程構建器函數并不能很好的處理這種復雜的需要頻繁切換線程的場景,為了解決示例中的問題,Kotlin 協程為我們提供了一些另外的函數來配合使用, 比如 withContext 掛起函數。
withContext 是 Kotlin 協程提供的掛起函數,它提供給的功能有:
可以切換到指定的線程運行;
函數體執行完之后,自動切回原來的線程。
coroutineScope.launch(Dispatchers.Main) { // 在主線程開啟一個協程 val data = withContext(Dispatchers.IO) { // 切到IO線程處理耗時操作 handleFileData() // 在IO線程運行 } tvName.text = data // withContext函數體執行完,自定切換到主線程刷新UI } coroutineScope.launch(Dispatchers.Main) { withContext(Dispatchers.IO) { // **操作(1)** // 切換IO線程 // ... 在IO線程執行 } // .. 在UI線程執行 **操作(2)** withContext(Dispatchers.IO) { // 切換IO線程 // ... 在IO線程執行 } // .. 在UI線程執行 withContext(Dispatchers.IO) { // 切換IO線程 // ... 在IO線程執行 } // .. 在UI線程執行 // ...等等... }使用 withContext 改造之后,消除了嵌套,代碼變得清晰,所以,Kotlin 協程除了 launch 等擴展函數之外,還需要 withContext 等掛起函數,才可體現它的優勢。
這里有必要提一下,在沒有使用協程的時候,開啟一個線程,代碼就會出現兩個分支,比如上述代碼中的操作(1),切到了IO線程執行,這是一個分支,緊接著是執行操作(2),這是另一個分支,這兩個分支各走各的,“幾乎同步執行”;
但在協程中,操作(1)使用withContext掛起函數切換到IO線程去執行它的操作后,并不會執行操作(2),而是等待操作(1)的withContext執行完成之后,切換線程回到Main線程中時,操作(2)才會執行,后續的supend章節會有講解。

public suspend fun <T> withContext( context: CoroutineContext, block: suspend CoroutineScope.() -> T ): T {}在上面的示例中 getData() 是一個普通的函數,在其中調用的 withContext 掛起函數時,提示報錯信息:suspend function 'withContext' should be called only from a coroutine or another supend function,意思是說 withContext 是一個被 suspend 修飾的函數,它應該在協程或者另一個 spspend 函數中調用。源碼中 withContext 被 suspend 修飾。
suspend 是 Kotlin 協程的一個關鍵字,由 suspend 修飾的函數為掛起函數,掛起函數只能在協程或者另一個掛起函數中調用。
從開發者的層面說,suspend 關鍵字的作用就是一個提醒的作用,提醒什么?提醒函數的調用者,這是一個掛起函數,內部存在耗時操作,需要在協程或者另一個掛起函數中調用才行;
但從編譯過程來說,被 suspend 修飾的函數,有特殊的解讀,比如會新增一個參數 Continuation,這也是為什么在普通函數中無法調用掛起函數的原因。
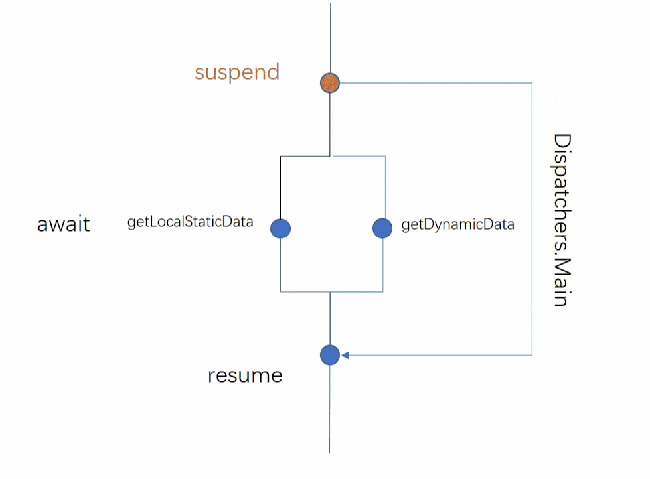
剛才我們說被 suspend 修飾的函數是掛起函數,掛起從字面意思可以理解為不執行了或者說是暫停了,這里有一個疑問,掛起的是誰?是線程?函數?還是協程?
其實掛起的是協程,可以理解為在協程中執行到 suspend 掛起函數的時候,就會暫停協程后續代碼的執行,我們分析一下下面代碼的執行流程。
coroutineScope.launch(Dispatchers.Main) { // 在主線程開啟一個協程 (1) val data = withContext(Dispatchers.IO) { // 切到IO線程處理耗時操作 (2) handleFileData() // 在IO線程運行 (3) } tvName.text = data // withContext函數體執行完,自定切換到主線程刷新UI (4) }通過 CoroutineScope 的擴展函數 launch 啟動了一個運行在 Main 線程的協程,當協程執行到 withContext 掛起函數的時候,withCotext 切到的 IO 線程,執行自身函數體的耗時操作,同時協程后續的代碼就會暫停執行,這里也是協程最神奇的地方。
那么后續的代碼什么時候執行?協程掛起了,對應的也有恢復的操作,這里就涉及協程的恢復了,當 withContext 掛起函數執行完成之后,協程會重新切回原來的線程(如果掛起前的線程是一個子線程,有可能會因為線程空閑而被回收,切回來的線程并不一定百分百是原來的線程)繼續執行剩余的代碼,比如示例中刷新UI的操作。
總結一下 Kotlin 協程掛起的概念,什么是掛起?可以理解為兩個操作:
協程被“暫停”執行;
協程被“恢復”執行。
另外說一下掛起的非阻塞式:
還是以上面的代碼為例,操作(1)在 Main 線程中啟動了一個協程,協程執行到操作(2)時,切到 IO 線程中執行操作(3),此時操作(4)被暫停,不執行了,但 Main 線程被阻塞了嗎?并沒有,主線程該干嘛就干嘛去了,這就是掛起的非阻塞式,雖然被掛起了,但掛起的是自己,是協程,并沒有阻塞原來的線程。
本文以核心樓層數據處理進行講解,該業務需要將兜底數據和接口下發的動態數據進行組裝,最終整合成業務所需的數據源。
dependencies { implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.3.8' }/** 協程作用域 */ private val scope = MainScope() private fun assembleDataList(response: PlatformResponse?) = scope.launch( CoroutineExceptionHandler { _, exception -> /** 未捕獲的異常處理 */ }) { val localStaticData: Deferred<MutableList<BaseTemplateEntity>?> = async(start = CoroutineStart.LAZY) { getLocalStaticData() } val dynamicData: Deferred<MutableList<BaseTemplateEntity>?> = async(start = CoroutineStart.LAZY) { getDynamicData(response) } getAssembleDataListFunc(localStaticData.await(), dynamicData.await()) }我們通過作用域構建器擴展函數 launch 在當前的 MainScope 下創建新的協程并啟動,在 launch 函數的 lambda 表達式中,我們使用了 async 函數并聲明 start 參數設置為 CoroutineStart.LAZY 惰性模式創建一個子協程(但該協程并不會立即執行),該函數會返回一個 Deferred 對象,Deferred 是帶有返回值的 Job 擴展(類似于 Java 中的 Futuer 對象),只有當我們主動調用 Deferred 的 await 或 start 函數時,該子協程才會真正執行。
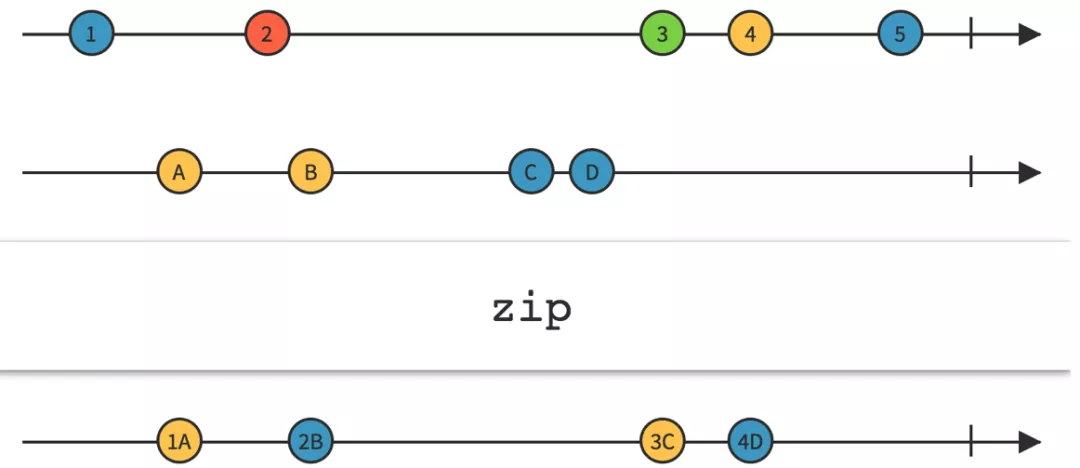
private void assembleDataList(PlatformResponse response) { Observable<List<BaseTemplateEntity>> localStaticData = getLocalStaticData(); Observable<List<BaseTemplateEntity>> assembleData = getDynamicData(response); Func2<List<BaseTemplateEntity>, List<BaseTemplateEntity>, List<BaseTemplateEntity>> assembleData = getAssembleDataListFunc(); Observable<List<BaseTemplateEntity>> observable = Observable.zip(localStaticData, assembleData, assembleData); subscribe(observable, callback); }通過實現代碼可以看出,我們使用 zip 操作符,將 localStaticData 和 assembleData 這兩個觀察者發送的事件序列,在組合后生成一個新的事件序列并發送(此處我們不討論 localStaticData 和 assembleData 這兩個事件序列是串行還是并行執行)。
zip操作符事件流向圖(圖片來自ReactiveX官網)
對比 針對我們的業務場景,協程和 RxJava 實現方式都能滿足我們的需求,那他們之前有什么區別呢:我們先來說一說 RxJava 的優點:解決了 Java 異步實現回調嵌套問題,提高了代碼的可讀性及維護性;鏈式調用將事件的配置階段、運行階段、訂閱階段的調用變得扁平化;線程調度使得切換線程輕松又優雅。RxJava 的缺點:
Observable firstObservable = Observable.create(new Observable.OnSubscribe<CacheBean>() { @Override public void call(Subscriber<? super CacheBean> subscriber) { if (subscriber != null && !subscriber.isUnsubscribed()) { subscriber.onNext(handleCacheBean()); subscriber.onCompleted(); RxUtil.unSubscribeSafely(subscriber); } } }); Observable secondObservable = Observable.just(new CacheBean(null, "0")); firstObservable.timeout(TIME_OUT, TimeUnit.SECONDS) .onErrorResumeNext(secondObservable) .subscribe();RxJava 的行為并不可預期,太容易出錯。如上所示示例中,如果 firstObservable 運行時超時并不會結束 firstObservable 的序列繼續發射,如果不調用其 onCompleted() 事件,你會發現訂閱事件會先后有接收到2次不同的事件序列,而非我們希望的當超時后只訂閱到 secondObservable 發射的事件序列。
RxJava 門檻太高。大部分開發者可能不會過多深入研究,但是如果不了解這些,那么而幾乎可以說不可能融會貫通 RxJava 的一些概念,這也就增加了學習成本及維護成本。
背壓策略難以理解。
堆棧日志可讀性差,增加開發調試成本。
協程的優點:用同步的方式寫異步執行的代碼,使得代碼邏輯更加簡潔和清晰;輕量級,占用更少的系統資源;執行效率高;掛起函數較于實現 Runnable 或 Callable 接口更加方便可控;線程切換很簡單。協程的缺點:有一定學習成本,由于是基于 Kotlin 語言,需有一定語言基礎。
經過協程和 RxJava 的對比,我們也對各框架有所了解,但談到應該如何選擇這個話題,筆者以為如果你已經對 RxJava 重度使用,其實沒必要刻意遷移到協程,RxJava 功能強大目前仍是很流行的異步編程框架,基于 RxJava 的拓展庫 RxKotlin 也可以滿足在 kotlin 語言環境下使用 RxJava 開發。如果你已經有一定 Kotlin 開發經驗,又喜歡嘗試新鮮事物,協程是個不錯的選擇,其非阻塞時的掛起可以讓開發人員用同步的風格編寫異步代碼,提高開發效率同時也降低了維護成本。協程的概念越來越普及,尤其已在 Flutter 跨平臺框架中廣泛使用,勢必會成為趨勢。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





